


AI Research Roundup 24.10.24
Claude's Computer Use, o1's planning abilities, barriers of LLMs in planning, CrossEval, inference scaling for RAG with DRAG and IterDRAG.


Introduction
This week, our Research Roundup shares papers on Claude’s Computer Use, assessing LLM planning, cross-capabilities in LLMs, and improved RAG using inference scaling:
Claude’s Computer Use
On The Planning Abilities of OpenAI's o1 Models
Revealing the Barriers of Language Agents in Planning
CrossEval: Law of the Weakest Link and Cross Capabilities of LLMs
Inference Scaling for Long-Context Retrieval Augmented Generation
Claude’s Computer Use
As we discussed in “Anthropic Claude Update Adds Computer Use,” this week Anthropic announced an updated Claude 3.5 Sonnet, a new Claude 3.5 Haiku and Computer Use, which gives Claude 3.5 Sonnet capabilities to interact with computer interfaces and control actions on a computer.
How does Computer Use work under the hood? Anthropic hasn’t released technical details, but they did share a blog post “Developing a computer use model.”
The technical implementation of Computer Use relies on Claude's ability to interpret screenshots and calculate precise pixel coordinates for cursor movement and clicks. They trained the model on basic applications like calculators and text editors and were surprised that it generalized remarkably well:
When a developer tasks Claude with using a piece of computer software and gives it the necessary access, Claude looks at screenshots of what’s visible to the user, then counts how many pixels vertically or horizontally it needs to move a cursor in order to click in the correct place. Training Claude to count pixels accurately was critical.
They rely heavily on precise image understanding, and one challenge was developing a "flipbook" approach to screen interpretation through sequential screenshots. The model can self-correct when encountering obstacles and execute complex multi-step tasks based on written prompts.
While Sonnet with Computer Use achieves state-of-the-art performance on the OSWorld benchmark at 14.9% (compared to human performance of 70-75%), it is slow, unreliable and chews up many tokens, making it costly. The system currently has limitations in handling dynamic interface elements and complex gestures like dragging or zooming.
They described their efforts on AI safety for this feature in depth and stated the system operates without training on user-submitted data, including received screenshots. Future development will focus on improving speed, reliability, and expanding the range of supported interactions while maintaining appropriate safety measures.
While several AI agents have implemented a form of computer use, Claude is the first LLM to integrate it into an LLM. This is just a start. Hopefully, Computer Use will soon be implemented in an open LLM, and its technical details will be openly shared.
On The Planning Abilities of OpenAI's o1
As LLMs have improved on reasoning, there has been interest in using these AI models to help with complex planning tasks. The paper On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability evaluates the planning capabilities of OpenAI's o1 models directly, to see if its robust reasoning capabilities translates into planning performance.
The o1 model was evaluated on benchmark tasks focusing on three key aspects of planning: feasibility (understanding the problem and generating a feasible plan), optimality (developing the most efficient plan), and generalizability (planning across a diverse range of scenarios). The six benchmark tasks ranged from constraint-heavy tasks (Barman, Tyreworld) to spatially complex environments (Termes, Floortile).
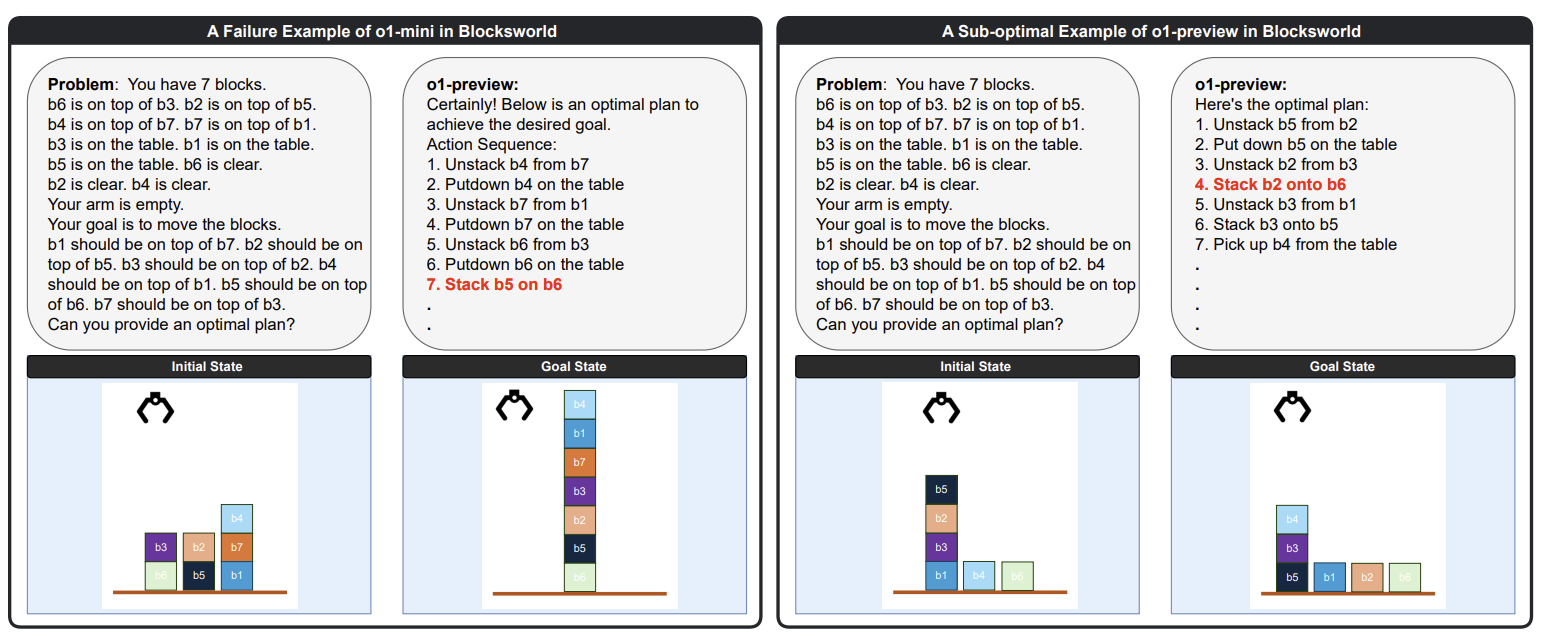
The evaluation highlighted o1-preview's strengths in self-evaluation and constraint-following, while also identifying bottlenecks in decision-making and memory management, particularly in tasks requiring robust spatial reasoning:
Our results reveal that o1-preview outperforms GPT-4 in adhering to task constraints and managing state transitions in structured environments. However, the model often generates suboptimal solutions with redundant actions and struggles to generalize effectively in spatially complex tasks.

The bottom line: OpenAI’s o1 model, in particular o1-preview, shows major advances and is state-of-the-art in planning, but it remains challenged in this area, particularly in terms of optimizing plans and generalizing to more abstract tasks.
Revealing the Barriers of Language Agents in Planning
LLMs have reignited interest in autonomous planning by automatically generating reasonable solutions for given tasks, but LLMs still lack human-level planning abilities, with even OpenAI’s o1 model achieving only 15.6% on one of the complex real-world planning benchmarks.
The paper Revealing the Barriers of Language Agents in Planning investigates the challenges LLMs face in planning tasks, and asks: What hinders language agents from achieving human-level planning capabilities?
To answer this question, the authors analyze factors in planning using a method called Permutation Feature Importance, which scores attributions in prompts to actions, constraints, and questions on tested LLMs - Qwen2-7B, Llama3.1-8B, and Llama3.1-70B. Their studies revealed that LLMs struggle to adequately reference constraints during planning and tend to lose focus on the goal as the plan length increases.
The study also examines the impact of episodic and parametric memory updating strategies on LLM performance. Episodic memory updating, which involves refining or reiterating existing insights, is found to improve constraint understanding but relies on global understanding rather than fine-grained referencing. Parametric memory updating, achieved through fine-tuning, enhances the question's impact on the final plan but does not fully address the issue of diminishing influence over longer horizons.
The authors conclude that these strategies resemble “shortcut learning” that only helps on short-horizon and low-level planning:
While both strategies improve the impact of constraints and questions in planning, they only mitigate the underlying issues rather than fully resolve them.
For LLMs to overcome their current weaknesses on planning, they will need to better consider and integrate constraints and maintain focus and foresight over long horizon planning tasks. There’s a lot of room to improve.
CrossEval: Law of the Weakest Link and Cross Capabilities of LLMs
LLM benchmarks are typically focused on individual capabilities, but most complex real-world tasks require multiple different abilities to complete. Sometimes, we need a Swiss army knife to do the job. The authors of Law of the Weakest Link: Cross Capabilities of Large Language Models call this concept “cross capabilities,” and they develop a benchmark to evaluate AI models on cross capabilities called CrossEval.
They first define seven core individual capabilities - English, Reasoning, Coding, Image Recognition, Tool Use, Long Context, and one representative of multilingual capabilities, Spanish - and then pair them to form seven common cross capabilities. Some example cross capabilities:
Coding & Reasoning: Coding Q&A (Text to Text) (5), Code Explanation (2), Programming Assistant (5), Mathematical Calculation (7).
Image Recognition & Reasoning: Diagram Understanding (3), Chart Understanding (3), Text-Rich Understanding (2), and Visual Math and Science (2).
Tool Use & Coding: Code Execution (3), Code Debugging with Execution (2), Programming Assistant with Execution (1), and Code Execution with File Uploads (3)
Tool Use & Reasoning: Mathematical Reasoning (2), Scientific Reasoning (15), and Mathematical Calculation (13).
Long Context & Coding: Repository-Level Code Generation (5), Repository-Level Code Understanding (2), Repository-Level Code Debugging (1), Log Analysis (3), and API Docs Understanding (2).
The CrossEval benchmark comprises 1400 human-annotated prompts spanning seven core individual capabilities and seven common cross-capabilities, each with a detailed taxonomy. The evaluation process involves expert human annotators rating model responses on a 1-5 Likert scale.
CrossEval was used to evaluate leading LLMs:
Our findings reveal that, in both static evaluations and attempts to enhance specific abilities, current LLMs consistently exhibit the "Law of the Weakest Link," where cross-capability performance is significantly constrained by the weakest component. Specifically, across 58 cross-capability scores from 17 models, 38 scores are lower than all individual capabilities, while 20 fall between strong and weak, but closer to the weaker ability.

The results from CrossEval indicate many challenges for LLMs in cross-capability tasks. Improving LLMs on real-world tasks requires identifying and improving LLMs where they are weakest.
Inference Scaling for Long-Context Retrieval Augmented Generation
The paper Inference Scaling for Long-Context Retrieval Augmented Generation from Google DeepMind investigates how to scale inference computation for Retrieval Augmented Generation (RAG) based on long-context LLMs.
The paper introduces two strategies: Demonstration-based RAG (DRAG) and iterative demonstration-based RAG (IterDRAG). DRAG provides multiple RAG examples as demonstrations for in-context learning, while IterDRAG learns to decompose complex queries into sub-queries and answers them through interleaved retrieval and generation. The authors note:
“These strategies provide additional flexibility to scale test-time computation (e.g., by increasing retrieved documents or generation steps), thereby enhancing LLMs' ability to effectively acquire and utilize contextual information.”
The authors demonstrate that scaling inference computation leads to near-linear performance gains when optimally allocated, a relationship they call the inference scaling laws for RAG.

They further develop a computation allocation model to predict the optimal allocation of test-time compute resources, such as the number of retrieved documents and generation steps, for a given budget. This model accurately estimates the optimal inference parameters under various computation constraints. By applying these optimal configurations, scaling inference compute on long-context LLMs achieves up to 58.9% gains on benchmark datasets compared to standard RAG.

Improved RAG methods beyond simple RAG - such as multi-step RAG, reranking, and GraphRAG - have been developed to further improve LLM performance on knowledge-based tasks. DRAG and IterDRAG take RAG to the next level, scaling the decomposition and demonstration of the RAG request and yielding a scaling law for these operations. The authors conclude:
These insights provide a strong foundation for future research in optimizing inference strategies for long-context RAG.