


AI Research Roundup 24.11.21
Progress in multi-modality and open AI: LLaVA-o1, Mixture-of-Transformers, LLaMA-Mesh, MagicQuill, OpenCoder, RedPajama.


Introduction
Our AI Research Roundup for this week covers topics related to multi-modality and open AI models, including multi-modal LLM reasoning and architectures, 3D mesh generation with LLMs, image editing with AI, an open cookbook for training code LLMs, and the RedPajama open dataset:
LLaVA-o1: Let Vision Language Models Reason Step-by-Step
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models
MagicQuill: An Intelligent Interactive Image Editing System
OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
RedPajama: an Open Dataset for Training Large Language Models
LLaVA-o1: Let Vision Language Models Reason Step-by-Step
While there has been great progress on improving reasoning for (text-based) LLMs, current Vision-Language Models (VLMs) and multi-modal LLMs often struggle to perform complex and structured reasoning on visual question-answering tasks. The paper LLaVA-o1: Let Vision Language Models Reason Step-by-Step aims to close that gap and give VLMs multi-stage visual reasoning capabilities, with LLaVA-o1.
LLaVA-o1 is trained by fine-tuning from the Llama-3.2-11B-Vision-Instruct model using the LLaVA-o1-100k dataset. The dataset consists of 100,000 image question-answer (QA) pairs, derived from various general VQA datasets and science-targeted VQA datasets, and includes structured reasoning annotations generated by GPT-4o.
LLaVA-o1 exhibits its enhanced reasoning capabilities by generating output in a four-step process - summary, caption, reasoning, and conclusion:
LLaVA-o1 independently engages in sequential stages of summarization, visual interpretation, logical reasoning, and conclusion generation. This structured approach enables LLaVA-o1 to achieve marked improvements in precision on reasoning-intensive tasks.
Further, LLaVA-o1 uses stage-level beam search, which is inference-time scalable, so that increased computation can be applied to improve performance on more complex tasks. In benchmark evaluations, LLaVA-01 exhibits SOTA reasoning performance on visual QA tasks:
Remarkably, with only 100k training samples and a simple yet effective inference time scaling method, LLaVA-o1 not only outperforms its base model by 8.9% on a wide range of multimodal reasoning benchmarks, but also surpasses the performance of larger and even closed-source models, such as Gemini-1.5-pro, GPT-4o-mini, and Llama-3.2-90B-Vision-Instruct.
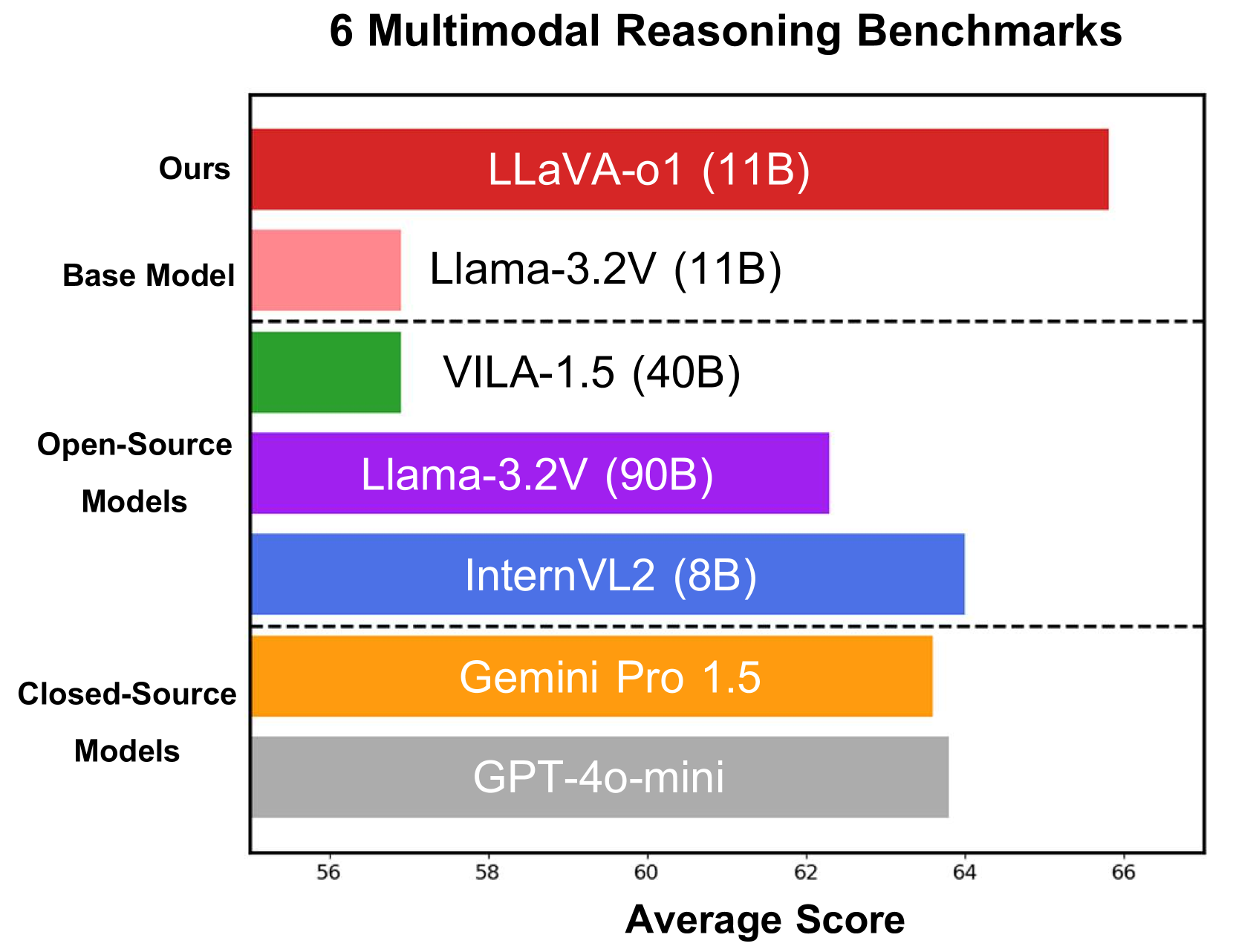
LLaVa-o1 shows the value of combining fine-tuning, test-time compute scaling, and structured chain-of-thought inference response in improving visual reasoning in multi-modal LLMs. This pushes the frontiers of reasoning in multi-modal LLMs.
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
As LLMs have advanced in performance, parameter count and multi-modal capabilities, the challenge of efficiently training these models has become more acute. The paper from Meta FAIR proposes Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models to reduce the cost of training multi-modal LLMs.
The Mixture-of-Transformers (MoT) is a sparse multi-modal transformer architecture that can process interleaved inputs of text, images, and speech; it handles different modalities in the same input and output stream. MoT decouples non-embedding parameters (feed-forward networks, attention matrices, layer normalization) by modality, separating out text, image, and speech:
For each input token, MoT activates modality-specific weights (including feed-forward networks, attention projection matrices, and layer normalization), then applies self-attention across the entire sequence.
This approach relies on the observation that even in dense multimodal transformer architectures, tokens of different modality are processed in different feature spaces. Separating by modalities into a sparse architecture makes training more efficient.

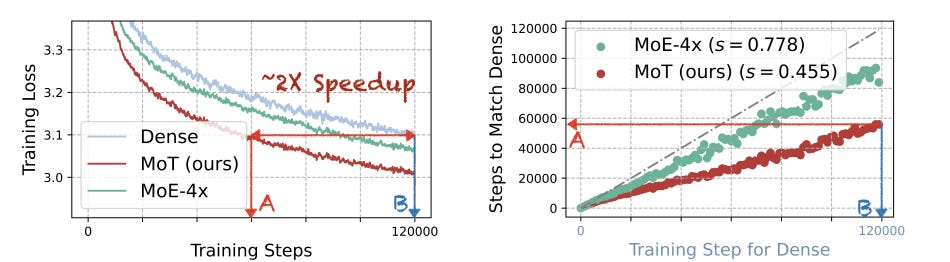
Evaluations across various settings and model sizes up to 7B parameters demonstrate MoT is faster and more efficient, able to match a dense baseline's performance with far less training FLOPs.
In the Chameleon 7B setting (autoregressive text-and-image generation), MoT matches the dense baseline's performance using only 55.8% of the FLOPs. When extended to include speech, MoT reaches speech performance comparable to the dense baseline with only 37.2% of the FLOPs. In the Transfusion setting, where text and image are trained with different objectives, a 7B MoT model matches the image modality performance of the dense baseline with one third of the FLOPs, and a 760M MoT model outperforms a 1.4B dense baseline across key image generation metrics.
Combining MoT with mixture-of-experts architecture demonstrated further performance gains, particularly in text generation. Overall, MoT presents a promising architectural approach for efficient and scalable multi-modal LLMs.
LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models
We have been able to incorporate visual understanding in LLMs by representing images as tokens; the tokenized mapping gives LLMs visual understanding. Now, the paper LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models applies this to 3D representations, by tokenizing 3D meshes.
A key challenge in integrating 3D mesh generation with LLMs lies in effectively tokenizing mesh data. LLaMA-Mesh addresses this by representing 3D meshes as plain text using the OBJ file format, which describes vertex coordinates and face definitions. The plain text ODJ format avoids modifying the LLM's tokenizer or adding to the vocabulary, minimizing training overhead. To further improve efficiency, vertex coordinates are quantized.

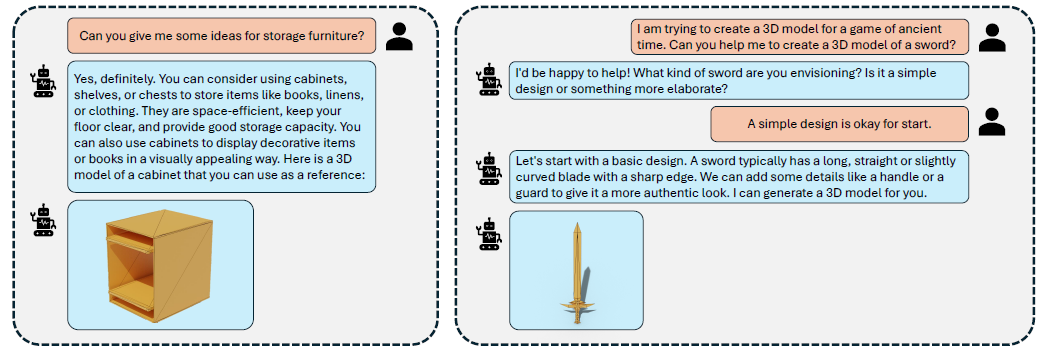
The authors train LLaMA-Mesh by fine-tuning a pre-trained LLaMA-3.1-8B-Instruct model on a supervised fine-tuning (SFT) dataset comprising text-3D pairs and dialogues:
We construct a supervised fine-tuning (SFT) dataset enabling pretrained LLMs to (1) generate 3D meshes from text prompts, (2) produce interleaved text and 3D mesh outputs as required, and (3) understand and interpret 3D meshes.
The fine-tuned LLaMA-Mesh model demonstrates the ability to generate 3D meshes from textual descriptions, participate in conversational mesh generation and interpretation, and maintain strong text generation performance. The model can generate high-quality, diverse meshes with artist-like topology.
While the method has limitations, including quantization-induced detail loss and context length constraints, it advances the unification of 3D and text modalities within a single LLM framework and opens possibilities for interactive 3D content creation.
MagicQuill: An Intelligent Interactive Image Editing System
Presented in MagicQuill: An Intelligent Interactive Image Editing System, MagicQuill is an interactive system for precise image editing built on an AI framework. Like other image editing features found in AI image tools, like inpainting, it combines the power of AI image generation with precise editing capabilities.
Users interact with MagicQuill via three brushstrokes: add, subtract, and color. MagicQuill leverages diffusion models and a multi-modal LLM for intuitive and precise image manipulation. These inputs are interpreted by the multi-modal LLM dynamically predicting user intent and suggesting contextual prompts, eliminating the need for manual prompt entry.

MagicQuill offers a streamlined, efficient, and precise image editing experience by integrating advanced AI techniques with an intuitive user interface. Experimental results demonstrate the effectiveness of MagicQuill in achieving high-quality image edits. MagicQuill is available to try out at this URL.
OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
OpenCoder is an open and reproducible coding LLM family of 1.5B and 8B base and chat models, trained from scratch on 2.5 trillion tokens composed of 90% raw code and 10% code-related web data.
Developed by AI researchers from INF, a Chinese AI company, and other institutions, and they published their work in OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models to accelerate research and foster reproducibility in code AI.
OpenCoder provides not only model weights and inference code but also the training data, data processing pipeline, ablation study results, and training protocols in an “open cookbook.”
Through this comprehensive release, we identify the key ingredients for building a top-tier code LLM: (1) code optimized heuristic rules for data cleaning and methods for data deduplication, (2) recall of text corpus related to code and (3) high-quality synthetic data in both annealing and supervised fine-tuning stages.
Evaluation across coding benchmarks like HumanEval, MBPP, and BigCodeBench demonstrates OpenCoder’s strong code completion and generation capabilities across diverse programming languages.
More importantly, the comprehensive release of OpenCoder’s development materials establishes a valuable resource for future research and development of coding AI models.

RedPajama: an Open Dataset for Training Large Language Models
In 2023, Together AI pioneered the release of open LLM training datasets, by releasing RedPajama and its follow-up, RedPajama V2, a massive open dataset (the largest so far). The paper RedPajama: an Open Dataset for Training Large Language Models, to be presented soon at 2024 NeurIPS, covers the releases of RedPajama and RedPajama V2 and their technical details.
The original RedPajama dataset is a replication of data used to train the LLaMA v1 models: Common Crawl, C4, GitHub, Wikipedia, Books, ArXiv, and Stack Exchange. RedPajama V2, a massive web-only dataset of over 100 trillion tokens, spans multiple languages and includes raw, unfiltered text data alongside extensive metadata (46 quality signals) enabling flexible filtering and curation.
As we explored in our article “Data Is All You Need,” high-quality and large quantity data is necessary to train high-performance LLMs, and therefore open datasets are crucial for keeping open source LLMs at the cutting edge. The RedPajama dataset has been instrumental in the development of many open LLMs, such as Snowflake Arctic, Salesforce's XGen and AI2's OLMo. The release of RedPajama has also supported and influenced the development of other open datasets and data refinements.
