


AI Research Roundup 24.11.28
GUI Agents with OS Atlas, Claude 3.5 Computer Use study, ShowUI, Marco-o1, Qwen with Questions (QwQ), The o1 replication journey and distillation of reasoning.


Introduction
This week’s Research Roundup covers developments in GUI Agents and o1-like reasoning models:
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
The Dawn of GUI Agent: A Case Study with Claude 3.5 Computer Use
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions
Qwen QwQ-32B-Preview
The O1 Replication Journey - distilling reasoning
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
A GUI agent is an AI agent that automatically performs complex tasks on the computer, analyzing computer screens, interpreting GUIs, and performing actions via the GUI to accomplish tasks. A GUI agent needs to both understand GUIs and take actions on them, transforming natural language instructions into executable actions such as mouse clicks in an interface.
To support GUI agents, Vision-Language Models (VLMs) are needed to interpret and understand the state of the interface. Current open-source VLMs lag behind commercial counterparts, so most GUI agents heavily rely on commercial VLMs, such as GPT-4o and GeminiProVision. The paper OS-ATLAS: A Foundation Action Model for Generalist GUI Agents presents a foundational open-source GUI action model designed to address limitations in existing open-source VLMs for GUI interaction.
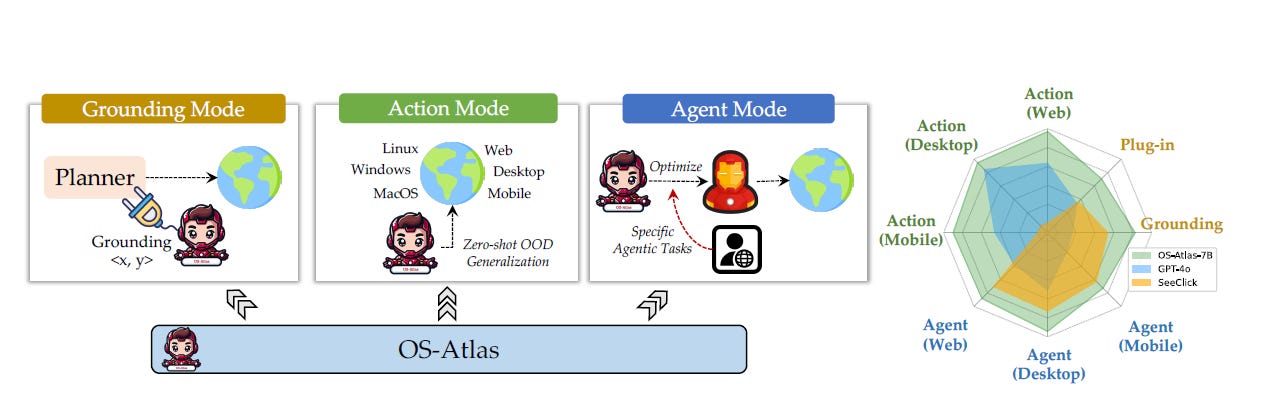
The authors of OS-Atlas tackle this by innovating in both data and modeling. First, they developed a cross-platform GUI grounding data synthesis toolkit, then used it to generate a corpus of over 13 million GUI elements across Windows, Linux, MacOS, Android, and web platforms—the largest open-source cross-platform GUI grounding corpus to date.
This dataset, combined with novel model training techniques addressing action naming conflicts across platforms (e.g., unifying "tap" and "click"), enables OS-Atlas to understand GUI screenshots and generalize to unseen interfaces.

OS-Atlas operates in three modes: Grounding (predicting element coordinates), Action (solving step-level tasks), and Agent (fine-tuned for specific tasks). Evaluated across six benchmarks spanning three platforms, OS-Atlas significantly outperforms prior state-of-the-art models, demonstrating superior performance in both zero-shot OOD scenarios and supervised fine-tuning settings. OS-Atlas provides a strong open-source alternative to commercial VLMs for GUI agent development.
The Dawn of GUI Agent: A Case Study with Claude 3.5 Computer Use
In October, Claude 3.5 added Computer Use as a feature. Claude’s Computer Use stands out as the first frontier AI model to offer GUI agent capabilities via API calls. Moreover, Claude 3.5 Computer Use operates end-to-end from natural language instructions, interpretating GUI state from screenshots, and navigating computer applications “the way people do—by looking at a screen, moving a cursor, clicking buttons, and typing text.”
The Dawn of GUI Agent: A Preliminary Case Study with Claude 3.5 Computer Use is a case study that examines what Claude 3.5 Computer Use can really do.
The study rigorously evaluates Claude 3.5 across three dimensions: Planning (generating executable plans), Action (accurate GUI interaction), and Critic (environmental awareness and adaptation). Twenty tasks across diverse domains (web search, workflow, office productivity, and video games) were tested:
Observations from these cases demonstrate Claude 3.5 Computer Use's unprecedented ability in end-to-end language to desktop actions.
While Claude 3.5 demonstrated impressive end-to-end capabilities, successfully completing many complex multi-step tasks involving multiple applications, limitations were also identified. Failures often stemmed from planning errors (incorrect plan generation), action errors (inaccurate GUI interactions, particularly with scrolling and precise selection), and critic errors (incorrect assessment of task completion).

To support the evaluation, the authors create a cross-platform framework, “Computer Use OOTB,” (out-of-the-box) deployment of Claude's Computer Use APIs on Windows and macOS. Computer Use OOTB and test cases for the evaluation were published on their Project Page.
In summary, this study evaluated Claude 3.5 Computer Use, finding both capabilities and limitations. In the process, they developed testcases and a framework that could facilitate future benchmarking and research on GUI agents and action models.
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
While prior GUI agents have usually relied on language-based understanding of web information and closed-source APIs and text-rich metadata, this has limitations compared to how humans can interact with GUI interfaces. This has led to GUI agents, such as Claude 3.5 Computer Use mentioned above, that interpret GUI state solely via visual cues.
The paper ShowUI: One Vision-Language-Action Model for GUI Visual Agent presents a vision-language-action (VLA) model based on directly processing screenshots. ShowUI is a lightweight (2B parameter) VLA model for GUI agents that features the following innovations:
(i) UI-Guided Visual Token Selection to reduce computational costs by formulating screenshots as an UI connected graph, adaptively identifying their redundant relationship and serve as the criteria for token selection during self-attention blocks.
(ii) Interleaved Vision-Language-Action Streaming that flexibly unifies diverse needs within GUI tasks, enabling effective management of visual-action history in navigation or pairing multi-turn query-action sequences per screenshot to enhance training efficiency.
(iii) Small-scale High-quality GUI Instruction-following Datasets by careful data curation and employing a resampling strategy to address significant data type imbalances.
ShowUI is trained by building upon Qwen2-VL-2B vision model, and fine-tuning for UI screen vision and actions with their curated instruction-following 256K dataset. Building UI-guided visual token selection reduces visual token redundancy by 33% during training, achieving a 1.4-times speedup.

ShowUI achieves state-of-the-art 75% zero-shot accuracy in screenshot grounding on the Screenspot benchmark and demonstrates competitive navigation performance across various environments, despite its relatively small size. The ShowUI model is available to try out on HuggingFace and datasets and collateral is shared via the GitHub project page.
ShowUI, OS-Atlas and Claude 3.5 Computer use share the common approach of grounding GUI agents based solely on visual interpretation of the GUI. This approach requires developing high-quality vision-language-action models to support better GUI agents, so we can expect further innovations in this area.
Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions
With the development of OpenAI’s o1 model, there has been a race to develop what some are calling large reasoning models (LRM), LLMs that are training specifically to perform in-depth reasoning by using additional inference tokens in a chain-of-thought process. DeepSeek revealed DeepSeek-R1-Lite-preview and Alibaba has had two separate teams develop reasoning models.
The Alibaba International Digital Commerce team developed Marco-o1, a large reasoning model (LRM) inspired by OpenAI's o1 and presented in Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions:
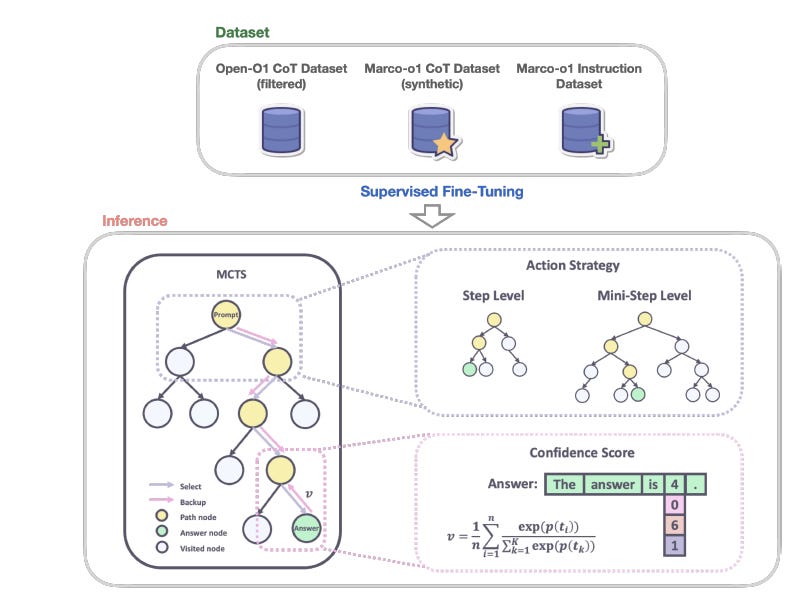
Marco-o1 is based on fine-tuning the Qwen2-7B-Instruct base model, with its reasoning capabilities developed through Chain-of-Thought (CoT) fine-tuning with a combination of reasoning datasets - filtered Open-o1 CoT, Marco-o1 CoT, and a Marco-o1 Instruction dataset – that total 60,000 query-response samples.
Monte Carlo Tree Search (MCTS) is integrated during inference, using the model's confidence scores to guide the search for optimal solutions. A novel reasoning action strategy varies action granularity (steps and mini steps of 32 or 64 tokens) within the MCTS framework to improve efficiency and accuracy. A reflection mechanism further enhances performance:
We introduce a reflection mechanism by adding the phrase “Wait! Maybe I made some mistakes! I need to rethink from scratch.” at the end of each thought process.
Experimental results on the MGSM benchmark (both English and Chinese) show accuracy improvements compared to the base model, from 84% on base model to 90% with MCTS integration. They didn’t however share results on AIME benchmark, so no direct comparison with o1 could be made. It will need to train further based on Process Reward Modeling (PRM) to get closer to o1-level performance; this is planned future work.
Qwen’s QwQ: Qwen with Questions
Another Alibaba team, the Qwen team, has released their own o1-like reasoning model, Qwen QwQ – Qwen with Questions. The team released a model but hasn’t published a paper on it. However, the blog post QwQ: Reflect Deeply on the Boundaries of the Unknown shares some essential details.
QwQ-32B-Preview is based on Qwen 2.5 32B and fine-tuned to reflect and ‘think’ harder through problems, much like the o1 model does:
Before settling on any answer, it turns inward, questioning its own assumptions, exploring different paths of thought, always seeking deeper truth.
QwQ scores remarkably well on key reasoning-related benchmarks: 65.2% on GPQA, 50.0% on AIME, 90.6% on MATH-500, and 50.0% on LiveCodeBench.

While this is encouraging, QwQ has several limitations and is a preview model: QwQ may mix languages or switch between them unexpectedly; it can get into circular reasoning patterns; it’s not reliable and needs added safety measures; it excels at math and coding but lacks in common sense reasoning.
This is just a beginning for QwQ:
This version is but an early step on a longer journey - a student still learning to walk the path of reasoning.
The o1 model showed what is possible, the Marco-o1 and QwQ models show what is practical in a smaller reasoning AI model for. It’s truly remarkable that a 32B parameter QwQ preview model is able to outmatch Claude 3.5 Sonnet and GPT-4o on reasoning benchmarks. We can expect more o1 model imitators vying to catch-up.
The O1 Replication Journey
A group of Chinese students have taken on the challenge of replicating OpenAI's O1 model capabilities through various experiments. They shared a second installment of their findings in O1 Replication Journey -- Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?
This paper examined the use of knowledge distillation in an o1 replication model. This method involves directly prompting O1 with complex problems to generate long-thought chains, which are then used for supervised fine-tuning or reinforcement learning.
Through extensive experiments, we show that a base model fine-tuned on simply tens of thousands of samples O1-distilled long-thought chains outperforms O1-preview on the AIME benchmark with minimal technical complexity.
They further found that the distilled reasoning model had reduced hallucinations and demonstrated strong generalization to open-ended QA tasks. Just as distilling large LLM knowledge can improve smaller LLMs, so too reasoning processes can be distilled and used in fine-tuning, making it easier to incorporate reasoning into models.
The authors warn that leaning on distillation to advance models causes problems. Distilled models have a ceiling of capability based on the base reasoning model; it can lead to easy wins that cause AI researchers to miss crucial innovations and shift from fundamental advances. Distillation is imitation, not innovation.
The authors also introduce a Technical Transparency Index (TTI) framework to benchmark O1 replication attempts based on data, methodology, evaluation, and open-source resource transparency. The authors provide a GitHub repository with relevant resources for their project.