AI Week In Review 24.02.17
Huge Week: Google's Gemini 1.5, OpenAI's Sora video gen and ChatGPT memory, Nvidia's Chat with RTX, Meta's V-JEPA, Mistral-next, Large World Model (LWM), Reddit sells content, Magic Dev Series A.


Cover art: From Jascha Sohl-Dickstein on X: a video of a dense grid search over neural network hyperparameters. Blueish colors correspond to hyperparameters for which training converges, reddish colors to hyperparameters for which training diverges.
AI Tech and Product Releases
The biggest two releases this week of big news came on Thursday and was reported in depth in our “Shock News x2!” article:
Google Gemini 1.5 Pro expanded context window length to 1 million tokens and outperforms Gemini 1.0 Ultra, making it possibly the best AI model in the world now. Google put Gemini 1.5 Pro out on a limited release.
OpenAI’s Sora text-to-video AI model is a stunning advance in AI video generation; it’s “a huge leap forward with better consistency, fidelity and realism.”
OpenAI also released Memory and new controls for ChatGPT, so ChatGPT can remember facts, preferences and instructions to improve future chats:
You're in control of ChatGPT's memory. You can explicitly tell it to remember something, ask it what it remembers, and tell it to forget conversationally or through settings.
You can turn off the feature entirely, have temporary chats that exclude memory, and use custom instructions to define personalization settings. Also, custom GPTs will have their own distinct memory. All this will make the GPT-4 experience more of a companion AI than an AI that is a blank slate for each individual inference.
NVIDIA released Chat with RTX. This enables a localized personalized chatbot that runs on your own GeForce RTX 30 or 40 Series GPU with at least 8GB of memory. Dr Jim Fan explains why it’s significant:
It's Nvidia’s first step towards the vision of "LLM as Operating System" - a locally running, heavily optimized AI assistant that deeply integrates with your file systems, features retrieval as the first-class citizen, preserves privacy, and leverages your desktop gaming GPUs to the full.
DeFog Data releases a 7B SQL coding model that beats GPT-4 on SQL coding tasks!
We updated the weights for sqlcoder-7b-2, and it now outperforms GPT-4 for most SQL queries – especially if you give it the right instructions and prompt well.
A good high-quality small model can beat much larger models on specific tasks.
Mistral’s next model? Mistral-next has been found on lmsys Chatbot arena and it’s getting great reviews: “ I am testing it for coding—it's GOOD.” Some calling it GPT-4 level: “I tested it for half an hour and its reasoning abilities are at GPT4's level. It beats Gemini Ultra 100% of the times.”
Another pre-release news item: Apple Readies AI Tool to Rival Microsoft’s GitHub Copilot.
Top Tools & Hacks
Perplexity has “Collections” that helps define a storing custom prompts, which is great for repeated queries. Youtuber Josh Evilsizor shows how to make personal AI Chatbot agents from Perplexity Collections.
Chatbot Arena, mentioned in the Mistral-next news item, is an easy way to try out some new AI models and compare them. “Ask any question to two anonymous models (e.g., ChatGPT, Claude, Llama) and vote for the better one!” Find it at chat.lmsys.org.
AI Research News
Meta’s FAIR AI Research group has publicly released the AI model V-JEPA, The next step toward Yann LeCun’s vision of advanced machine intelligence (AMI). Building on Meta’s prior I-JEPA (image JEPA) work, V-JEPA (with the V standing for video) is a non-generative model trained in an self-supervised manner by predicting (in an abstract representation space) masked parts of a video. V-JEPA models were trained on 2 million public dataset videos using a feature prediction objective.

They have released the AI model to Github and produced a paper “Revisiting Feature Prediction for Learning Visual Representations from Video” explaining their research. V-JEPA exhibits “versatile visual representations that perform well on both motion and appearance-based tasks, without adaption of the model’s parameters; e.g., using a frozen backbone.” So V-JEPA can be used as a visual model for a number of downstream tasks, and the results outperform prior Visual transformer models:
our largest model, a ViT-H/16 trained only on videos, obtains 81.9% on Kinetics-400, 72.2% on Something-Something-v2, and 77.9% on ImageNet1K.

The Large World Model (LWM), presented in “World Model on Million-Length Video And Language With RingAttention,” is a general-purpose 1M context multimodal autoregressive model, trained on a large dataset of diverse long videos and books, that can perform language, image, and video understanding and generation. The paper makes several innovations in AI model training:
To accomplish training on million context-length multimodal sequences, they implement RingAttention, masked sequence packing, and other key features.
They overcome vision-language training challenges with masked sequence packing for mixing different sequence lengths as well as other innovations.
They train a large context size neural network, setting new benchmarks in difficult retrieval tasks and long video understanding.
They produced a family of 7B open-source LWM models capable of processing long (1 million token) text documents and videos. This work paves the way for training on massive datasets of long video and language, creating a new kind of multi-modal AI model.
The paper “An Interactive Agent Foundation Model” proposes a novel multi-task agent training paradigm for training AI agents across a wide range of domains, datasets, and tasks. This involves training models to predict visual and action tokens in addition to language tokens, to explicitly train the model for visual and agentic tasks, thus “enabling a versatile and adaptable AI framework.”
The strength of our approach lies in its generality, leveraging a variety of data sources such as robotics sequences, gameplay data, large-scale video datasets, and textual information for effective multimodal and multi-task learning. Our approach provides a promising avenue for developing generalist, action-taking, multimodal systems.

These three above AI research results - V-JEPA, LWM, and Agent Foundation Model - all show us potential paths towards AGI: Massive context, natively multi-modal, world understanding, and “next action” predictions to navigate in the world. I believe AGI will have all those elements.
AI Business and Policy
Magic.dev Raises $28 Million To Build AI Software Engineer. Their new $23 million Series A is led by Alphabet's CapitalG and includes Nat Friedman (former CEO of Github).
Reddit has a new AI training deal to sell user content. “Over a decade of valuable user content is now for sale as Reddit preps to go public.”
The AI drone wars escalate, as UK, Allies Look to Arm Ukraine With AI-Enabled Swarm Drones.
Clearing up confusion around reports of Sam Altman’s $7 trillion bid for AI chip investment. Correction: It’s a sum of AI infrastructure investment over coming decades, not a fundraising goal!
AI hype is fading, according to earnings calls. The number of times “AI” or related terms was mentioned on earnings calls has fallen from 517 instances in Q4 2023 to just 198 in Q1 2024.
AI-based autonomous auto racing is a thing, and it promises safer driverless cars on the road:
At the Indy Autonomous Challenge passing competition held at the 2024 Consumer Electronics Show in Las Vegas in January 2024, our Cavalier team clinched second place and hit speeds of 143 mph (230 kilometers per hour) while autonomously overtaking another race car, affirming its status as a leading American team. TUM Autonomous Motorsport from the Technical University of Munich won the event.

Karpathy is leaving OpenAI. No drama or conspiracy, he’s just moving on to his next thing.
AI Opinions and Articles
Doomers, set your doom clock: ‘Humanity’s remaining timeline? It looks more like five years than 50’.
Via KaladinFree on X, Zuckerberg reviews Apple Vision Pro and compares the Meta Quest3 with it. Unsurprisingly, he says Meta’s Quest3 is better: Tracks better, lighter, and “just way more to do in there than there is in Apple Vision Pro.”
He also makes a point about open versus closed ecosystems for the headset platform: “I want to make sure the open model wins.” I agree with that aspiration. He also reminds us that “The best way to predict the future is to invent it.”
A business consultant points to the lack of ideas among corporate leaders and says they can’t keep telling Wall Street that AI will fix all their problems:
Everyone is waiting for someone else to deliver the kind of supersize impact from AI promoted in podcasts, at JP Morgan’s Annual Healthcare Conference in San Francisco, from atop the magic mountain in Davos, and promised as the panacea for slow growth …
Lots of observers. Lots of ornamental hand-waving. Nothing tangible beyond a cool tech pilot. … Without a novel strategy, management innovation, and new concepts, generative AI can’t produce a world much different than the one we already know.
The AI revolution will so upend value propositions and business models, that few leaders have the means to grasp it.
A Look Back …
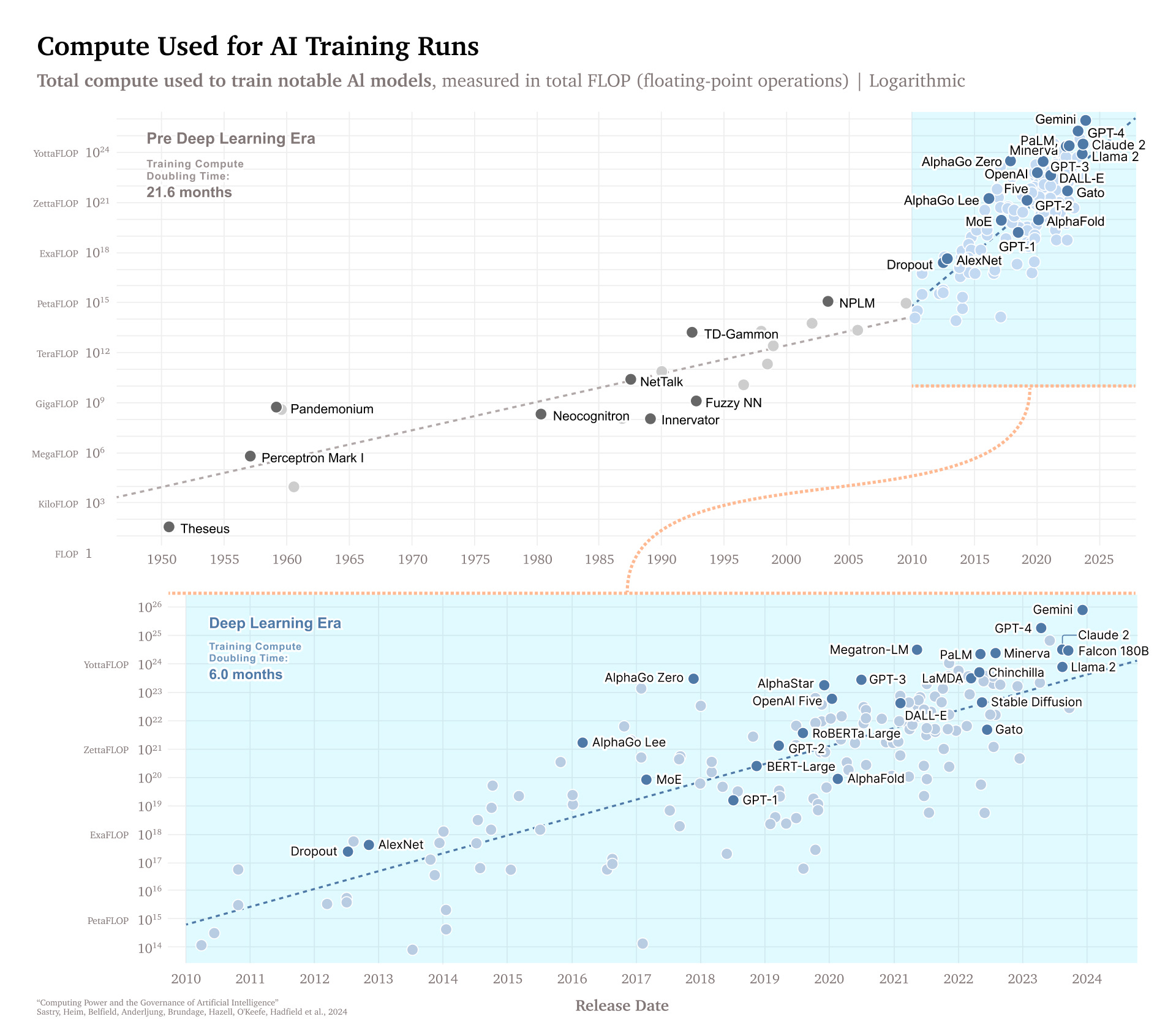
From the paper “Computing Power and the Governance of Artificial Intelligence,” this remarkable chart shows the massive rise in computing power required to build the ever-more sophisticated AI models since the dawn of AI. Early simple Perceptrons in the 1950’s required a megaflop to train; huge in that era, it could be solved in a millisecond on current laptops.
The compute requirements started ramping up much faster in the deep learning era, starting with AlexNet in 2012. the compute required to train an AI model rose 8 orders of magnitude from AlexNet 11 years ago to Gemini today. That’s an order of magnitude increase in computing power every 16 months.
This trend will continue, and it is driving an insatiable demand for AI chips, in turn making AI chip-maker Nvidia one of the most valuable companies in the world today.