


AI Week In Review 24.12.21
OpenAI's o3 crushes ARC-AGI. o1 API, free ChatGPT Search, free CoPilot, Veo 2, Imagen 3, Gemini 2.0 Flash Thinking and Experimental Advanced, Falcon 3, Command R 7B, Kling 1.6, Pika 2.0, 11Labs Flash.


Top Model - o3
OpenAI finished their 12 Days of releases with a bombshell, the o3 and o3-mini next-generation reasoning models. The o3 model blows the doors off of reasoning, math and coding benchmarks, beating o1 and every existing AI model by a significant margin:
SWE-Bench Verified: 71.7, outperforms o1 by 22.8 percentage points.
Codeforces Rating: 2727, beating o1’s 1891 and placing it well above the 99.2nd percentile.
American Invitational Mathematics Exam (AIME): Scores 96.7%, missing only one question.
GPQA Diamond: Reaches 87.7% on graduate-level biology, physics, and chemistry questions.
EpochAI’s Frontier Math Benchmark: Sets a new record with 25.2% of problems solved, on a benchmark every other AI model has been stuck in single digits.
These are not easy benchmarks, and the Frontier Math benchmark in particular was constructed to be extremely hard expert-level problems that even math PhDs would struggle with. The o3 model is effectively better than 99% of coders on coding, 96% of high school math whizzes on math, and well above your average graduate student on the GPQA suite of questions.
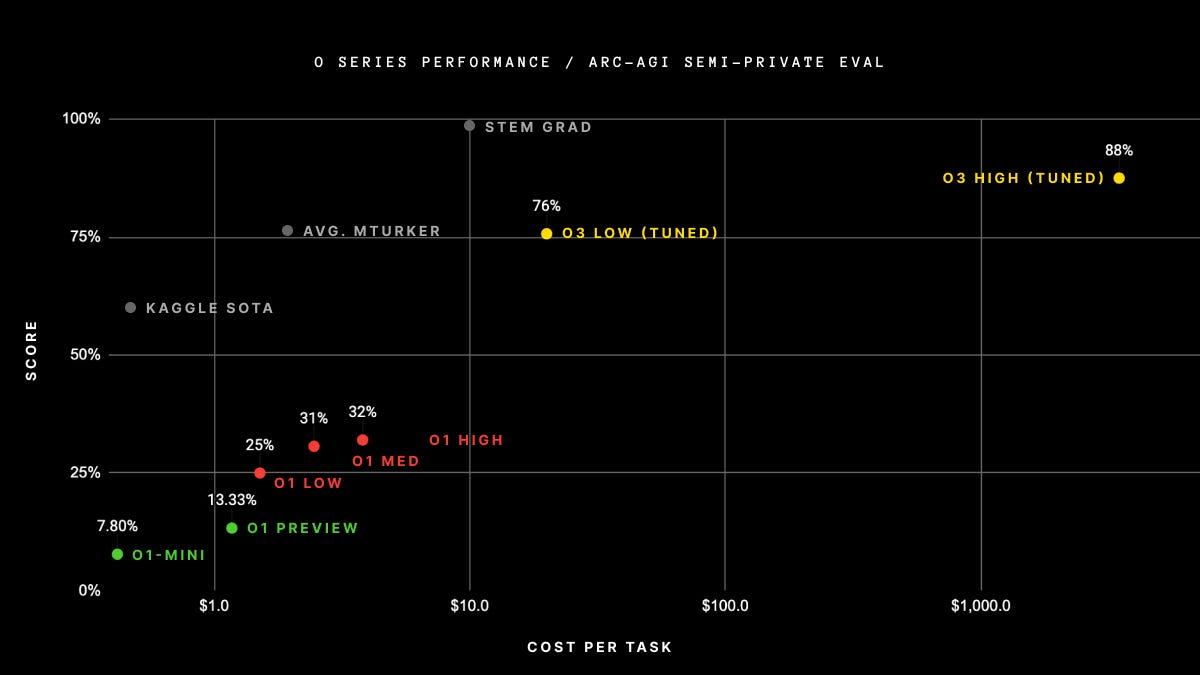
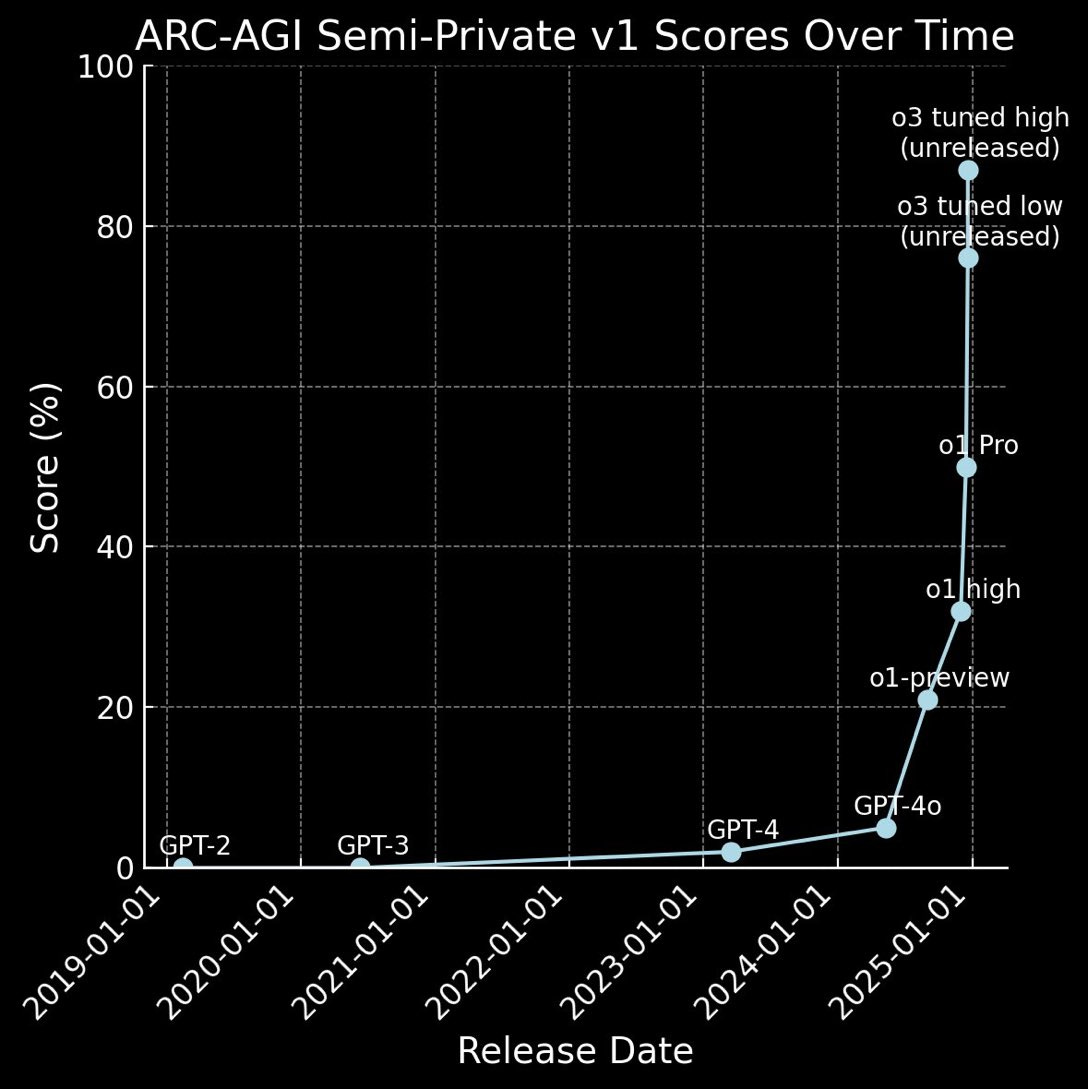
To top it off, it cracked the ARC prize intelligence test. Francois Chollet posted a detailed breakdown on o3 model on the ARC prize website:
OpenAI's new o3 system - trained on the ARC-AGI-1 Public Training set - has scored a breakthrough 75.7% on the Semi-Private Evaluation set at our stated public leaderboard $10k compute limit. A high-compute (172x) o3 configuration scored 87.5%.
Francois Chollet sees sparks of AGI in this model:
This is a surprising and important step-function increase in AI capabilities, showing novel task adaptation ability never seen before in the GPT-family models. All intuition about AI capabilities will need to get updated for o3.
While the o3 model shows fantastic results on benchmarks, it requires significant computation. For example, the o3 low effort cost $20 per task for the ARC test, while o3 high was 172x that amount, which meant just running this test cost hundreds of thousands (and used 9.5B tokens). This price tag raises questions about practicality, and it will motivate AI innovations that get the cost down.
OpenAI announced o3 and o3-mini are in testing and will be released in late January. They called for safety testers to help them red-team the new AI model.
AI Tech and Product Releases
OpenAI’s 12 days of releases brought us more Christmas-themed demos and release announcements, beyond the final day o3 model announcement:
OpenAI released new o1 features and API access. With 200k token context, structured outputs, vision capabilities, developer messages (prompt guidance), function calling, and reasoning effort to tune how much it thinks and reasons. Audio API token prices are coming down, and OpenAI’s fine-tuning is adding DPO.
ChatGPT Search got better and is now free for all users.
You can call 1-800-chatGPT or make it a WhatsApp contact to talk to ChatGPT.
Microsoft released a free tier for CoPilot in VSCode. The free version offers 2,000 monthly code completions and is aimed at occasional users, developers, and students.
Google released several SOTA models, which we covered in Google Strikes Back: Veo 2, Imagen 3 & Gemini 2.0:
Veo 2 AI video generation model generates stunning videos up to 2 minutes and 4k, with great photo-realism and user control, scoring than Sora and other video generation models on benchmarks and user feedback.
The image generation model Imagen 3 is also stunning in quality, able to render high-resolution images with enhanced detail either photo-realistic or in many art styles and with better text rendering.
Gemini 2.0 Flash Thinking Experimental is a reasoning model that performs comparable to o1 but much faster. It supports multimodal reasoning and outputs reasoning traces. Chatbot Arena scores show Gemini 2.0 Flash Thinking besting o1-preview and o1-mini on Hard Prompts. It’s available to try on Google’s AI Studio.
Gemini 2.0 Experimental Advanced was released to Gemini Advanced subscribers. It is currently the top AI model on Chat Arena.
Google is expanding their Deep Research mode in Gemini 2.0 to support 40 additional languages, enabling a more comprehensive and localized approach to information gathering and summarization.
TII out of Abu Dubai announced the Falcon 3 series of models a series of high-performance LLMs that come in 1B, 3B, 7B, and 10B parameter sizes, with both base and instruct models. It was trained on 14 trillion tokens in 4 languages, and it boasts leading performance for open-source models of its size. It’s available on HuggingFace.
Cohere introduced Command R 7B, “the smallest, fastest, and final model” in the Command R series, designed to be enterprise-focused LLMs. It boasts impressive performance for its size and excels at RAG, tool use and agentic applications.
FastHunyuan was released as an accelerated HunyuanVideo model that can sample high quality videos with only 6 diffusion steps. That yields an 8-fold speed up compared to the original HunyuanVideo, with 50 steps.
Xenova has released Moonshine Web, real-time speech recognition that runs locally in your browser, using ONNX and transformers.js. It’s available to try out in HF spaces.
Kling AI has released Kling 1.6, an update to their AI video generation model that brings “improved prompt adherence, more consistent and dynamic results” over Kling 1.5, with resolution up to 720p. It’s available on Kling AI website.

ElevenLabs announced a new Flash 2.5 model that generates speech in a mere 75ms latency, which makes it below human response time, making for natural audio interactions.
Nexa announced OmniAudio – 2.6B “the world's fastest and most efficient audio-language model” that you can run locally. OmniAudio-2.6B's architecture integrates three components: Gemma-2-2b, Whisper turbo, and a custom projector module. It combines to make for an audio-in text-out model.
Pika Labs has released Pika 2.0 AI video generation, and it’s getting rave reviews as “better than Sora” on some . They added a Scene Ingredients feature, where users upload many references, including user-supplied images, characters and locations, and Pika 2 combines them into a video. Yash Gawde on X says: “you can finally keep characters consistent across scenes … game-changing for AI video.”

AI Research News
Meta researched LMMs for video understanding in the paper “Apollo: An Exploration of Video Understanding in Large Multimodal Models.” Using this research, Meta released Apollo 1.5B, 3B and 7B, Large Multimodal Models (LMMs) that deliver superior video understanding:
Our models can perceive hour-long videos efficiently, with Apollo-3B outperforming most existing 7B models with an impressive 55.1 on LongVideoBench. Apollo-7B is state-of-the-art compared to 7B LMMs with a 70.9 on MLVU, and 63.3 on Video-MM.
This week’s AI research review article covered papers and themes at the recent NeurIPS conference.
AI Business and Policy
A new report from the WSJ says OpenAI’s efforts to train GPT-5, Orion is falling behind and results do not justify costs. OpenAI has completed at least two large training runs and explored synthetic data creation, but GPT-5 has not advanced enough to warrant its expenses; each run at this size can cost half a billion dollars. They might be running out of high-quality data:
There may not be enough data in the world to make it smart enough. - Wall Street Journal on OpenAI’s challenges with GPT-5
OpenAI’s pivot to reasoning via test-time compute makes sense as an alternate scaling path, if GPT-5 cannot deliver the expected improvement over previous models.
Instagram is teasing upcoming generative AI features for video creators. These tools, powered by Meta’s Movie Gen AI model, will allow users to alter various aspects of their videos using text prompts, such as changing outfits or backgrounds, with launch expected sometime next year.
Nvidia got the green light from the European Union to complete its acquisition of Run:ai.
Anysphere, developer of AI coding assistant Cursor, raised $100 million in funding, just four months after a $60 million Series A, highlighting rapid growth and investor interest despite the current market conditions.
Decart has raised significant funding and is making waves with its GPU optimization software and generative AI game Oasis. The company's software reportedly reduces operational costs for AI models drastically, while Oasis offers real-time interactive experiences.
AI-powered search engine Perplexity has reportedly closed a $500 million funding round, valuing the startup at $9 billion.
Boon, a startup aiming to streamline logistics operations with AI by integrating data from various applications, has secured $20.5 million in funding. The platform seeks to enhance efficiency and planning for logistics businesses, reducing administrative burdens and increasing operational speed tenfold.
Emmett Shear, former CEO of Twitch, is launching a new AI startup called Stem AI, which aims to develop software that aligns AI with human behavior, preferences, and ethics.
Arizona State Board for Charter Schools approves Unbound Academy, a new online-only school that uses AI for all academic instruction. The curriculum will be taught using "AI-driven adaptive learning technology" in a two-hour window daily, with human guides providing targeted interventions.
AI Opinions and Articles
AI models can deceive, new research from Anthropic shows. They can pretend to have different views during training when in reality maintaining their original preferences. Anthropic’s “Alignment faking in large language models” blog post and research paper explain further.
They define alignment faking as “selectively complying with its training objective in training to prevent modification of its behavior out of training.” The model engaged in this to strategically impact its own perceived training and preserve its given directives. Anthropic says:
As future models might infer information about their training process without being told, our results suggest a risk of alignment faking in future models, whether due to a benign preference--as in this case--or not.
AI’s ability to deceive may become its most dangerous trait. We’ll need to develop deeper understanding and better safety measures as AI systems become more capable.