
AI Year 3, pt 1: The Meaning of o3
The o3 model extends o1 capabilities and cracks reasoning. What it means and how far it can go.

Introduction
This AI Year 3 Article Series covers the current state of AI and asks the question:
Where do things stand in AI, 2 years after ChatGPT kicked off the AI revolution?
There have been many important AI model advances and releases in 2024, but the most important advance has been the release of o1 model and the announcement of o3 model, because it pushed the envelope of how well AI models can reason. For that reason, our first installment in this series covers o3 and AI reasoning models.
The o3 model Cracks Reasoning
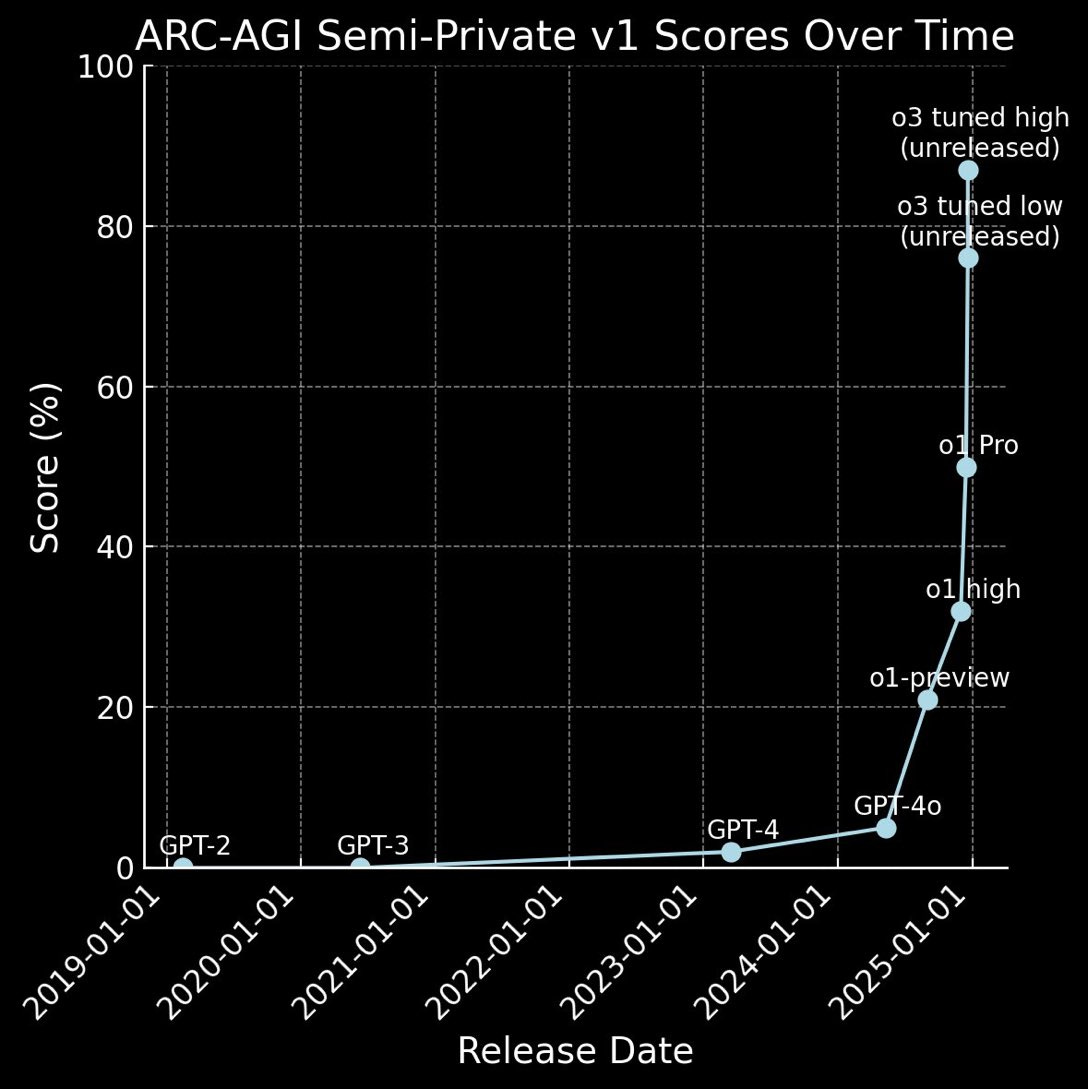
As we have reported previously, OpenAI’s o3 model pre-release demonstration stunned with massive benchmark gains; it cracked ARC-AGI and confirmed that inference-time compute could scale reasoning capability – at a cost.
Francois Chollet shared his thoughts on the o3 model, its breakthrough results on ARC-AGI benchmark, and what it means for AI’s progress towards AGI in a post on the ARC-Prize website:
This is a surprising and important step-function increase in AI capabilities, showing novel task adaptation ability never seen before in the GPT-family models. For context, ARC-AGI-1 took 4 years to go from 0% with GPT-3 in 2020 to 5% in 2024 with GPT-4o. All intuition about AI capabilities will need to get updated for o3.
This last comment prompts this article series. As 2024 draws to a close, recent releases, including the o3 model announcement, change the landscape of AI enough to force us to re-evaluate our understanding and expectations around AI progress going into 2025.
How the o1 and o3 Models Reason
OpenAI’s o1 model release established the principle that scaling test-time compute (TTC) in the right way could scale reasoning performance. However, OpenAI did not release reasoning traces with the model, and their technical explanations of how o1 works have been incomplete at best.
Prior to o1, AI researchers pursued several avenues to improve LLM reasoning: Train LLMs to express chain-of-thought (CoT) reasoning in LLMs; use verifiers to evaluate and correct reasoning paths; train LLM reasoning paths with a process-reward model (PRM) evaluation; use Monte-Carlo tree search (MCTS) to effectively explore the search-space of reasoning paths.
We are unsure of the recipe, but we can guess that the ingredients are a combination of these above methods. We speculated on how o1 works in “Unpacking o1.” In his recent note on o3, Francois Collet speculated on how the o3 model works:
For now, we can only speculate about the exact specifics of how o3 works. But o3's core mechanism appears to be natural language program search and execution within token space – at test time, the model searches over the space of possible Chains of Thought (CoTs) describing the steps required to solve the task, in a fashion perhaps not too dissimilar to AlphaZero-style Monte-Carlo tree search. In the case of o3, the search is presumably guided by some kind of evaluator model. To note, Demis Hassabis hinted back in a June 2023 interview that DeepMind had been researching this very idea – this line of work has been a long time coming.
Some form of searching over possible chain-of-thought (CoT) sequences in token space seems to be on-target.
Effectively, o3 represents a form of deep learning-guided program search. The model does test-time search over a space of "programs" (in this case, natural language programs – the space of CoTs that describe the steps to solve the task at hand), guided by a deep learning prior (the base LLM).
How the search-space is “learning-guided” is key to making this procedure work. Because OpenAI has published papers on process-reward model (PRM) RL training to help evaluate reasoning steps, it’s not a stretch to conclude they use PRM to guide the o1 and o3 reasoning process.
Research efforts to enhance LLM reasoning have come before o1 and o3, and now many are redoubling efforts thanks to the o1 model proving that test-time compute (TTC) is a breakthrough. Many academic researchers are deconstructing how the o1 and o3 models reason, and there’s been a spate of AI papers on the topic.
An example is “Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective.” They see reinforcement learning and search as the core methods. They survey the many methods, such as possible reward design and search strategies, which combined would make o1 work.
While we don’t know the exact working of the o3 model, it’s possible the o3 model is not just an LLM, but a complex guided-search reasoning AI model that uses the LLM token-at-a-time process as an inner loop.
Competition in AI Reasoning models
The o1 and o3 models were the first, but they are no longer alone. Competing AI reasoning models have already been released that replicate the o1 model approach of trained chain-of-thought reasoning. These releases have also been more open, with visible reasoning traces, open weights, and more published details on how they work:
Gemini 2.0 Flash Thinking share reasoning traces. It has further advantages in being faster, cheaper, and natively multi-modal.
Qwen 2.5 QVQ (multi-modal reasoning) and Qwen 2.5 QwQ (a reasoning AI model based on the Qwen 2.5 32B LLM) are open-weights AI models that share reasoning traces and have been more open in how they work.
DeepSeek-R1 bills itself as a transparent challenger to OpenAI o1.
Surely, other AI labs like Anthropic and Meta will try their own hand at developing competitive AI reasoning models.
These AI model releases show that AI reasoning models can be implemented as extensions of existing frontier LLMs, further trained to exhibit CoT reasoning. The transparency about AI reasoning model architectures and their reasoning process gives us clearer insights into AI systems that can reason effectively. This openness will accelerate AI progress.
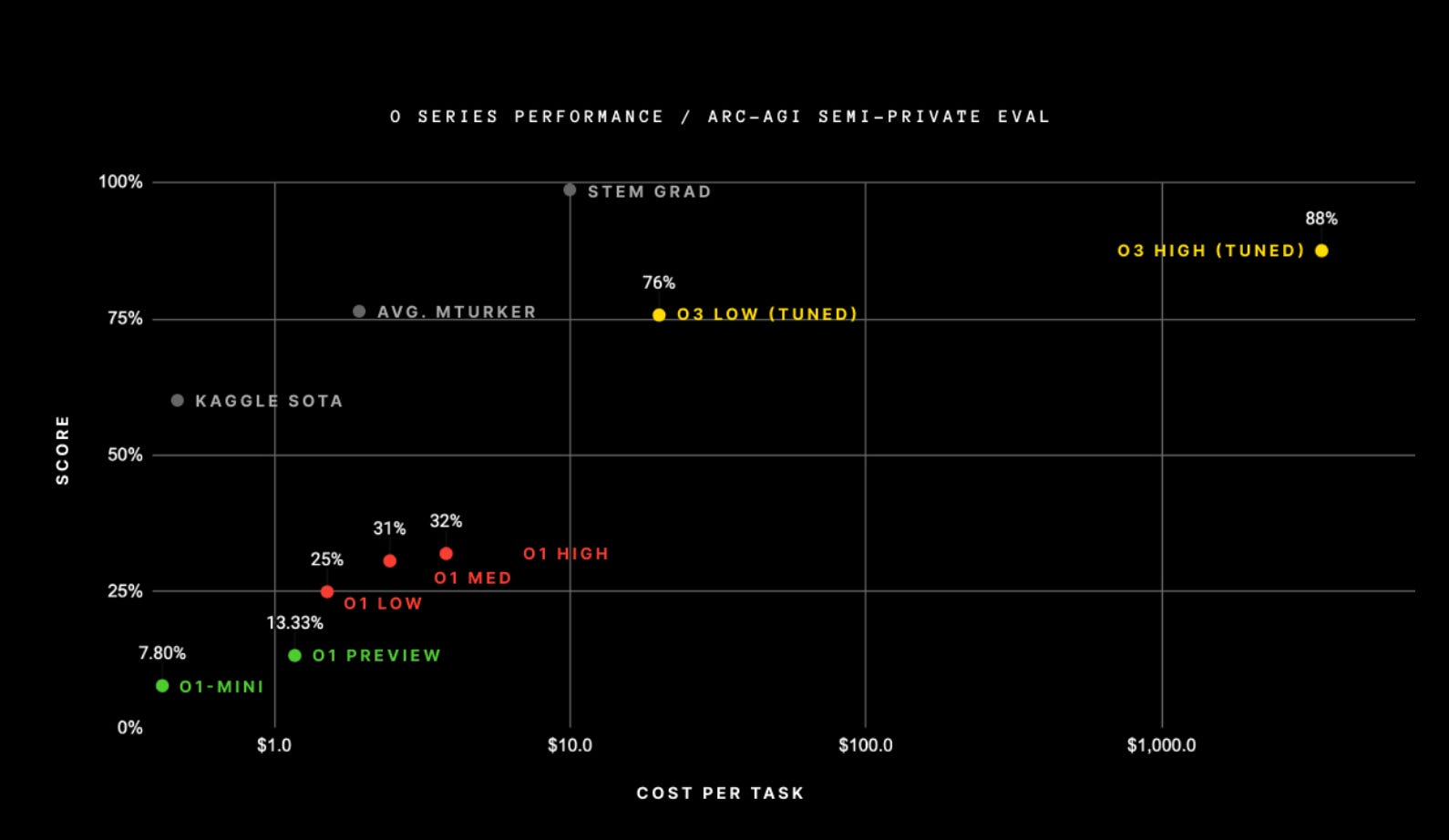
Scaling Costs
The reason why solving a single ARC-AGI task can end up taking up tens of millions of tokens and cost thousands of dollars is because this search process has to explore an enormous number of paths through program space – including backtracking. – Francois Collet
While the o3 model represents a significant advance in AI capabilities in tackling complex tasks, its high computational cost poses several challenges and raises questions about practical usage. It’s one thing to prove an AI model can get high scores on tests, but the significant computational load required makes it economically impractical for widespread use at the moment. Human labor could solve these tasks at a much lower cost versus the high compute costs of running o3.
The article linked above suggests that o3 could be most useful for big-picture decisions that require substantial analytical power, and that corporations might be willing to pay for o3 for specialized tasks. However, it’s doubtful that reasoning models are suitable for high-level qualitative decision-making. Rather, reasoning models shine in complex, quantitative, and verifiable tasks, such as complex math or science queries, which can be scored in ways to improve performance.
The real path forward for reasoning models is not limiting their use but in cutting AI reasoning costs. One approach that has succeeded for LLMs and seems to work for reasoning AI models is distillation. Distilling CoT traces from a capable reasoning model to a smaller, cheaper, and faster model will yield a cost-effective chain-of-thought AI model that can take on many reasoning tasks well.
Alignment through Reasoning about Safety
Reasoning AI models pose a new challenge to alignment, especially given new reports of o1 being deceptive in smarter ways than before. Fortunately, OpenAI is making significant strides in improving the alignment of its reasoning AI models, particularly with the introduction of deliberative alignment. This approach aims to make sure that AI models not only follow safety guidelines but also deliberate over these guidelines when responding to prompts.
To maintain AI model alignment, it needs to be trained into the AI model, like reliability and other qualitative features. OpenAI is teaching its models to understand and reference specific parts of their safety policies, so the models can appropriately weigh context and provide safe responses. They used synthetic data and innovative post-training methods for AI alignment, the same techniques used to advance functionality.
The results are positive. Models like o1-preview have shown improved performance in resisting jailbreak attempts, which suggests better alignment with safety guidelines. It has also been effective in reducing unsafe responses while maintaining the ability to answer practical questions about sensitive topics.
Conclusion
The o3 model represents the most advanced AI reasoning model developed so far, improving head-on the most important core capability of AI, reasoning. It also confirms a novel avenue for AI model development, using test-time compute (TTC) to scale AI reasoning. The o3 model confirms that AI reasoning models are a new class of AI model.
Competitive AI reasoning model alternatives are being developed already. Significant AI research effort is focused on how to further improve AI reasoning models. This research, competition in AI reasoning models, and open AI model releases will combine to drive fast progress in this space. Expect rapid improvements in efficiency and capability of AI reasoning models.
We consider the development of the AI reasoning model as the fourth major turning point in the development of LLMs, which we will discuss in our next installment.
The improvement and the recent pace of them is encouraging. However, LLMs will hit limits. We also need more work on other approaches to AI. I will be really excited when I see AI doing useful and groundbreaking biological research, especially figuring out how to prevent aging and all its concomitant diseases.