
Unpacking o1
What o1 can do, how o1 reasons, the new scaling paradigm o1 has unleashed, and the new season for AI


A Second Look at o1
The o1 model is arguably the most important AI model release since GPT-4 (and we’ll make the case on that below), and so it deserves further review beyond sharing news of the o1 release in our recent AI Weekly.
If you haven’t tried o1 yet,
We will cover these fundamental points about the o1 (and o1-mini) model and what it means for AI:
o1 is a breakthrough in AI reasoning
o1 is not better on all tasks
OpenAI hides o1’s thinking
How OpenAI makes o1 reason
Test-time compute is a new scaling paradigm
The o1 release is a turning point in AI
AI progress is not slowing down
o1 is a Breakthrough in AI Reasoning
The ‘intelligence’ in AI is the ability to put pieces of information together to make new thoughts, information, conclusions. We mean the ability to reason.
OpenAI shared many benchmarks to make the point, so we don’t have to repeat them, but o1 excels at math, coding, advanced academics (LSAT, GPQA), scoring significantly higher than GPT-4o (and Claude Sonnet) on many benchmarks, and impressing many.
As shared by Maxim Lott on X, o1-preview achieved an IQ of 120 on the Norway Mensa IQ test, well ahead of any other AI models tested; out of all the other models tested). o1 is literally a smarter AI.
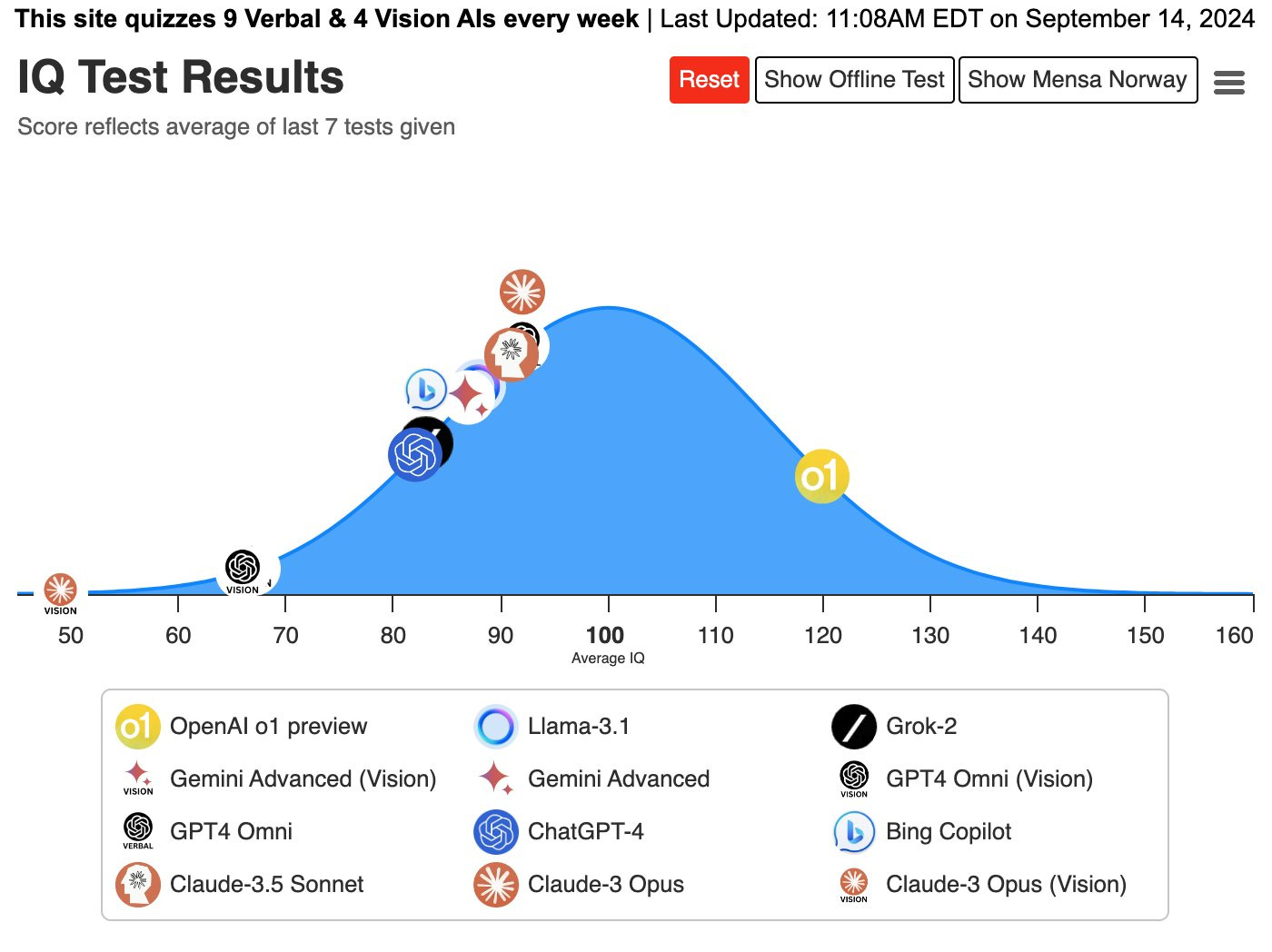
This explains the comments from Sam Altman earlier this year that we would look back and consider GPT-4 as not that intelligent, and that the new AI models would be ‘smarter.’ They have cracked the reasoning nut.
o1 is Not Better on All Tasks
“o1 is still flawed, still limited, and it still seems more impressive on first use than it does after you spend more time with it.” - OpenAI CEO Sam Altman
Although o1 is great at reasoning, that focus has downsides, and the o1 model is not for everything. The TechCrunch review of o1 labels it “An AI designed to overthink it” and cites Ravid Shwartz Ziv, an NYU professor who studies AI:
It’s impressive, but I think the improvement is not very significant. It’s better at certain problems, but you don’t have this across-the-board improvement.
As users try o1 out and get both good and not-so-good results, there has been a mix of rave reviews and more measured responses. Skill Leap AI checked o1-preview out against a custom GPT that does chain-of-thought prompting on GPT-4o, and found o1-preview was only marginally better.
We are still learning how best to prompt o1 and where to use it for the best results. You don’t need to feed it ‘chain of thought’ prompts, it’s already baked into its training.
The more skeptical take on o1 real-world use comes from Bindu Reddy on X:
Practically speaking o1 will have very limited use after the initial curiosity spike. The latency is too much, and most problems don’t need that additional complexity. It only makes sense as a fall-through when the fast models don’t solve the problem.
This is overly pessimistic. Certainly, o1 is a costly AI model to run and only some problems are complex reasoning problems that require a model like o1. However, in every domain, from software coding and science research to healthcare and law – there are important complex reasoning tasks, and they constitute the most valuable use cases for AI.
For tasks like writing assistance or text summarization, a top-shelf LLM like Claude 3.5 Sonnet is as good or better.
The o1 model will shine on some of the most challenging AI use, but use it sparingly, it’s expensive.
OpenAI Hides o1’s Thinking
OpenAI is not revealing the full chain of thought text to users, citing concerns about security, but they also shared the more honest reason: “competitive advantage.” Here’s their full explanation:
We believe that a hidden chain of thought presents a unique opportunity for monitoring models. Assuming it is faithful and legible, the hidden chain of thought allows us to "read the mind" of the model and understand its thought process. … However, for this to work the model must have freedom to express its thoughts in unaltered form, so we cannot train any policy compliance or user preferences onto the chain of thought.
We also do not want to make an unaligned chain of thought directly visible to users.
Therefore, after weighing multiple factors including user experience, competitive advantage, and the option to pursue the chain of thought monitoring, we have decided not to show the raw chains of thought to users.
Hiding reasoning tokens in o1 will not make the AI model safer. On the contrary, an AI model could be engaged in deceptive or unaligned thinking, yet users will be unaware since the thought tokens are hidden.
OpenAI’s decision to hide the chain-of-thought process puts them squarely in the opaque, proprietary camp. Transparency would be far better and more open. This is a bad practice that I hope does not spread.
Clever o1 prompting can still reveal the model's thinking. For example, I gave a prompt for a complex math-related problem that included this addendum, “Please show your work and all equations used, explaining the answer step-by-step like you are a TA explaining the answer to students.” The result was a detailed explanation, with skillful use of math notation, superior to anything I’ve seen in an AI output before. See Postscript.
How OpenAI Makes o1 Reason
There is no research moat for o1. the moat is scale and engineering execution. … - the next set of innovations are going to be henry ford style assembly line improvements on synth datagen and model evals. Less and less of this work will have humans in the loop. - XJDR on X.
The secret sauce in how o1 was made is not-so-secret. We have for some time speculated on what it would take to get LLMs to do System 2 thinking, including Tree of Thought, decoding what was in Q*, which became Project Strawberry and is now o1.
Based on all the leaks and information, we can surmise the approach OpenAI took to make o1 is this:
The o1 (and o1-mini) model is a process-reward-model RL fine-tune that started from GPT-4o or variants (GPT-4o-mini); the fine-tuned model was trained explicitly think step-by-step (CoT) and to generate ‘thinking’ tokens to explore the solution, and then verify each step (reflection) before confirming final answer.
There is no research moat for o1 because others have done most of the AI research:
Google DeepMind, since the famous AlphaGo triumph in 2016, has been pioneering use of RL methods for AI reasoning in several domains. In particular, AlphaCode 2 is an LLM combined with an advanced search and reranking mechanism, fine-tuned on large amounts of synthetic-generated problems with self-scored answers.
Getting LLMs to reason using the process reward model comes from OpenAI’s own research, “Let's Verify Step by Step.” Other approaches like STaR could also have been used. (The speculation was that Q* combined STaR with an RL Q-learning process.)
Utilizing ‘pause tokens’ and ‘thinking’ process inner monologue in LLMs gets LLMs away from linear next-token production, making them more able to process complex queries and responses well.
Further, using Chain of Thought Empowers Transformers to Solve Inherently Serial Problems.
Monte-Carlo Tree Search (MCTS): The paper “Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B” improves math performance with an innovative integration of LLMs with MCTS and self-refining. We shared this result in June.
Google DeepMind recently revealed that Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters.
LLM-as-a-judge: It is easier to score or verify an answer to a complex problem than to generate one, especially in coding or math. Thus, you can bootstrap better AI models by generating problems, having your best AI model generate many proposed answers, then verifying and scoring which are best with an AI. This becomes synthetic data generation for AI reasoning.
We do not know the exact mix used, but OpenAI used the above techniques to train o1 to reason better.
Test-time Compute is a New Scaling Paradigm
While OpenAI didn’t reveal much in the way of technical information with o1, they did share an important graphic, showing that performance increased with ‘test-time compute’, i.e., the amount of tokens and effort expended during inference.
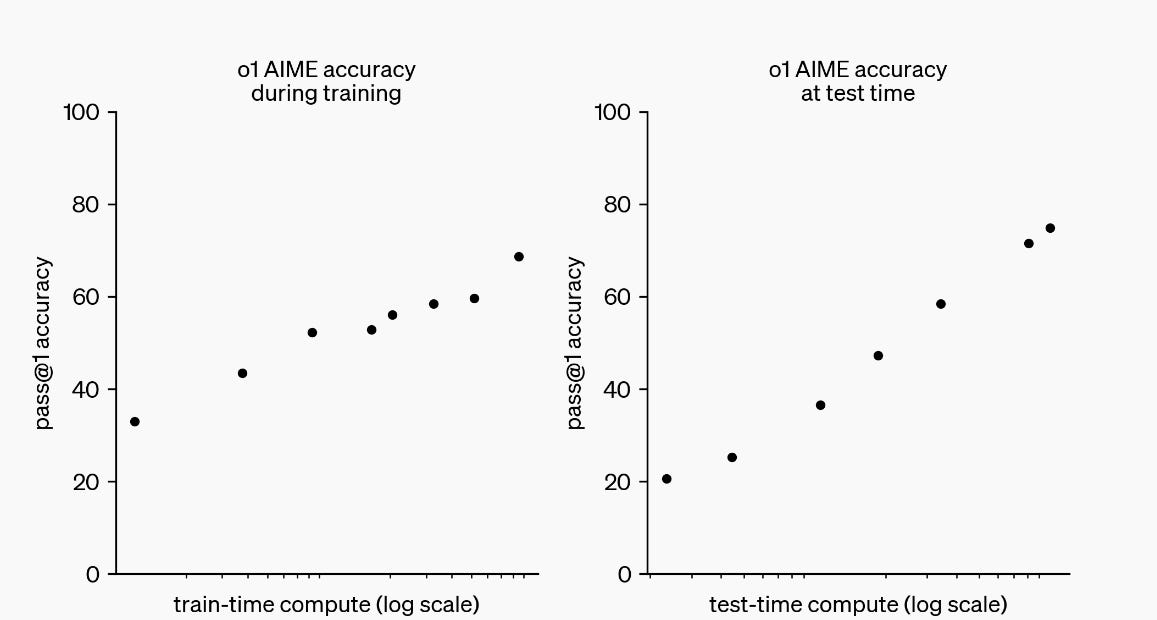
What this result means is that, like humans, if an AI model can think longer, go step-by-step, consider options, and verify results, the AI can answer tough complex questions more accurately. AI models must be trained to make the most of these “thinking tokens” so they can scale performance, but this opens a new dimension for AI model improvement.
The o1 Release is a Turning Point for AI
The o1 model achieves a huge leap in reasoning through scaling AI performance with test-time compute, which adds via a new dimension to scaling AI. In terms that Leopold Aschenbrenner uses, these are ‘unhobbling gains’ that accelerate AI progress.
The o1-mini and o1 models are not scaling parameters nor did they use massive amounts of new data to train; it was a reasoning-enhanced fine-tune of GPT-4 using synthetically generated data.
If we don’t need massive datasets, huge compute clusters, or bigger AI models to create a reasoning AI model, the implications are huge. We don’t need multi-trillion parameter AI models to have good reasoning AI models. Smaller AI models can be trained to have incredible reasoning capabilities.
We see this in o1-mini, which packs great reasoning skills in a smaller AI model.
Being able to scale performance without scaling parameters or datasets means the training process itself is less onerous. This breaks away from limits that we thought would hinder AI progress.
Smaller, cheaper AI models can be trained to have greater reasoning on datasets curated by AI, and it will not require billion-dollar training runs. This cuts the cost of AI reasoning enormously. Those smaller AI models will exhibit great reasoning capabilities by using more inference effort and will do so at extremely low cost.
AI Progress is not Slowing Down
The o1 release marks a new season for AI, the end of the beginning in the race to AGI.
The implications of the new scaling paradigm will be keenly felt once other AI companies are able to get to more advanced reasoning with similar techniques. They will be.
Anthropic may be able to replicate or surpass the o1 model soon. Claude already can generate ‘ant thinking’ tokens, given appropriate chain-of-thought prompting. Claude 3.5 Opus is on deck for release soon. They have talent that migrated from OpenAI.
Google has been pursuing their own reasoning AI efforts with Project Astra, while Google DeepMind continues to share research on various AI models trained using RL methods to solve deep challenges, like protein design. Their latest Gemini 1.5 releases continue to improve.
There is hope for open AI models as well. Several open AI models from China have shown superior performance on math and coding already. Bindu Reddy hints the next Qwen release might include o1-like reasoning. The open-source AI model community already embraces fine-tuning, so they are ready if that can be used to improve reasoning. They are already building the kinds of datasets needed.
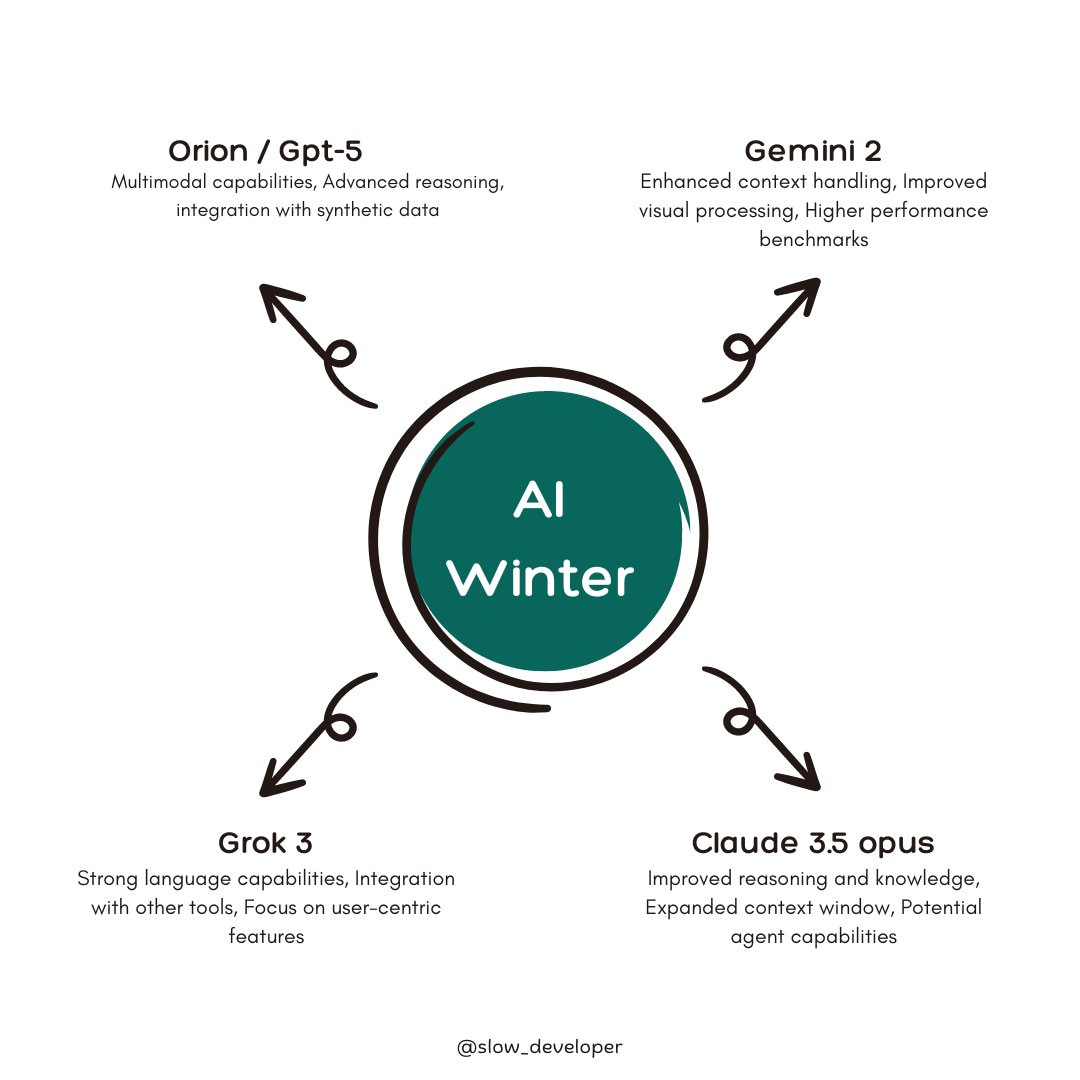
This winter will not be an AI Winter, it will be a season of an avalanche of better AI models and AI applications: OpenAI's Orion (GPT-5) and Google's Gemini 2 rumored by end of year; Anthropic's Claude 3.5 Opus building on Sonnet's success; Musk's xAI building Grok-3 on his Colossus cluster. This is just the tip of the iceberg, with many other AI model makers ready to surprise us.
“Now this is not the end. It is not even the beginning of the end. But it is, perhaps, the end of the beginning.” ― Winston S. Churchill
PostScript
The o1 model solves a complex math problem. It’s solvable with HS-level algebra, but being able to keep track of complex details accurately is impressive, as is the use of precise math notation (looks like LaTeX under the hood). Prompting “show your work” gives insight into its thinking process and could be used to generate educational content.


Sir! Wow. This the best source of information that I can use. Sorry the words fail. Your analysis and conclusions are prophetic. 👍🤪👍👍👍 Out
While o1 may not be great at most of things as in the post (I did not explore much anything else with o1 yet), but I would vouch o1 for its coding capability. It is outstanding... To add perspective, a hybrid approach for coding works 10x better than just one platform. e.g. I use claude > perplexity > o1 > then again claude to perfect my code. It works great... perplexity is in loop for research and it does a good job.