
Tree-of-Thought and Building Reasoning AI
AI research to improve LLM reasoning: RePrompting and Tree-of-Thought


The Thought Cycle
The human brain is remarkable. Limited to 85 billion neurons and using less power than a computer laptop, our brain is able to reason in ways that we still haven’t replicated fully with artificial intelligence, even powered by supercomputers with thousands of computing nodes.
Human reasoning and thinking is not singular events but an iterative succession of thoughts arising from a brain that operate in cycles. When our brain is in beta conscious ‘thinking’ mode our brainwaves operate at 12 to 40 Hz (cycles a second). Despite being much slower than mechanical computers that cycle billions of times a second, we do so much more with less.
The early years of artificial intelligence attempted to replicate human reasoning tasks by emulating human reasoning through symbolic processing techniques and reasoning algorithms. Applications lacked the ingredient of automated learning, which limited its power.
Now we have been able to use deep learning-based machine learning techniques to create AI that can learn and build a world model, and we are coming full circle to the challenge of replicating human reasoning. To solve this challenge, researchers are reaching back to using symbolic AI techniques, re-applying them to powerful LLMs to build more powerful AI reasoning engines.
We have written before on research on getting AI models to plan, which hooked up a classical planner as a ‘plug-in’ to chatGPT to give it planning powers. We have also seen how the techniques of revising and reflecting via “Chain-of-thought” is able to improve on initial prompt results.
Two new AI research papers are taking this further. “Reprompting” considers sampling from chain-of-thought, while the other extends chain of thought to “Tree-of-Thought”.
Reprompting - Sampling from Chain-of-Thought
The paper “Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling” comes from Microsoft AI researchers. The premise of the paper is that while Chain-of-Thought (CoT) prompting has effective at improving LLM reasoning ability, it’s limited by requiring human expertise on the right CoT prompt to use.
The Reprompting solution to this is to automatically derive the best CoT prompts to use via “an iterative sampling algorithm that searches for the Chain-of-Thought (CoT) recipes for a given task without human intervention.” The approach samples (using Gibbs sampling) from prior ‘parent prompts’ that work consistently well to solve other problems. The authors found that reprompting finds superior CoT prompts efficiently without any human involvement.
Using the Reprompting technique with chatGPT and instructGPT LLMs on multi-step reasoning tasks, they showed that it achieves consistently better performance on complex reasoning tasks in the Big-Bench Hard task benchmark than the zero-shot, few-shot, and human-written CoT baselines, improving by up to 17 points.

Tree of Thought framework for LLM Reasoning
The paper “Large Language Model Guided Tree-of-Thought” introduces the idea of Tree-of-Thought (ToT), aimed at overcoming the problem-solving limitations of large language models (LLMs). The limitations of reasoning in LLMs include lack of correctness checking, so you might continue with an incorrect reasoning step, and the linear sequence of solution, which precludes back-tracking.
The author says, “The ToT technique is inspired by the human mind's approach for solving complex reasoning tasks through trial and error.” It overcomes the LLM’s linear and sequential approach by building a tree-search prompting mechanism around the LLM prompt cycle.
The ToT strategy can be viewed as a tree-search algorithm using an LLM as a heuristic for generating the search steps. In this setting, the LLM is only used for the “short-range reasoning” tasks, i.e deriving the next intermediate solution, which is a type of tasks that have been shown to have a high success rate for LLMs.
The architecture of the system includes a prompter agent, a checker module, a memory module, and a ToT controller. The ToT controller decides on partial steps in the chain for the LLM to solve, feeds it to the prompter agent, which queries the LLM using the following user_input_prompt: “For the given problem: [problem description], please derive the first step, and return the step in the following JSON format {next_step: }” The LLM performs the partial step, returns results, and a checker module checks correctness of the intermediate solution. The controller then guides the next step using tree search until a full solution is found.
The search strategy and basic system components are shown below.

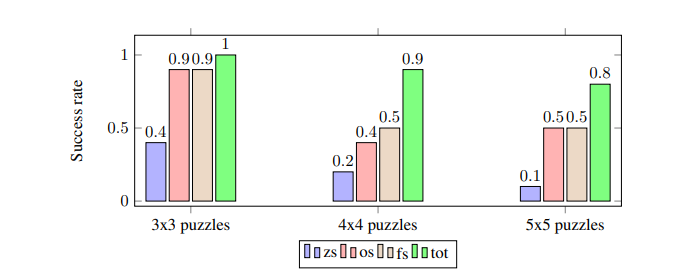
The author used this technique to solve small Sudoku puzzles, showing its ability outpaced zero-shot, one-shot and few-shot approaches.
LLMs In the Loop
Tree-of-Thought uses the LLM as the inner loop ‘solver’ of a multi-agent network, in the same manner that autonomous agents such as autoGPT iteratively prompt LLMs to solve complex tasks. With ToT, the outer-loop multi-agent network can be trained and optimized using reinforcement learning techniques.
Treating LLMs as components and a single prompt response as a sub-routine is a promising paradigm for how agents can be built to be more reliable and reason better. It relates to what I mentioned in Plugging into the AI Ecosystem:
Modularization, containerization, and component-based AI architectures, where those components are Foundation AI models, is the next phase of AI advance towards AGI.
Steps to Making AI Reason More Powerfully
Treating the LLM prompt as an iteration of a complete thought extends the capabilities of AI models enormously. To be more specific on this point, researchers have pursued multiple avenues to answer the question: How to get LLMs to solve complex reasoning tasks or answer complex questions with accuracy? Here are the different ways to make AI reasoning better and AI better overall, without improving the LLM model itself:
Prompt Engineering: Prompts need to be specific, clear, detailed, good prompts to avoid inferior outputs. For reasoning problems, Chain-of-Thought prompting yields improvements. Pre-processing prompts, using a Prompt Agent that utilizes guardrails, specifications, and other mechanisms like RePrompting (sampling of best prompt) can ensure the prompt invocation is reliably good.
Knowledge-base connection and memory: Large language model single invocations are not equipped with dynamic memory outside their context, and the result can be hallucination or lack of knowledge. The solution is Knowledge grounding AI models with a vector database and using Retrieval Augmented Generation to loaded relevant information into the context. Attaching memory to LLMs via vector databases can preserve long-range context and understanding, provide semantic search, and enable long-range prompt sequences for complex tasks.
Iterative multi-step LLM prompting: Use multiple passes to get the AI to reflect on the answer, grade its own answer, and improve on it. In “Critique and Revise to Improve AI”, we covered some of the various techniques (such as Reflexion) to reflect, revise, correct, or otherwise iterate your way to a better result for multi-step reasoning.
Leverage external tools via plug-ins: If the LLM is an inexact solver of a problem or question, then the LLM can call upon tools via plug-ins to solve it. For example, ChatGPT has done this with plug-ins such as Wolfram Alpha as well as the very powerful code interpreter plug-in that lets you execute programs on the fly, which can be used to perform program-augmented reasoning. This can also include
Use an AI controller model for coordination: As with a conductor leading an orchestra, we tie the AI iteration loop together with a controller agent or LLM, which decides on what to do next via a “Controller-Executor” design pattern. In the ToT framework, the ToT controller performs this role. In HuggingGPT, the “LLM as controller” plays this role.
Just as solving for “next token” when scaled up has led to powerful LLMs, putting all the above approaches to improve LLMs on reasoning together gives us the architecture of a powerful AI ecosystem for AI reasoning. I believe the ultimate approach for AI reasoning will be an AI architecture that uses all the above elements, and it will have the Foundation AI model or LLM as its core execution component.
Thanks for writing this, it clarifies a lot. Realy interesting how we're coming full circle to symbolic AI with LLMs. Could you elaborate on how these older techniques are being re-applied?