
Beyond Transformers with Mamba
Mamba, Striped Hyena, and state-space models (SSMs) for AI


Striped Hyena
The week before last, in the wake of the Google Gemini release, there was the release of two important open source LLMs, Mistral’s 8x7B mixture-of-experts model and the StripedHyena-7B model, both of which I mentioned in Mistral AI drops Mixture of Expert AI Model.
I have quipped that of the three model releases that week, StripedHyena might end up being the most important. Why? Because it represents a new approach based on State-Space Models (SSMs) that may actually challenge transformers as the standard architecture for LLMs.
Transformers - Effective But Expensive
Prior to the famous 2017 “Attention is all you Need” paper, sequence models in the form RNNs (Recurrent Neural Networks) and LSTMs (Long-Short-Term Memory) were the standard ways of modelling language. RNNs had property of linear processing and complexity but were inherently sequential. As a consequence, RNNs couldn’t parallelize effectively, posing scaling.
Transformer architecture came to the rescue. Within a context window, the transformer-based attention mechanism will ‘attend’ to every prior element (token) in a context. The operations to support this end up scaling well due to effective parallelization and had the merit of being a simple and effective way of ‘attending’ but at a cost: They grow quadratically on the context length.
State-Space Models
Efforts to get around the confounding quadratic complexity of transformers have largely centered around ways to preserve attention concept without incurring the quadratic cost of the transformers themselves.
Enter state-space models, a way to represent sequential data based on long-studied concepts in control theory and modelling of time series sequences. In math terms, a state-space representation can be defined as a linear mapping from an input vector u(t) to an output vector y(t) via a state-space vector x(t) and matrices (A, B, C and D).
(Don’t worry, this is the only equation in the article.)
A State-Space Model (SSM) uses these representations in a deep learning network. The matrices and state-space variables can be learned from a time-series sequence of data and act as a memory for a whole sequence. Designed right, you can reconstruct a sequence from the state-space representation.
SSMs are a general enough structure that you can think of RNNs and convolutional networks as a kind of SSM. As stated in the Mamba paper:
These models [SSMs] can be interpreted as a combination of recurrent neural networks (RNNs) and convolutional neural networks (CNNs), with inspiration from classical state space models (Kalman 1960). This class of models can be computed very efficiently as either a recurrence or convolution, with linear or near-linear scaling in sequence length …
Convolutions, FFTs, and other data sequence transformations can model a sequence at linear or near-linear complexity, so it’s possible a more efficient architecture than transformers exist. The trick is to characterize state-space matrices so that you can execute transforms efficiently, while also being as good at attention as transformers.
Hippos and Hyenas
Are there sub-quadratic operators that can match the quality of attention at scale?” - from Hyena Hierarchy by Michael Poli et al.
While SSMs have worked well in other domains in time-series modeling, they struggled to compete with attention and transformers in language modeling.
Researchers at HazyResearch at Stanford University, led by Professor Chris Ré, have produced a series of research results to tackle this problem, starting with the Structured State Space sequence model (S4), presented in “Efficiently Modeling Long Sequences with Structured State Spaces.”
In late 2022, Hungry Hungry Hippos: Towards language modeling with state space models proposed the H3 architecture to implement a more efficient SSM to challenge attention. H3 replaced the attention layer with two stacked SSMs, and also presented FlashConv to improve hardware efficiency of SSMs. It showed results ‘competitive with attention’ but still behind.

What was missing in H3 was strong data-dependent behavior, a key feature of attention. To close the gap further, they followed it up with Hyena Hierarchy: Towards Larger Convolutional Language Models; see also their blog post on Hyena Hierarchy. They asked:
Could we strengthen the data-control path in our attention-free layers? That is, is there a way can we ensure different inputs can steer our layer to perform substantially different computation?
Their solution was to combine “implicitly parametrized long convolutions and data-controlled gating” to create the Hyena hierarchy operator. The gating helps make the model learn in-context on long sequences.
As sequence length grows, the advantage of Hyena grows. They had better recall than prior SSMs. They were also very fast relative to transformers - “twice as fast as highly optimized attention at sequence length 8K, and 100 times faster at sequence length 64K.”
Mamba
While each successive iteration of SSM architecture improved on prior work, it still didn’t match up with transformer performance on language modeling. Until now, with Mamba.
The key achievement of Mamba: Linear-Time Sequence Modeling with Selective State Spaces is that it overcomes remaining hurdles in selection capability and efficiency tradeoffs in SSMs, with several innovations:
Selection Mechanism - A simple data-dependent selection mechanism helps Mamba filter out irrelevant information while retaining what is relevant.
Hardware-aware Algorithm - Mamba computes the model recurrently with a scan instead of convolution in a way that avoids memory access overhead, making the implementation linear and 3x faster.
Simplified Architecture - They combine the H3 SSM block design with the MLP block in transformer architecture to define the single block for Mamba, simplifying the whole architecture.

Mamba Results
With a simplified architecture, Mamba produces very promising results. Mamba keeps up with the best-in-class optimized transformer architectures during pre-training, as shown below, and it does so with fewer parameters. It can solve the more complex data retrieval tasks that were outside the capability of prior SSM architectures.

Mamba also enjoys 5 times higher inference throughput than Transformer LLMs of the same size, and thanks to linear scaling in sequence length its performance improves on real data up to million-length sequences. Mamba also performs well on audio waveforms and genomics (DNA sequencing).
The largest Mamba model presented is 3B parameters, but the results are promising enough to push forward and see if it can scale up further.
Striped Hyena Mixes It Up
The StripedHyena-7B that we discussed at the beginning of the article took some of the similar lessons from prior work on SSMs, including H3, Hyena and Monarch Mixer, but added another twist - a hybrid architecture:
StripedHyena is designed using our latest research on scaling laws of efficient architectures. In particular, StripedHyena is a hybrid of attention and gated convolutions arranged in Hyena operators.
As we noted in our prior article, Striped Hyena 7B showed good results, almost comparable to Mistral7B.
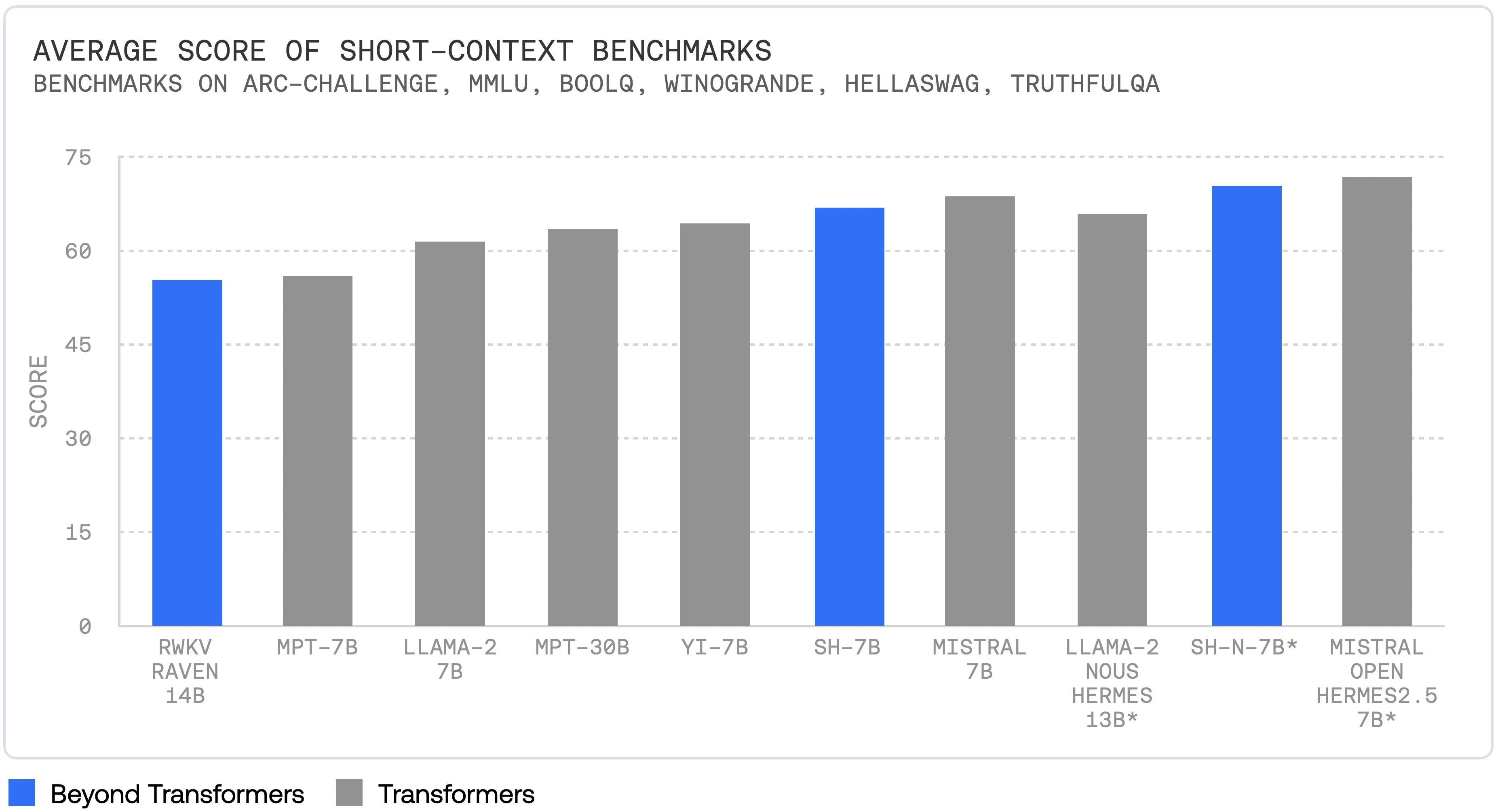
One of their conclusions from the building of StripedHyena could be a game-changer for LLM architectures:
we noticed a consistent trend: given a compute budget, architectures built out of mixtures of different key layers always outperform homogeneous architectures.
StripedHyena showed that interleaving architectures was superior to having the same structure in every level of a deep neural net. A mixed model apparently helps overcome a component architecture’s weaknesses while benefitting from its strengths, perhaps in the same way that an alloy can be stronger than its base metal components.
The space of possible architectures expands immeasurably with heterogeneous LLM configurations, so this opens up another dimension of LLM architecture optimization for AI researchers to explore.
The Mamba SSM architecture combined with transformers in a striped model that also uses a mixture of experts could be the best architecture yet. Whatever ends up working out the best, we haven’t seen the end of foundation AI model architecture innovation. AI in 2024 will be very interesting.
A Note to Readers
I try to write to a technically-literate general audience, but there are articles, like this one, where I struggle giving sufficient correct technical content without getting readers lost. Whether I am hitting the mark or missing the mark with these articles that dive into AI research, let me know. I’d love the feedback.
What I really struggled to understand in the original Mamba paper was the math (hard to figure out the dimensions of the variables involved). It's interesting to see the history of SSMs, though I'm still on the lookout for a simple explanation of the layer-by-layer math involved. It'd be great to see an article on that!