
Claude 3 Released - It's A New AI Model Leader
Claude 3 beats GPT-4 on benchmarks and raises the bar on AI reasoning


AI Model Race Update: Claude 3
Only last week, I gave an “LLM update Q1 24” update, mentioning Mistral Large and other GPT-4-level competitors. I knew then that events would supersede the update, but I didn’t expect a big release just days later.
This is a big release indeed: Anthropic released Claude 3.
Claude 3 is model family consisting of three models in ascending order of capability: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus. You can think of Haiku, Sonnet and Opus as a creative label for its small, medium and large model sizes, similar to how Gemini is broken into Nano, Pro and Ultra.
Claude 3 is multi-modal, reading and interpreting image inputs, and is also multi-lingual, performing very well on the multi-lingual MMLU. As such, it competes on the same ground as GPT-4 vision and Gemini 1.0 Ultra.
Is Claude 3 a GPT-4 beater?
The immediate question that comes to mind with a new frontier model like Claude is how it stacks up against competition. Their release announcement included their own collation of benchmark results. In it, Anthropic touts how Claude3 Opus beats GPT-4 on all benchmarks.
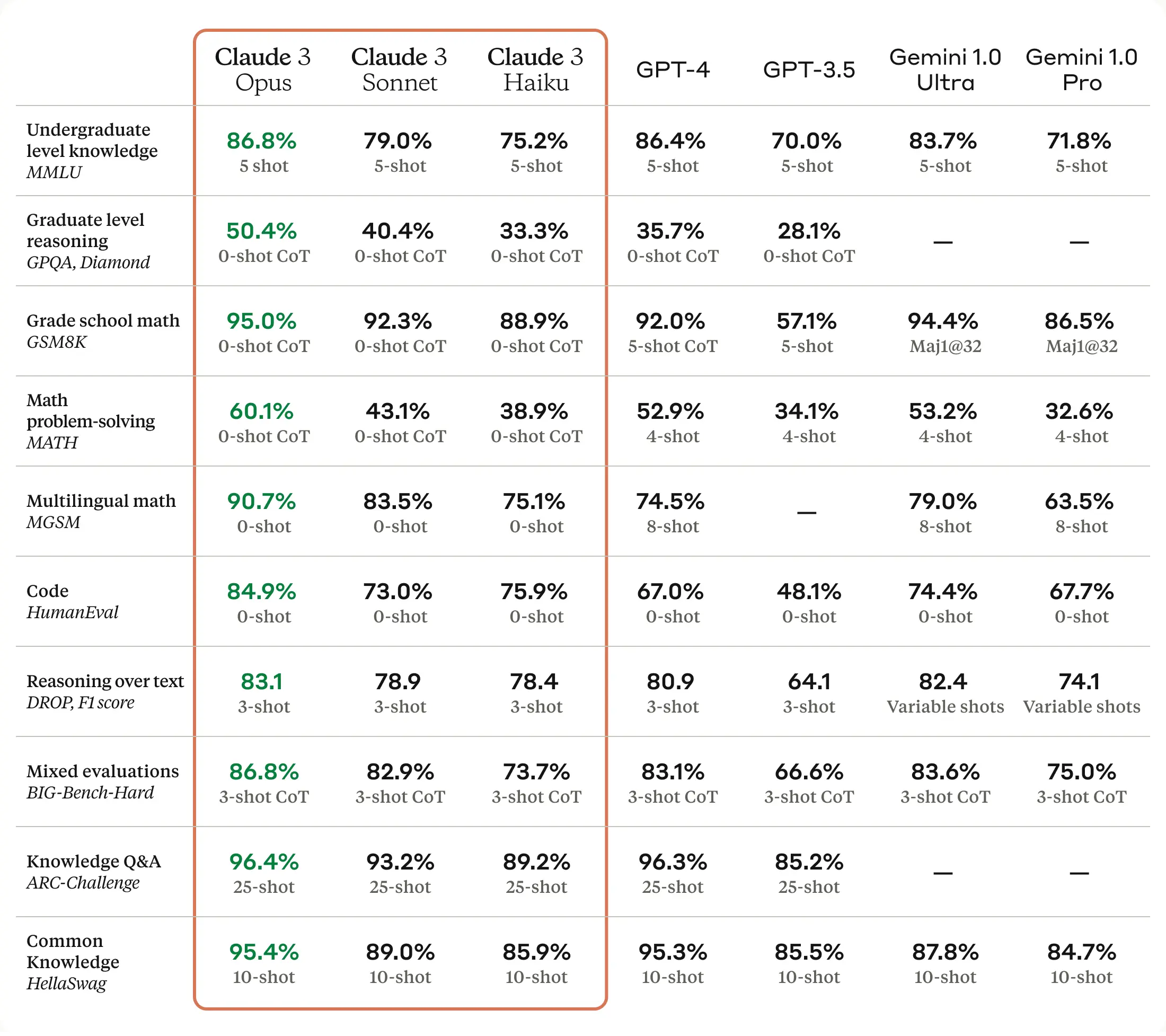
While their largest Claude 3 Opus model beats GPT-4 overall, even their smallest model is quite capable: Haiku beats GPT3-5 on all benchmarks, beats Gemini 1.0 Pro overall, and manages a HumanEval above GPT-4.
The Claude 3 benchmark chart is comparing to GPT-4, not GPT-4 Turbo, and the yet-to-be-released Gemini 1.5 Pro is not in the comparison chart either. Despite that, this is impressive indeed. We can say that, indeed, Claude 3 Opus is a better-than-GPT-4 foundation AI model.
“A new standard for intelligence”
One thing that jumps out is how well Claude 3 Opus does on HumanEval, GMS8K, and on math problem-solving overall. Claude 3 Opus an across-the-board cut above, beating GPT-4 on math, reasoning, and code benchmarks across the board. This raw reasoning and coding capability is vitally important for use in AI Agents.
Human Eval of 84% basically makes it equivalent to a top-tier human coder. While some fine-tuning coding models and special iterative generation techniques beat this, it’s apparently the best HumanEval benchmark for a zero-shot base-level foundation model.
Also noteworthy is the Claude 3 Opus performance on GPQA Diamond, achieving over 50% (0-shot, and 59% multi-shot) on this graduate-level reasoning benchmark. David Rein, the creator of this benchmark dataset, was blown away by how well Claude 3 did.
Claude 3 gets ~60% accuracy on GPQA. It's hard for me to understate how hard these questions are—literal PhDs (in different domains from the questions) with access to the internet get 34%. - David Rein on X
Anthropic claims their Claude 3 Opus possesses “near-human levels of comprehension and fluency on complex tasks, leading the frontier of general intelligence.” We should caveat that benchmarks are imprecise and have flaws, but that aside, Claude 3’s solid benchmark results back up these bold claims.
Bottom-line, Claude 3 Opus is setting a new standard.
Claude 3 Features
The high-level announcement claims for the Claude 3 models are:
Near-instant results: They claim Claude 3 Sonnet is twice as fast as Claude 2, while Opus is as fast as Claude 2, with high intelligence. And Haiku is even faster:
“Haiku is the fastest and most cost-effective model on the market for its intelligence category. It can read an information and data dense research paper on arXiv (~10k tokens) with charts and graphs in less than three seconds.”
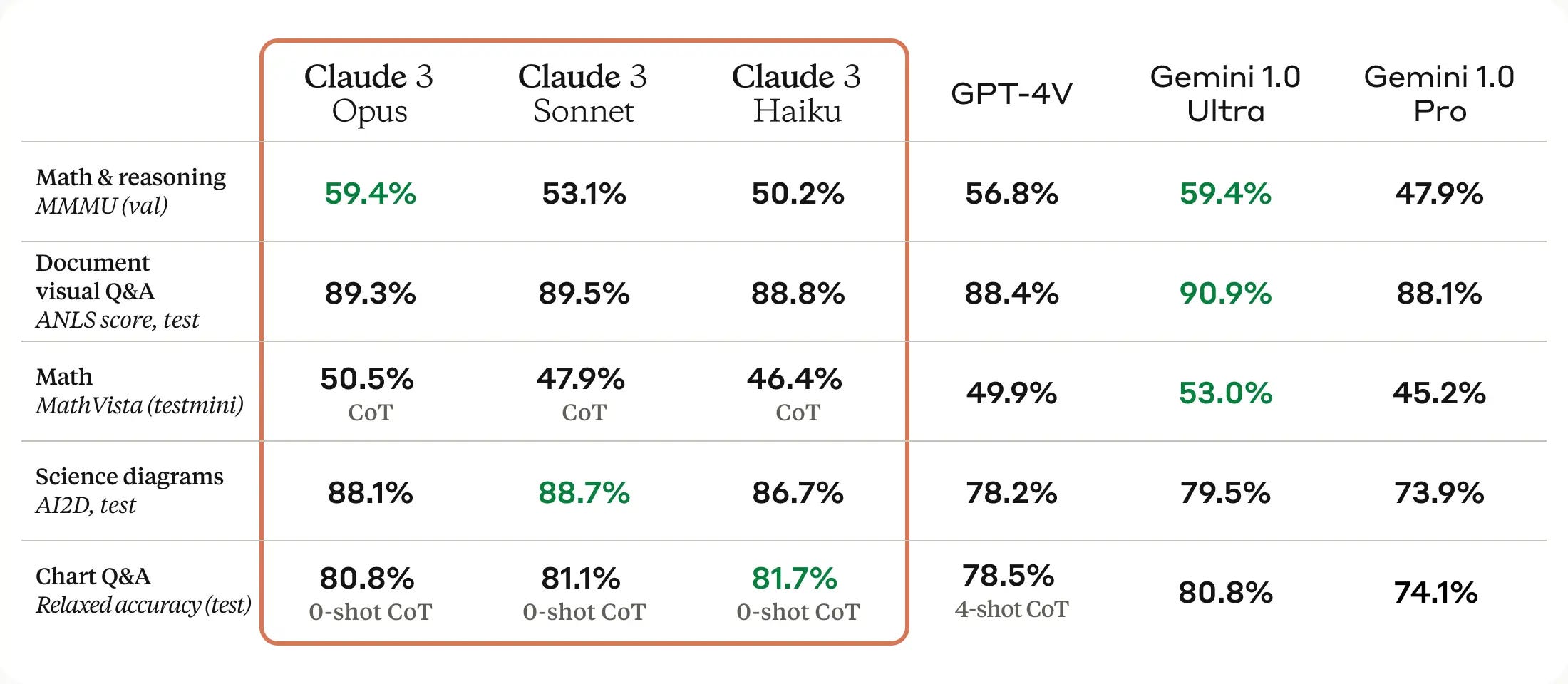
Strong vision capabilities: They stack up Claude 3 against GPT-4 and Gemini 1.0 Ultra, and Claude 3 holds its own, but Gemini 1.0 Ultra is the best overall.
Fewer refusals: Anthropic’s core claim-to-fame is “constitutional AI” that is inherently safe, but being overly ‘safe’ by refusing reasonable requests becomes dis-utility. “Claude 3 models show a more nuanced understanding of requests, recognize real harms and refuse to answer harmless prompts much less often.”
Improved accuracy: LLMs have struggled with hallucinations, and Anthropic claims strides in making Claude 3 less prone that. “Compared to Claude 2.1, Opus demonstrates a twofold improvement in accuracy (or correct answers)”
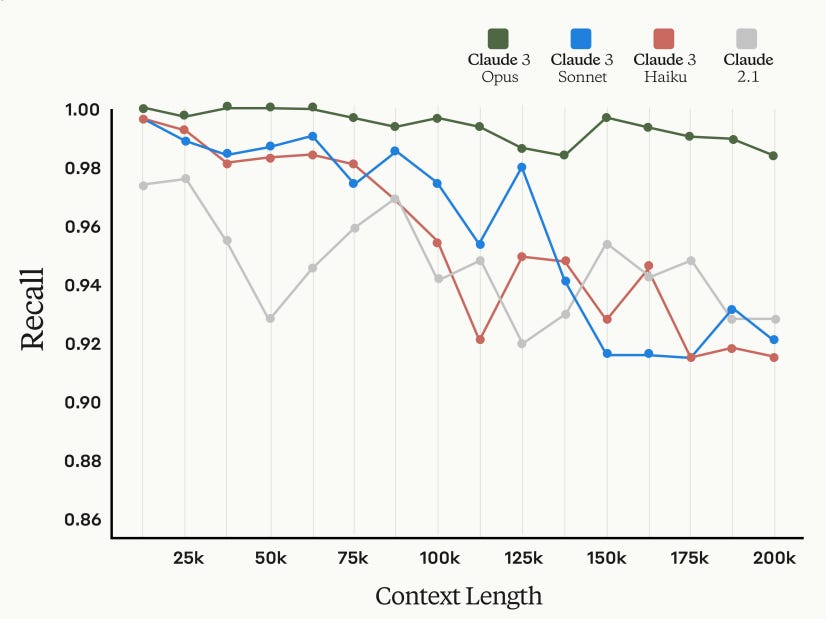
Long context and near-perfect recall: Claude 3 has a generous 200K context window (equivalent to two large books or more), with highly accurate recall in that window.

Figure 4. Recall over 200k context window for Claude 3 Opus, Sonnet and Haiku vs Claude 2.1. Opus has near-perfect recall.
Finally, they make a pitch to enterprise users and others embedding their AI model in their workflow:
The Claude 3 models are better at following complex, multi-step instructions. They are particularly adept at adhering to brand voice and response guidelines, and developing customer-facing experiences our users can trust. In addition, the Claude 3 models are better at producing popular structured output in formats like JSON—making it simpler to instruct Claude for use cases like natural language classification and sentiment analysis.
Anthropic also mentioned adding desired features to their AI model to make them more useful for enterprise and work-flow capabilities, including “ Tool Use (aka function calling), interactive coding (aka REPL), and more advanced agentic capabilities.”
Anthropic shared the Claude 3 model card with further details on the model performance. As with other proprietary AI models, we are not told about the AI model internals, with no details on its architecture, training dataset, or training process. Rather, there is much on benchmarks, safety, bias and responsibility.
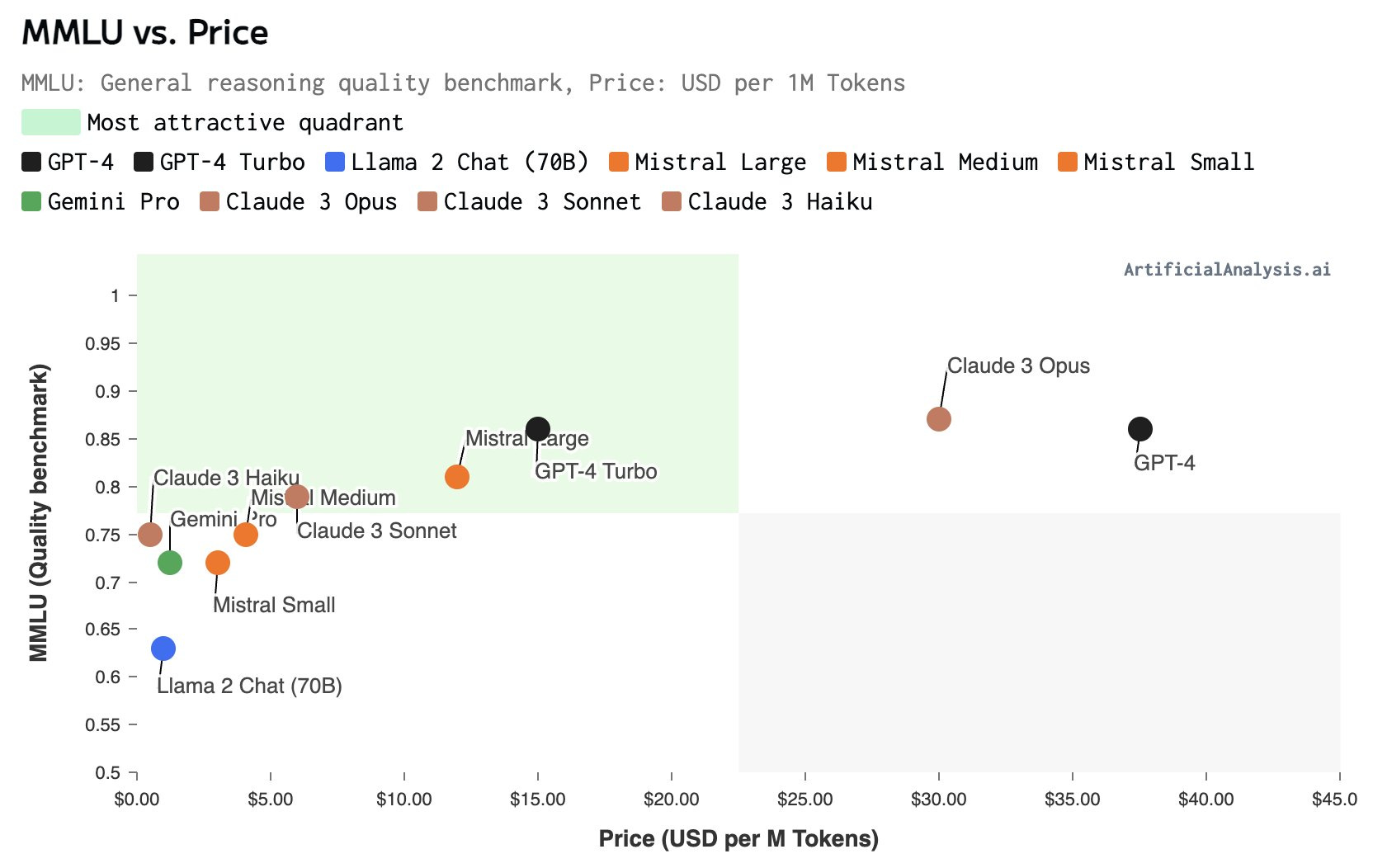
Claude 3 Cost Comparisons
Most AI model makers are now pricing their APIs based on $ per million tokens, so we directly compare the cost of AI model API access:
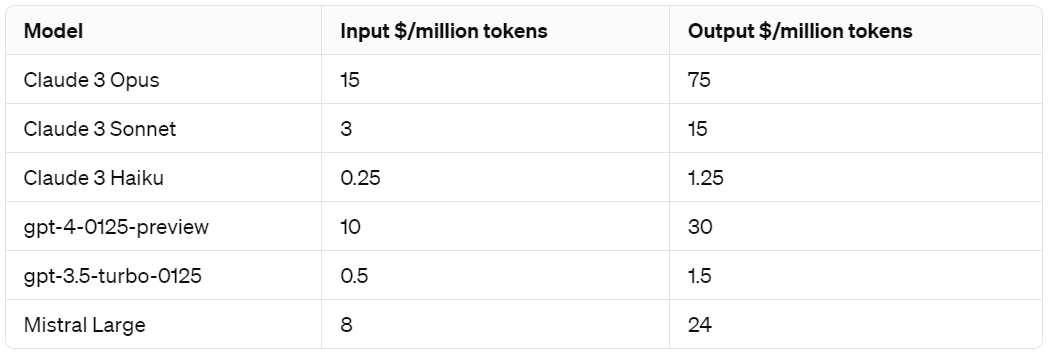
All three Anthropic AI models seem to be quite competitive right now. While Claude 3 Opus is most expensive, it perhaps earns that premium from it superior intelligence. Haiku in particular is quite cost-effective. It’s both better and currently cheaper than GPT3-5.
This analysis shows how Claude 3 compares with other AI Models in price versus performance, using MMLU as the metric.
The Next AI Model to Drop
Anthropic’s Claude 3 is a great AI model suite. It will take more real-world usage to confirm its performance, but Claude 3 Opus may be the best AI model available, besting GPT-4 overall.
This raises the bar and makes the AI model market more competitive than ever. Releasing this AI model is an important milestone, but more such releases will follow. It’s only a matter of who and when:
Google’s Gemini 1.5 Pro was pre-released and it’s so good we can expect Gemini 1.5 Ultra to be world-beating.
Meta’s Llama 3 was pushed backed to July. That’s a pity, because it would be great to see an open AI model that is GPT-4 level or beyond.
Chinese AI model makers have been able to produce highly efficient AI models, including some of the best open AI models, such as Yi VL 34B, etc. Will they produce a GPT-4-level AI model soon?
OpenAI trained GPT-4 two years ago, generations ago in AI terms. GPT-4 has stood the test of time. Surely, OpenAI has a newer GPT-4.2 or GPT-5 either in training now or past that, ready for the right time to be released.
AI keeps getting better, cheaper, and faster at a fast clip. I can’t wait for the next shoe to drop, but in the meantime, I will be adding Claude 3 to my go-to list of AI models.
We do not believe that model intelligence is anywhere near its limits.” -Anthropic
Matthew Berman ran a comparison on chatbot arena with GPT-4 -- and GPT-4 came out slightly ahead.
The good news, of course, is that OpenAI may be encouraged to release a significant update to blow away Claude 3, as they did with Sora's release just a couple/few hours after the release of Gemini 1.5 Pro. However, maybe it won't be a frontier model release, but something akin to Sora: glitzy, but not really an apples-to-apples comparison with Gemini 1.5 Pro.