
LLM update Q1 24: Mistral Large Enters Le Chat
The race to beat GPT-4 heats up with Mistral Au Large, Smaug 72B, Qwen 1.5, Code Llama 70B, Gemini 1.0 Ultra, and more.


We Have Some Really Great New LLMs
That’s it. That’s the article.
Let’s put things in perspective. Just two months into 2024, we have a number of new LLMs that weren’t available on New Years:
CodeLlama 70B: Released at the end of January, CodeLlama-70B-Instruct achieves 67.8 on HumanEval. This is the best HumanEval result for an open AI base model, although there are coding model fine-tunes (see below) that are beating this and GPT-4 performance.
Qwen 1.5: Qwen models, a series of open source Chinese-English multilingual AI models from 0.5B to 72B parameters, are being developed by Alibaba. Released in early February, the Qwen 1.5 72B parameter model is currently the most performant open LLM, with an MMLU benchmark of 77.2, as well as impressive standing on the Lmsys leaderboard.
Gemini 1.0 Ultra: 1.0 Ultra’s release in early February from Google finally gave us a true match for GPT-4 and possibly the highest-performing AI models out there now. Just don’t ask it to create images of Founding Fathers right now.
Mistral Large: Released February 26, this hot-off-the-press LLM is in the near-GPT4 tier with many impressive features. We will discuss Mistral Large below.
We shared a preview of Google Gemini 1.5 Pro and its expanded context window length of 1 million tokens and how it outperforms Gemini 1.0 Ultra. However, while Gemini 1.5 is possibly the best AI model in the world, we don’t know yet; it is only available for a limited release, so it can’t be listed as an available AI model.
There continues to be a large number of releases and constant innovation and improvement on the LLM fine-tuning front. Some notable ones:
Smaug 72B: “Smaug-72B is finetuned directly from moreh/MoMo-72B-lora-1.8.7-DPO and is ultimately based on Qwen-72B.” Smaug 72B is currently number one on the HuggingFace open LLM leaderboard, with an MMLU benchmark of 77.15. As explained in “Smaug: Fixing Failure Modes of Preference Optimisation with DPO-Positive,” Smaug got its best-in-class performance by pioneering a novel form of DPO to improve model fine-tuning, called DPO-Positive.
OpenCodeInterpreter: This open source AI coding model is based on a capable DeepSeek 33B coding model, then fine-tuned on a dataset of 68K multi-turn interactions called Code-Feedback. With appropriate feedback, OpenCodeInterpreter-DS-33B achieves HumanEval performance of 83.2, comparable to that of the GPT-4 and “further elevates to 91.6 (84.6) with synthesized human feedback from GPT-4.”
LoraLand takes the idea of fine-tuning to the extreme, with a collection of dozens of domain-specific fine-tuned models that outperform GPT-4 on various specific tasks.
When it comes to AI models for coding, the best-in-class research result is shown on this Code Generation Leaderboard on PapersWithCode website. “Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models” achieved a staggering 94.4 score on HumanEval for programming.
This paper achieved this result by creating LATS (Language Agent Tree Search), a framework that employs GPT-4 LLMs as agents to perform planning, acting, and reasoning, by using external feedback to guide it to adaptively solve for given tasks. This result, OpenCodeInterpreter, and Google DeepMind’s AlphaCode2 (which gets 85% on HumanEval) all show iterative feedback as essential for high-performing AI coding.
Mistral Large
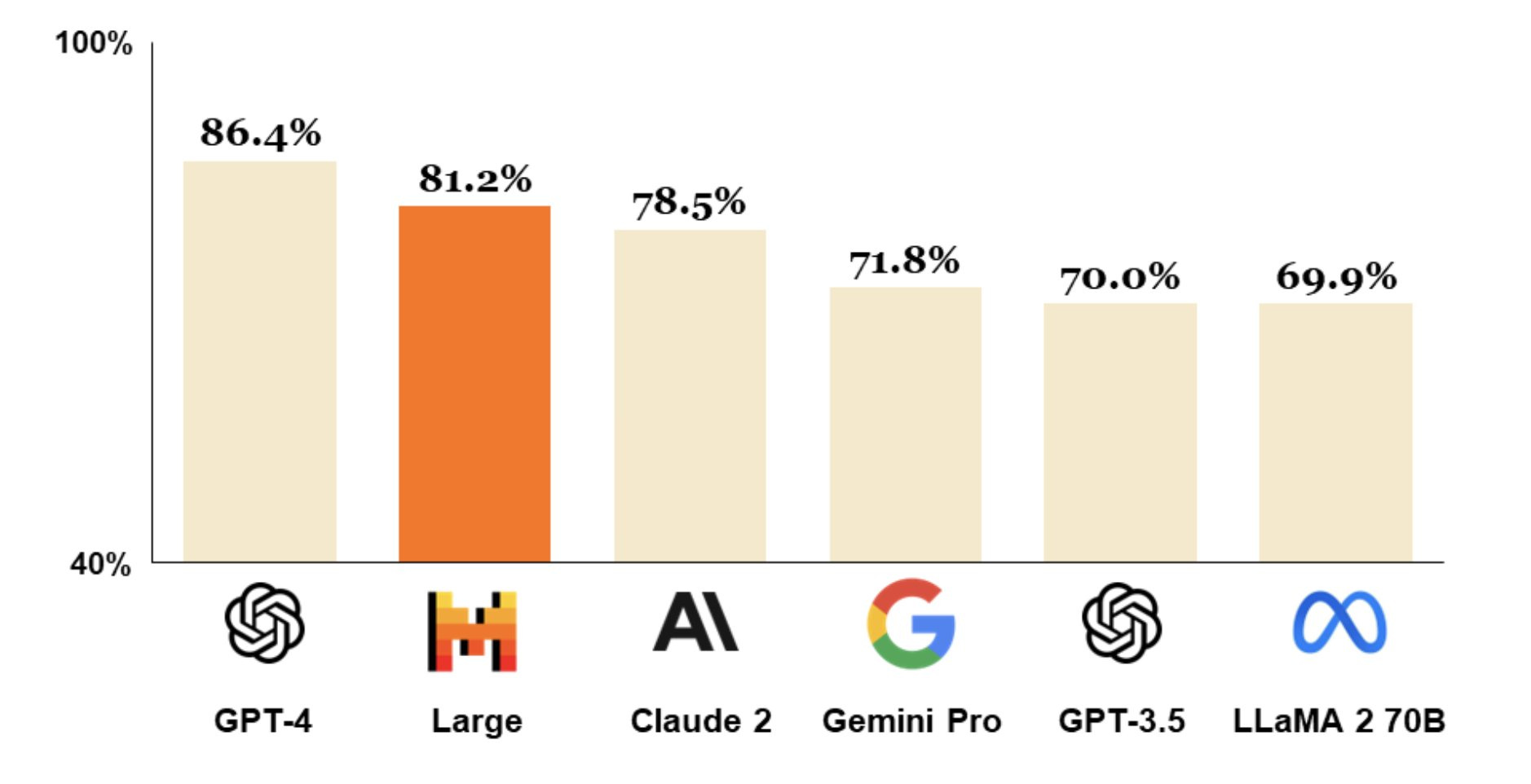
Mistral “Au Large” was announced and released, and it’s impressive. It has a 32k context window, and they claim it has “top-tier reasoning capacities” and is “natively capable of function calling.” It has an MMLU benchmark of 81.2%, surpassing all other foundation models except GPT-4 and Gemini Ultra.
Notable features include flexibility in moderation policies, where its “precise instruction-following enables developers to design their moderation policies.”
It is also natively fluent in English, French, Spanish, German, and Italian “with a nuanced understanding of grammar and cultural context.” As a Paris-based AI company, they are intent on serving the European market, and Mistral’s AI models seem to deliver on that well, with MMLU scores near 80% across French, German, Spanish and Italian.

Further, as announced by Mistral Co-Founder Guillaume Lample on X:
We have also updated Mistral Small on our API to a model that is significantly better (and faster) than Mixtral 8x7B. Lastly, we are introducing Le Chat (https://chat.mistral.ai), a chat interface (currently in beta) on top of our models.
Overall, Mistral Large seems to be a quite capable model. Although not matching nor beating GPT-4, Mistral has changed the game.
Is Mistral Now a Closed Shop?
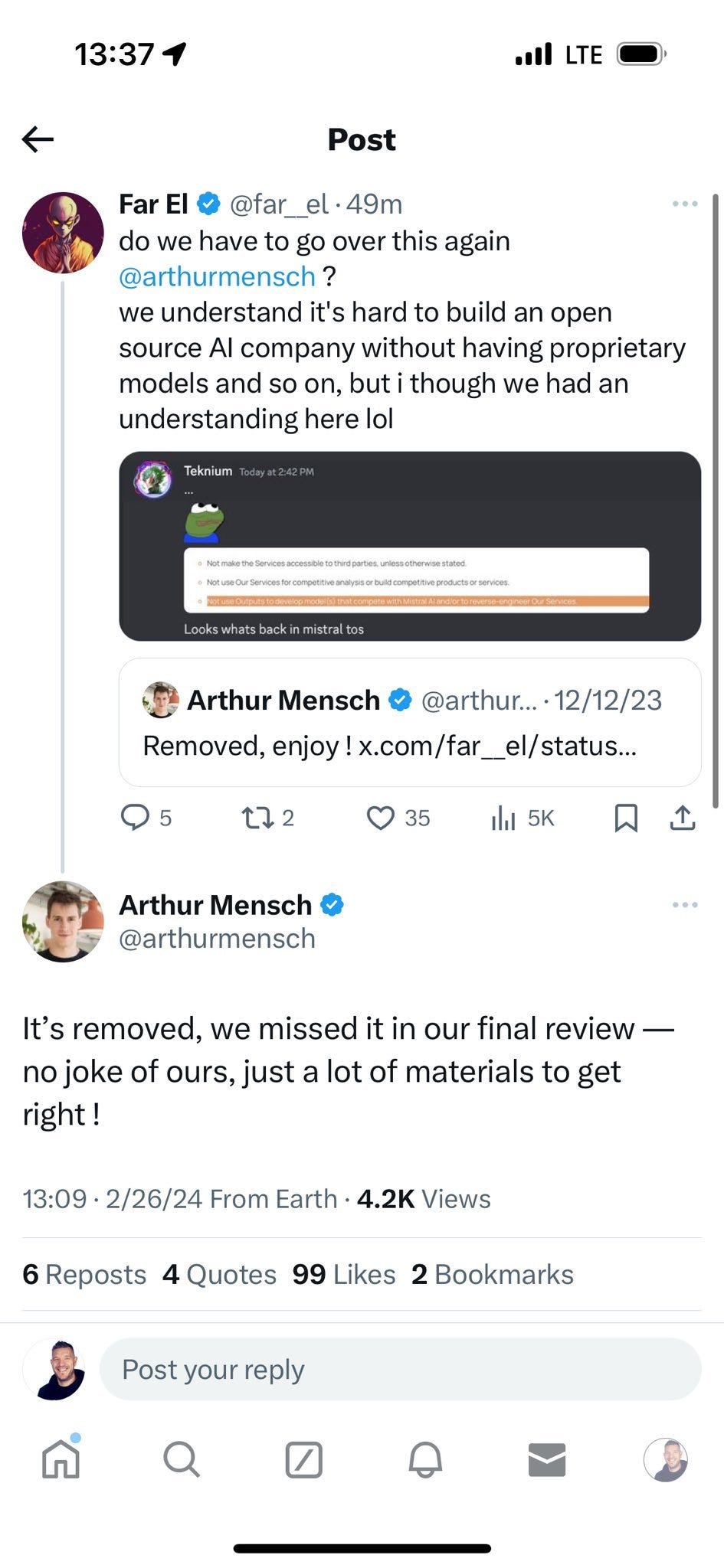
This big disappointment of this announcement is that it is not an open AI model. Mistral had earlier been innovative in what they released and how they released it, giving two great open AI models, both very capable for their size.
However, as noted by TechCrunch in their report on the Mistral Large release:
Mistral AI’s business model looks more and more like OpenAI’s business model as the company offers Mistral Large through a paid API with usage-based pricing. It currently costs $8 per million of input tokens and $24 per million of output tokens to query Mistral Large.
This model brings Mistral closer to Microsoft, as they are hosting their AI model on the Azure platform and Microsoft invested $16 million into Mistral in a recent deal.
Some alert users noted that Mistral had re-inserted a restriction against model reuse, but that’s been removed. We are eagerly awaiting a GPT-4-level open AI model, which would open the doors to a plethora of better-than-ever fine-tunes and better AI agents based on these better AI models.
Best Models for Daily Use
Much has changed, but one thing has not: GPT-4 is still the king. Sure, the GPT-4 tier is getting competitive: Gemini 1.5 pro, Mistral Large, etc. Yet despite all these great new AI models, its stunning that GPT-4, trained in 2022 without the advantages of optimizations that other AI models have used since, is still leading.
So AI model users have these options for day-to-day AI model use:
Stick with the OpenAI’s ChatGPT, with GPT-4 under the hood. For $20/month, you can access to GPT-4 Turbo, with vision, Dalle-3, browsing extension, data analysis and custom GPTs.
Microsoft’s copilot.microsoft.com offers access to GPT-4 without the $20 subscription. A bonus is their Dall-e 3 AI image generation connects to their
Google’s Gemini Ultra interface has a free trial for 3 months, then will cost $20/month. Try before you buy.
Try out Mistral’s native Le Chat interface at chat.mistral.ai.
There are ways to get free access (sometimes rate-limited) to these and other leading AI models like Claude, including the Poe interface.
It pays to be agnostic and try multiple AI models, as different models are just better at some questions than others.
AI model APIs keep getting cheaper
If you are an AI app builder, the AI models are getting cheaper and the choices are getting wider:
MistralAI Large: $8.00 per M tokens for input and $24.00 per million tokens for output.
OpenAI GPT-4 Turbo: gpt-4-0125-preview currently costs $0.01 per 1K tokens for input and $0.03 per 1K tokens for output.
Google Gemini 1.0 Pro: Text input costs $0.000125 per 1000 characters, text output costs $0.000375 per 1000 characters.
All 3 price their API differently, but comparing at a per million token level, OpenAI would be $10 and $30 per million token for input and output, so MistralAI is offering their API at about 20% below GPT-4.
Google pricing based on characters not tokens is different, but it translates into about $0.75 and $2.25 per million tokens input and output. Gemini Pro 1.0 is quite a bit cheaper, but it’s not as capable. We’ll have to see if pricing remains when they move up to higher-performing Gemini 1.5.
LLM Efficiency
The recently released Gemma 7B was remarkable in one respect: It was a 7B trained on 6 trillion tokens of data. That ratio of a 1,000 tokens per model parameter is way above “Chinchilla scaling,” but higher ratios are needed to obtain the best possible model at any given size.
It’s likely Mistral has gone this far, if not further, as their AI models have all been very capable for their size. Better AI model efficiency translates to lower inference cost for a given quality level of AI.
Sebastian Bubeck, of “Sparks of AGI” and Phi models fame, has noted that “from what I am seeing, room for reasoning part to get to 13B.” In other words, good training data and compute can yield GPT-4 level reasoning even in 13B models.
Expect more strides on the LLM efficiency front, which will translate into cheaper API pricing for more smaller yet more capable models.
Summary
The 2024 Q1 status leaves OpenAI’s GPT-4 still holding its own while many other competitors pump out AI models that are getting better at a fast clip.
A risk of these AI model updates is the pace of progress is so rapid, that any update would get rapidly obsoleted. So be it. I expect Google, Anthropic, Alibaba, Meta and OpenAI ALL to release something to obsolete prior best-in-class LLMs in the next 3 months. We update on it when they do.
Will OpenAI themselves respond and leapfrog the competition still trying to best GPT-4?
Or will this meme become reality someday?

Postscript. Benchmarks are … variable
While we use benchmarks to get a quick assessment of where AI models stand, there are a number of problematic aspects to benchmarks. There are known errors in some benchmark tests (like MMLU), and benchmark data can pollute training data, yielding skewed results. There is also a problem of training to the test-set, reward-hacking your way to great benchmark results but yielding an AI model that is useless otherwise.
Beyond that, since AI models have non-deterministic outputs, small changes in testing setup can yield varied results. Florian S on X notes wide discrepancies of the MMLU score for GPT-4. One assessment judged GPT-4 Turbo to have an MMLU of 80.4%, while another rated it at 86.4%. We should be cautious therefore in drawing conclusions based on small changes to any benchmark, including MMLU.

Benchmarks are a good starting point for understanding how good an LLM performs, but true utility comes down to personal experience on your use-cases. So it helps to remain agnostic, try them all, and see what works for you.