
DeepSeek Releases R1 and Opens up AI Reasoning
DeepSeek open-sources R1 and shares how they trained their AI reasoning model. There is no moat.


DeepSeek’s Bombshell R1 Release
DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks. - DeepSeek R1 Technical Report
This week, the Chinese AI lab DeepSeek dropped an important new release, DeepSeek-R1, an AI reasoning model that matches the performance of OpenAI’s o1. With this release, DeepSeek has shaken up the whole AI world and challenged established players like OpenAI.
DeepSeek-R1 is an AI reasoning model that is based on the DeepSeek-V3 base model, that was trained to reason using large-scale reinforcement learning (RL) in post-training. The resulting R1 model's performance is stellar, matching OpenAI’s o1 in performance across various benchmarks: 79.8% on AIME 2024; 71.5 on GPQA diamond; 97.3% on MATH-500, etc.
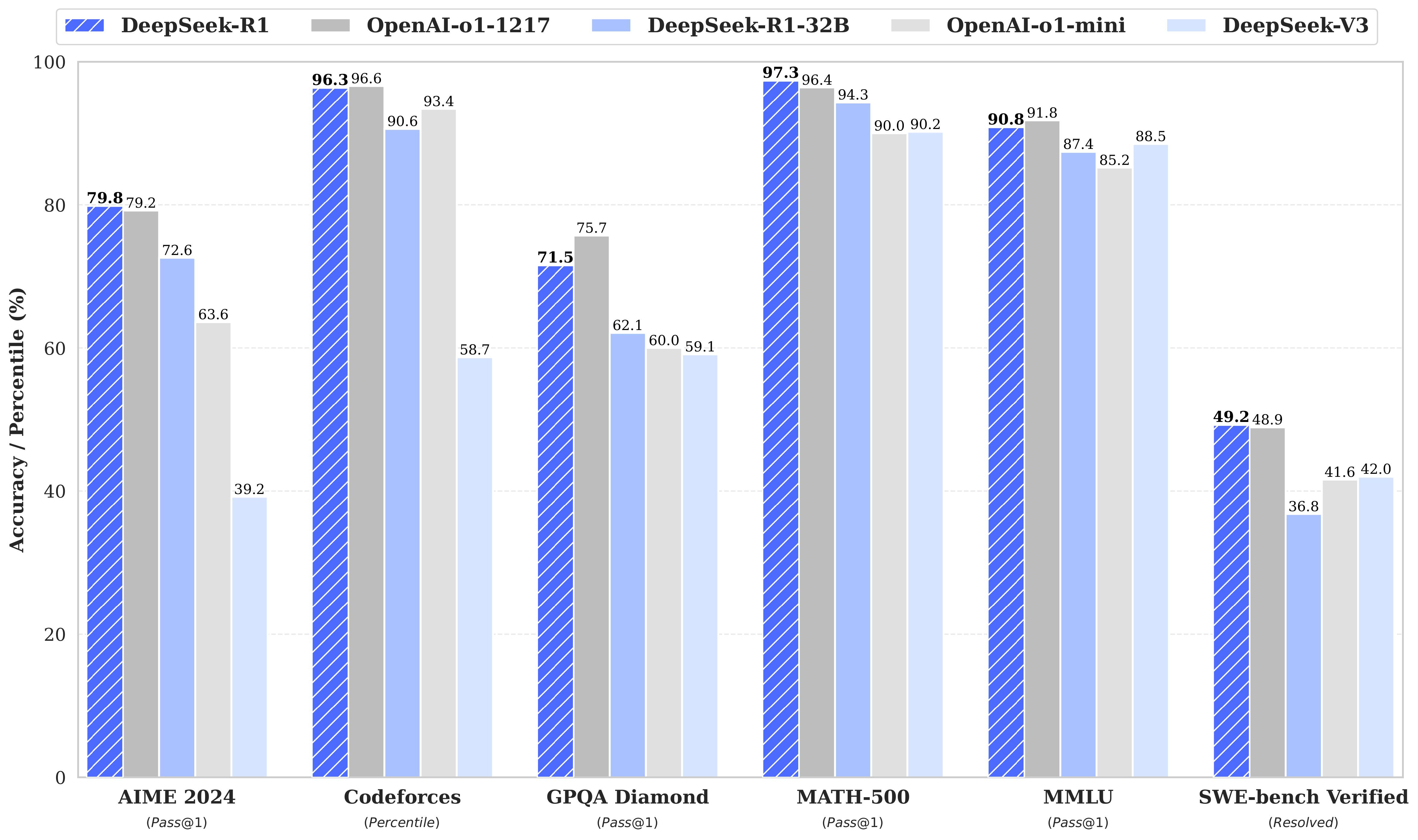
In addition to its superior performance, DeepSeek-R1 is open source, with a generously open MIT license; it also has transparent reasoning traces and costs a fraction of o1 pricing to run (as much as 96% lower cost per token to run). This release has made o1-level AI reasoning models more accessible, more open, and far cheaper.
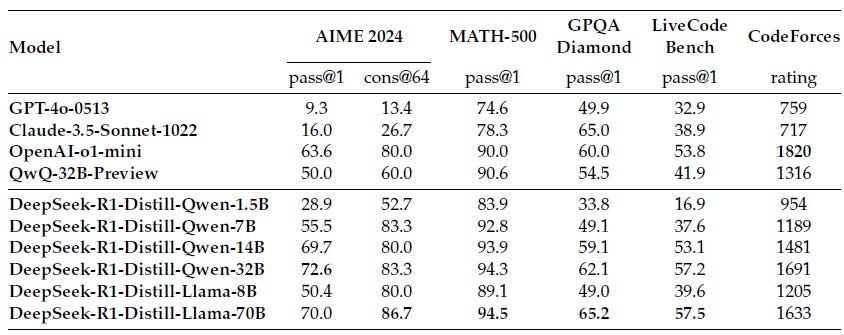
DeepSeek also released DeepSeek-R1-Zero, a first iteration of their AI reasoning model, which was trained to reason with RL without supervised fine-tuning (SFT). They also released smaller open-source reasoning models based on Llama3 and Qwen2.5 models and distilled from DeepSeek-R1, at assorted sizes: 1.5B, 7B, 8B, 14B, 32B, and 70B.
These distilled models bring AI reasoning to the edge. In particular, DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for AI models that can be run locally.
The R1 Technical Report and R1 Training Pipeline
The challenge of effective test-time scaling remains an open question for the research community. - DeepSeek R1 Technical Report
DeepSeek also released a Technical Report on the R1 model, covering the R1 architecture, training process and benchmark results, in “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” In sharing their secret sauce, they have opened up AI reasoning.
In the report, they describe how to develop R1, they first developed DeepSeek-R1-Zero, which was developed by training on RL for robust reasoning capabilities without any supervised fine-tuning data. This unique approach, where the model learns to reason through pure reinforcement learning without initial examples, yielded remarkable results.
The self-evolution process of DeepSeek-R1-Zero is a fascinating demonstration of how RL can drive a model to improve its reasoning capabilities autonomously. By initiating RL directly from the base model, we can closely monitor the model’s progression without the influence of the supervised fine-tuning stage.
While DeepSeek-R1-Zero showed the power of RL for developing reasoning capabilities, the R1-Zero model suffered from flaws in text generation, poor readability, and language mixing.
The DeepSeek team learned from this experience and went through a second training process to determine and implement a better training pipeline. That revision led to DeepSeek-R1, which incorporates a cold-start process and a multi-stage training pipeline during post-training.

The full training pipeline looks something like this:
1. Pretraining: DeepSeek-R1 starts with the pre-trained DeepSeek-V3 base model.
2. Cold-Start Supervised Fine-Tuning: They collect thousands of structured Chain-of-Thought (CoT) examples as “cold start” data, and the model is fine-tuned on this dataset of examples to establish a stable starting point. This helps address issues like language mixing and readability observed in training the DeepSeek-R1-Zero model.
3. Reasoning-oriented Reinforcement Learning: This phase is done as was done with DeepSeek-R1-Zero. The system generates multiple reasoning trajectories and selects the best-performing ones to guide further training. The Generalized Policy Optimization (GRPO) algorithm is implemented to optimize reasoning rewards, which involves introducing rewards for language consistency and accuracy across various benchmarks.
4. SFT with rejection sampling: Upon nearing convergence in the RL process, they create new SFT data through rejection sampling on the RL checkpoint, combined with SFT data from DeepSeek-V3 to improve the model in domains such as writing, factual QA, and self-cognition. The curated SFT dataset of 800k is run to fine-tune the model further.
5. Second RL pass: After SFT with the new data, the checkpoint undergoes an additional RL process, taking into account prompts from all scenarios, with both reasoning and non-reasoning ones.
It’s also worth noting what’s not in the pipeline. There’s no direct MCTS (Monte Carlo Tree Search) algorithm; any search is learned via the RL training implicitly. Further, they have a simple reward function in the RL – accuracy rewards (is it right or not) and format rewards. They say:
We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because we find that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process.
The DeepSeek team is very innovative, and they developed improvements in the RL reward functions and the post-training pipeline to develop AI reasoning capabilities. Their approach leans on RL to develop strong reasoning capabilities without relying heavily on supervised fine-tuning (SFT). The RL process in turn is general, simple, and not very costly.
At the same time, RL and SFT post-training steps are not fundamentally new. This breakthrough simplifies the process to get to AI reasoning and it can be easily copied and applied. It will be possible to train practically any good LLM base model into an exceptionally good AI reasoning model.
Why R1 Changes Everything
DeepSeek’s release of DeepSeek-R1is perhaps the most significant open-source AI model release since Meta first released Llama. It’s not just because DeepSeek R1 is a state-of-the-art AI reasoning model. With this DeepSeek-R1 release, DeepSeek has not only delivered an open-source o1 equivalent, but they have also shared the recipe to make it, opening the door to an abundance of AI reasoning models.
This release will spark acceleration of AI progress; let’s consider the ways.
DeepSeek is a cracked team, but the company is not even one of the top 7 AI labs: Google, OpenAI, Meta, Anthropic, Grok, Alibaba/Qwen, Mistral. Maybe we would place them number 8 or 9. Yet they punched way above their weight with these recent releases. If they can do this, what can the bigger players do?
By releasing their AI reasoning models as open-source, DeepSeek has democratized access to AI reasoning models. They released it fully open-source (not just open-weights) under the MIT license, which permits free distillation and commercial use. This level of accessible access will foster collaboration and innovation. Expect many fine-tunes, distillations, and other improvements of R1.
DeepSeek pricing to run these models is one-tenth what OpenAI charges for o1. Moreover, distilled R1 models, like DeepSeek-R1-Distill-Qwen-32B, can be run locally yet perform at a level close to R1 (and close to o1). All this improves low-cost access to AI reasoning.
By releasing technical details, DeepSeek has democratized the building of AI reasoning models. Now, every AI lab, if they hadn’t figured it out already, knows the R1 recipe for making AI reasoning models. It’s not even difficult.
Nor will (o1-level) AI reasoning training cost much. DeepSeek creatively managed to build DeepSeek-V3 itself for only around $5 million, and the training of R1 overall cost just $5.6 million. Unlike the Aschenbrenner scenario of needing a trillion-dollar cluster to compete, smaller players with access to smaller amounts of capital will be able to produce competitive AI reasoning models.
If there was a moat for AI reasoning models, it’s gone. There is no moat.
We opined in the recent article, The Meaning of O3:
These AI model releases [competitors of o1 such as Gemini 2.0 Flash Thinking Qwen QWQ] show that AI reasoning models can be implemented as extensions of existing frontier LLMs, further trained to exhibit CoT reasoning. The transparency about AI reasoning model architectures and their reasoning process gives us clearer insights into AI systems that can reason effectively. This openness will accelerate AI progress.
The DeepSeek-R1 release has poured gasoline onto this acceleration.
Conclusion - Reactions and Running R1
Early reviews and reactions on DeepSeek-R1 have been mostly positive, with some caveats and concerns. In general, real use of R1 suggests that it lives up to its claims of o1-level AI reasoning.
Matthew Berman found it “extremely impressive,” passing his coding and logic tests with flying colors. However, he also shared how this Chinese AI model is subject to Chinese censorship, refusing to talk about Tiananmen Square events or acknowledge Taiwan independence.
Another issue is that DeepSeek-R1 is great at reasoning but has limited features beyond reasoning, lacking “function calling, multi-turn, complex role-playing, and JSON output.” This will limit its utility in AI agent applications.
I downloaded the distilled R1-Qwen-32B model via Ollama to run on my local PC. So far, I’ve been impressed; it’s the most powerful AI model I’ve ever run on my machine.
DeepSeek’s R1 release has generated a lot of excitement in the AI community, for good reason. Aside from being a great open-source SOTA model, this release has democratized access to AI reasoning and opened the door to greater choice and competition in AI reasoning models.
The last word on DeepSeek-R1 goes to Dr Jim Fan, noting the power of cracked teams, RL and open source:
We are living in a timeline where a non-US company is keeping the original mission of OpenAI alive - truly open, frontier research that empowers all. It makes no sense. The most entertaining outcome is the most likely.
DeepSeek-R1 not only open-sources a barrage of models but also spills all the training secrets. They are perhaps the first OSS project that shows major, sustained growth of an RL flywheel. -Dr Jim Fan
Postscript. Google Updates Flash Thinking
Google just shared an update on Gemini 2.0 Flash Thinking, delivering an updated Gemini-2.0-Flash-Thinking model with better reasoning performance - AIME: 73.3%, GPQA: 74.2%, MMMU: 75.4% - and longer context:
We’re introducing 1M long context to this experimental update, enabling deeper analysis of long-form texts—like multiple research papers or extensive datasets. We’re also giving you tool use capabilities with the ability to turn on code execution in this model.
The AI reasoning race continues.