
Making RAG Work Better
Retrieval Augmented Generation (RAG) is powerful, but faces limitations. Improving RAG flow steps is enabling robust, production-grade RAG.


Introduction to RAG
RAG - Retrieval Augmented Generation - deserves special attention as essential to making LLMs truly useful, helpful and accurate. Done right, RAG helps LLMs reduce hallucinations and reliably share accurate knowledge and real-time information.
The basic concept of RAG is to find relevant information and present it in the context window of an LLM to help it correctly respond to a query. This is done in 3 steps:
Retrieve: The initial query is converted into a retrieval request to find relevant information from a store of data.
Augment: The retrieved information is added to the initial query as added context to make an augmented prompt.
Generate: The augmented prompt is sent to the LLM to get a final answer.
For example, to get a more accurate legal query answer, you would: Store legal citations in a database; query citations related to topics of the query; add relevant snippets found to the prompt; then the LLM would include correct citations in its response.
The retrieval in RAG extracts information from a vector database that can be quickly queried via a semantic similarity search, which means the data must already be stored in vector DB format. To make that work, documents we want available for use in RAG need to be converted (via an embedding model) into vector format and fed into the vector database. Figure 2 shows how document ingestion and the RAG flow work together.

You can go far with this basic RAG flow. However, applying RAG in real-world use-cases has exposed weaknesses, complexities and challenges of basic RAG, or “naive RAG” as it is called. Details such as how documents are ‘chunked’ and embedded, or how wide a net is cast to find or select information.
There’s a gap between just doing RAG and doing RAG well enough for reliable production use. To bridge that gap, additional techniques to embed data, query for knowledge, improve retrieval, and managing context have been developed, which we will cover below.
RAG at AIEWF
I reviewed many topics from last month’s AI Engineer World’s Fair in prior articles ( Part 1, 2 and Part 3 - infrastructure), but one topic I didn’t cover RAG. However, there were many helpful presentations and announcements covering advanced and production-ready RAG methods.
One of the most helpful presentations for me was Lance Martin of LangChain’s workshop presentation on LangGraph and agents. He broke down the challenges of building reliable agents, including various ways to improve RAG. While his presentation wasn’t recorded, his slide deck is here.

His presentation shared how LangChain and LangGraph support building RAG flows, and how they could address various RAG challenges and implement innovative ideas to improve RAG, such as:
Corrective Retrieval Augmented Generation (CRAG), which grades a retrieved piece of information on its relevance to the input, then optionally drops irrelevant information and conducts search to find external information, to improve the robustness of RAG.

Self-RAG, as presented in “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection,” has the LLM reflect on retrieved information, using special reflection tokens to judge its quality and utilize the information (or not). This self-reflection improves final response quality.
Adaptive RAG: Similar to the concept of routers that pick which LLM to send a query to (such as RouteLLM), adaptive RAG dynamically choses a RAG flow based on the type of user query. Adaptive RAG uses a classifier to assess the complexity of a query and selects the most suitable retrieval strategy accordingly. This improves efficiency and tailors the RAG process to specific query needs.

RAG in Production: Embedding
As RAG has moved into production flows, every step of the RAG flow needs to made more robust, across all steps of the embedding and RAG flows.
As part of the first step in setting up data for a RAG flow, an embedding model maps document text into a vector representation, to be stored in a Vector Database. Embedding models continue to evolve and improve, with Snowflake’s Artic Embed claiming to be best-in-class. Selecting an embedding model has many considerations, but for most standard uses, you can’t go wrong using OpenAI’s text-embedding-3-large) or a similar competing embedding model.
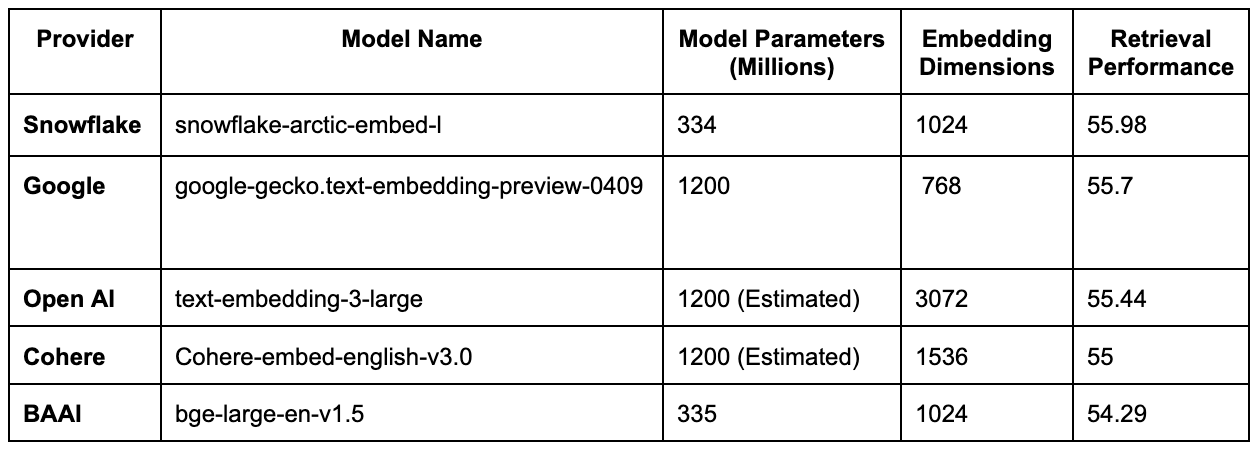
If your application is in a specific domain (such as healthcare or law), then domain-specific embeddings can improve the relevant quality of vector representations and subsequent retrieval of relevant context from the vector database. This AWS blog post explains how to Improve RAG accuracy with fine-tuned embedding models on Amazon SageMaker. Any open-source embedding model can be fine-tuned with sufficient domain-specific data.
RAG in Production: Chunking
Chunking divides a document into sections, and each section or chunk is encoded by an embedding model into a vector representation. A user query is matched using vector similarity against each chunk to determine which chunks, i.e., sections of a document, need to be retrieved in a RAG flow.
Determining the best chunk size has been a struggle in RAG, especially for LLMs with limited context windows. Small chunks are better for retrieval but bad for query response accuracy; conversely, a larger chunk size may cover a topic better, but lack precision. Typical chunk sizes range from 250 to 500 tokens, represented as a vector in a Vector DB.
Larger context windows for LLMs provide a way out of chunk size dilemma. We can decouple the chunked document representation from the returned information; have fined-grained vector representations, but post larger sections or full documents in the augmented context.
Unstructured provides tools to process documents for RAG; their platform preprocesses documents to text format and chunks based on sections for a ‘smart’ chunking results. Their blog article Chunking for RAG: best practices, explains chunking challenges and best practices in more depth.
When applying RAG in your domain, experiment with chunking sizes, embedding methods, reranking, and other RAG parameters and methods; what works best will depend on the use case.
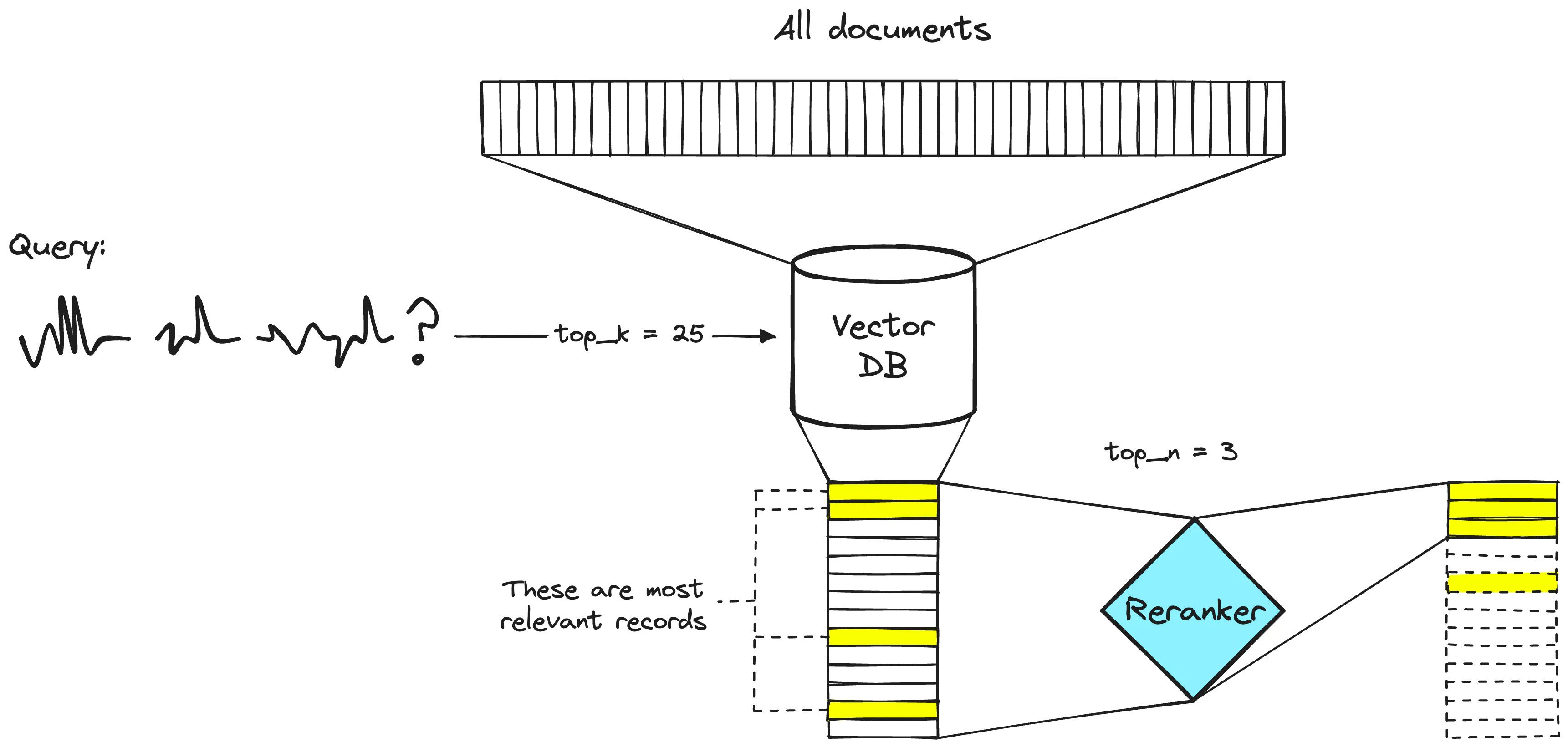
RAG in Production: Reranking
Reranking uses an LLM or classifier (such as a BERT model classifier) to take a second pass through information gathered via a vector similarity retrieval, to determine it value, relevance and correctness. This allows an initial relevance retrieval to cast a wider net, while having an accurate reranker give a more precise final answer.
The reranker qualifies data more accurately so it is more costly, but it is run on a small number of records, so the overall process is efficient.
RAFT: Adapting LLMs to domain-specific RAG
Fine-tuning a model by training it on a specific domain has been proposed as an alternative to RAG, but we’ve learned that fine-tuning for facts is not a good idea. Fine-tune to govern behavior or style, but leave the knowledge-grounding to RAG.
However, there is a way to use both: Retrieval-Augmented Fine-Tuning, or RAFT. Presented in a recent paper, RAFT combines RAG and Fine-Tuning to adapt LLMs to specialized domains. It works by fine-tuning models using RAG to recognize relevant information, thereby becoming more effective utilizers of the retrieved information in their context.

RAG Beyond Text - Multi-Modal RAG and GraphRAG
We have so far discussed RAG based on the documents comprised of text. However, much of stored data is either in a structured format (SQL, spreadsheets, etc.), or multi-media (video, audio, images).
LangChain has cookbooks to support multi-modal RAG, that covers the diverse data types of images, text, and tables and include a multi-vector retriever for RAG on documents with mixed content types.

Another promising approach is applying knowledge graphs to RAG aka GraphRAG. Graph Database provider Neo4j argue that a knowledge graph has semantic richness that makes it a superior source of real knowledge grounding for RAG. They share an implementation of it in Using a Knowledge Graph to Implement a RAG Application.
Microsoft has also recently gotten behind GraphRAG.
Getting LLMs Access to Data with SQL
At the AIEWF, GraphQL provider Hasura’s CEO Tanmai gave a talk about the complaint that “LLMs don’t talk to my data intelligently” and suggested using SQL as a unified query language to solve that problem.
He asks “What if everything was one query language - SQL?” If that becomes the common query language, then the way to get LLMs access to data is to get them to figure out the correct SQL queries. The LLMs can write python code to fetch the data we want, embed the correct SQL queries in the code, run the code, and get the data.
AI models might not follow this path exactly, but could follow the principle of determining the data request, then utilizing a programming language and code execution to wrap data queries. Such AI models could direct their own data interactions and run their own RAG-like flows.
Conclusion
RAG is a powerful method for grounding LLMs in knowledge, but making production grade RAG is complex and requires improvements to the RAG flow. We’ve discussed various components of RAG and improvements in the flow: Embedding, chunking, and reranking; corrective RAG, self-RAG and adaptive RAG; and multi-modal RAG and knowledge graph RAG.
As with AI models and other parts of the AI ecosystem, flows and tools are evolving and getting better at a fast pace. Initial problems with RAG have been addressed with various flow improvements. LLMs are much more powerful with knowledge than without, so RAG will become standard, even with large context LLMs. We will see RAG applied to many data-types.
RAG (Retrieval-Augmented Generation) has three types:
1. Frozen Model RAG: These models are widely seen across the industry and are primarily used for proof of concept (POC).
2. Semi-Frozen Model RAG: Intelligent retrievers are applied, attempting to adapt them in some way. The LLM is not modified; only the retrievers are operated and combined with the final output.
3. Fully Trainable RAG: End-to-end training is quite challenging, but if done correctly, it can provide optimal performance. However, it is certainly very resource-intensive.