
On Situational Awareness 3: Limits and ROI
Possible blockers on the path to Superintelligence in data and compute.


Situational Awareness
Our previous two articles on Leopold Aschenbrenner’s Situational Awareness dealt with the race to AGI and AI automation and acceleration feeding into Superintelligence. This article is about some potential blockers and limits on AI scaling and progress.
Aschenbrenner’s scenario of AGI in the near-term feeding into AI progress acceleration that moves us quickly into Superintelligence has several underlying assumptions behind it:
Scale is sufficient for AI capability progress. Add in enough OOMs, orders of magnitude, of compute and data, and higher-level AI capabilities will appear.
There will be enough data to feed these larger and more capable AI models.
We will overcome algorithm challenges and deliver AI algorithm and architecture breakthroughs to improve AI model performance.
There will be large compute investment increases, even up to the trillion dollar cluster.
What if the scaling peters out, the data runs out, the investment isn’t worth it, or the breakthroughs don’t occur? Aschenbrenner acknowledges possible blockers in Situational Awareness, but discounts their impact:
There are several plausible bottlenecks—including limited compute for experiments, complementarities with humans, and algorithmic progress becoming harder, but none seem sufficient to definitively slow things down.
Limits - Fundamental vs Practical
Do LLMs have some inherent limits? The surprise with LLMs has been that next-token-prediction has delivered capabilities beyond what we might expect. It’s likely there is an asymptote of LLM capabilities; we can’t get beyond perfection or below 0% perplexity.
However, as we extend LLMs into multiple modalities, empower them with tools, and make them more agentic, it’s unclear what limits would apply, as the AI model training becomes about far more than next-token prediction.
There aren’t any near-term absolute limits nor fundamental limits on scaling AI model compute, parameters or data. By ‘no fundamental limits’ or ‘no theoretical limits’, we simply mean that the formula for training a foundational AI model can scale ad infinitum.
That is, if we can build a deep learning network of a billion parameters to a trillion parameters (which we have), we can build one with 10 trillion parameters, or even a quadrillion parameters - which we could do with GPUs 1000x more powerful and with 1000x more memory than we have today.
The challenge to AI model scaling is not fundamental, but the practical limits on the scaling of AI models: Scaling compute hardware to support such training; scaling up data quantity to feed scaled AI models; practical limits on AI model parameters for efficient inference.
Near-Term Compute Scaling and Inference Fleets
For the near-term, in the next few years, AI compute capabilities in data centers will explode and enable AI scaling of AI model training as well as massive increases in total AI inference:
“given inference fleets in 2027, we should be able to generate an entire internet’s worth of tokens, every single day”
The leading GPU seller Nvidia will be selling a massive amount of their leading-edge Blackwells in 2025. One analyst is estimating $200 billion in revenue for data center AI, based on Nvidia selling 70,000 racks (of 72 Blackwell GPUs each) costing close to $2 million each. That’s 5 million Blackwell GPUs in 2025 on top of the millions of Hopper GPUs we already have.
By 2026-2027, these AI data center inference fleets will have several orders of magnitude more AI compute capability than exists now. They’ll be able to train many models, serve millions of requests, and generate trillions of words in a single day.
The AI models these fleets will be serving in 2026 will be a cut above GPT-4o - as OpenAI puts it, “Ph.D. level intelligence.” These AI factories will be speeding AI progress while also serving a large-scale expansion of cutting-edge AI model use.

Practical Limits with Data
The takeaway is that compute, data, and other limits on scaling AI models are far above where AI models are today, and we are on track for an explosion of AI capabilities in the next few years.
However, we will hit practical barriers as we scale AI models 100x and beyond.
The biggest barrier may become data. We’ve learned that data quality matters, and that we need both data quality (such as textbooks) and data quantity. In scraping the web, AI model maker started with quality, have since learned to focus on quality.
Leading AI models have been trained on tens of trillions of tokens; Llama 3 was trained on 15 trillion tokens. This amount of data represents most of the what’s available on the internet (Common Crawl) and through public information.
How much data is out there, still untapped? Just as importantly, how much high quality data is out there?
It’s plausible to increase this amount of data (50 trillion tokens) by 10 times to 500 trillion tokens, by going after sources of private information online, such as corporate information, additional documents (from old newspapers to corporate memos) beyond the public internet.
OpenAI is cutting deals with media firms to manage ingestion of more data under copyright. Availability of video (on YouTube) and audio (podcasts) can add significant headroom to the data for multi-modal LLMs.
These sources might yield a ten-fold increase in data, but what’s not already utilized is harder to find and of lower quality. What data can be used to 100x the dataset? More data can be found, but like looking for oil, once the high-quality, easy resources are obtained, the rest becomes more expensive.
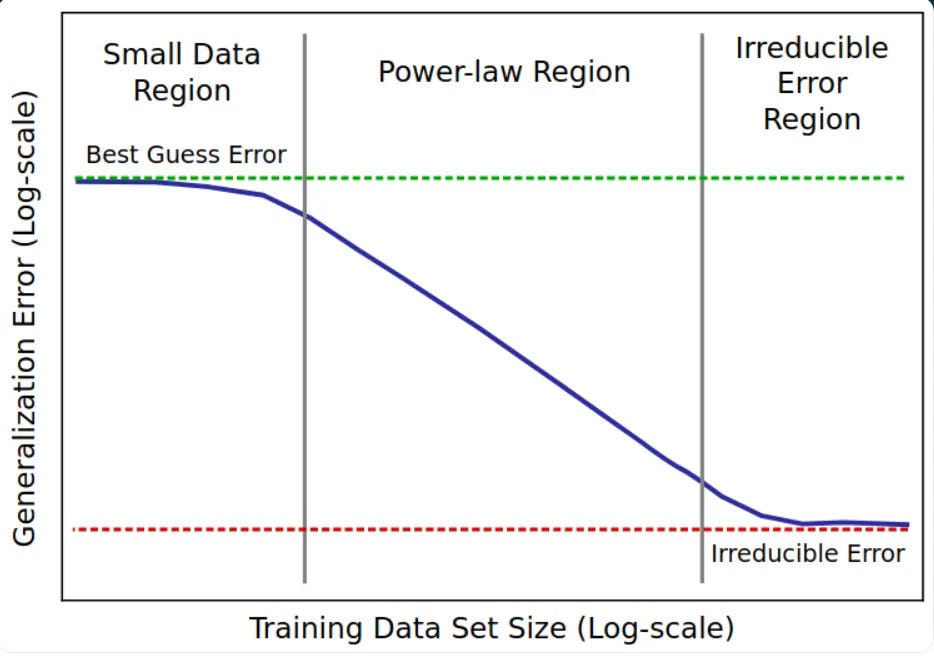
The Log-Linear Wall
It will get to a point where there once there is already significant data - say hundreds of trillions of tokens - adding more data doesn’t add sufficient value to the AI model to be worth the effort.
Why? The log-linear benefit of AI model scaling means that an AI model increases performance linearly on the log of the increased data, compute, or parameters. It takes exponentially more data, compute or parameters to improve an AI model linearly.
The more data you have, the lower the value of any additional data token to the AI model. To go from:
One trillion to 10 trillion tokens - takes you from a 3 to a 4
From 10 trillion to 100 trillion tokens - takes you from a 4 to a 5
From 100 trillion to 1,000 trillion tokens - takes you from 5 to a 6
The reason why we have been able to scale up AI model performance so much is due to the massive increases - 6 OOMs - in inputs for building AI models. Sourcing data and adding compute has cost money. Scaling up further will cost money.
If there is going to be data and compute scaling, there needs to be investment scaling.
Will the investment levels scale further to meet the challenge?
Commodity AI models and the ROI Challenge
Those investments have so far paid off for the leading edge AI tech companies, and money and interest is pouring in. Market caps for companies like Microsoft, Nvidia, and huge AI startup interest is
However, there is a challenge: Foundation AI models are getting commoditized. There is no moat.
Nvidia is selling GPUs to everyone; there is no moat in compute. There is no moat in algorithms and architecture; most effective training methods and architectures are published, with recipes are shared. The open source community and innovative academics are trying different techniques and publishing them.
There may be competitive advantage in datasets, but all players know data’s importance, and there are sufficient efforts in open datasets as well as enough different players to keep the playing field competitive.
Switching costs for AI models are very low; developers building AI applications can switch out one AI model for another.
This adds up to a dynamic where the prize - AGI - is very valuable, but the ability to monopolize AI models small.
ROI stands for Return on Investment. Any AI training investment will have an intended return, either in
The ROI challenge is the challenge of hugely expensive capital projects to develop products with heavy competition and low margins. Only the best, most efficient AI models will get used.
One business similar to this is semiconductor manufacturing. Forty years ago, there were many vertically integrated semiconductor manufacturers, but they fell by the wayside as few could compete with the capital requirements.
If any given company is going to be investing $10 billion in an AI compute cluster, let alone $100 billion or $1 trillion, they are going to be asking about whether they will get their money back
Trees don’t grow to the sky. The ultimate limit on scaling compute will largely be a financial constraint.
Will there be a ‘great AI washout’?
We believe that AI is a fundamental transformational technology as important as the internet, radio, and the railroad combined.
Like those other technologies, AI is not immune to hype cycles. AI has already been through “AI winters” in past decades. The promise of self-driving led to hype, disappointment, and then shut-downs and bankruptcies. The road to self-driving cars has been rocky.

A technology revolution induces rapid changes in expectations. The source of a new-technology hype cycle is the underdamped nature of social beliefs: crowd-following, fear-of-missing-out aka FOMO, and a ‘gold rush’ investment fervor.

Investments in new technologies grow to the level of expected opportunity. The challenge is that a new technology’s path is hard to predict. Expected opportunity values rise or fall depending on economic conditions and technology progress and competition, and a cycle ensues as perception feeds on itself.
We can look to the internet bubble for a prime example of how an AI hype-bubble and then ‘great washout’ could occur. Investment and enthusiasm built over several years, until unsustainable companies were being supported. When the credit cycle turned in 2000, investment flows dried up and unsustainable businesses plummeted.
Aschenbrenner notes, to support the thesis that a $1 trillion cluster is possible:
Between 1996–2001, telecoms invested nearly $1 trillion in today’s dollars in building out internet infrastructure.
However, many of those investments went sour. So will that be the fate of the $1 trillion AI cluster?
What we can conclude is that all of these things are true:
Massive investments in AI are likely, just as happened in the early internet era, because the AI opportunity is huge.
Those investment might not be a straight line up; expectations, competition, sentiment and credit conditions in the economy will determine investment levels.
The hype cycle will play out in AI like it’s done in other technologies. We will have ‘dips’ along the way.
Conclusion
There are no fundamental limits to continued scaling of AI. There are however, practical limits and blockers that could slow AI development.
One limitation is the availability of high-quality data. At some point, the value of additional data will become small while the cost of obtaining more data gets steeper.
Another limitation is in scaling compute. The cost of scaling compute to build ever bigger and more expensive AI models may at some point run into limits; pockets are only so deep.
In both cases, it’s an ROI-driven limit. We may be technically capable of going bigger, but the return on the investment isn’t worth it. In a similar way, we are finding it’s simply more cost-effective to over-train smaller AI models than expensively train larger AI models.
As perceptions around AI development change, it may feed into hype or cause a “washout” or an “AI bubble” bursting. This has happened before in other technology shifts (internet, railroads), so it’s quite possible for AI. History and the stock market never go in a straight line.
If we find ways of improving agentic reasoning and solving most tasks without scaling AI models, we may get to a place where the ‘best’ models aren’t the biggest.
Postscript. AI Acceleration Limits
Leopold says:
“A classic lesson from economics (cf Baumol’s growth disease) is that if you can automate, say, 70% of something, you get some gains but quickly the remaining 30% become your bottleneck.”
As AI accelerates and automates parts of a workflow, process, or computation, the acceleration is limited by the portion that is not automated. We can quantify this concept.
Let’s say a process P takes X discrete steps, each step either automated (by AI or machine) or not. Let A steps be automated. Then A = automated portion. X-A = non-automated portion. Let a = A/X be the ratio of automated tasks, to normalize the automation to a ratio. So A = aX.
If the effort/time for each of those A steps is non-zero, we can make an automation effort ratio of r (r<1) be the effort for each step. Then:
Total time /effort = (X-A) + rA = (X - aX + raX)Normalizing the process using p, we get the speedup S relative to an original time or effort on a task X to be X/(X-aX+raX) or:
This Law on AI automation acceleration is similar to Amdahl’s Law, which gave us limits on parallel computing’s effectiveness, by expressing speedup as a function of the amount of parallelized tasks. Amdahl’s Law is expressed as follows, where p is the fraction that is parallelizable:
This law gives us limits on the effective acceleration due to AI automation, a reminder that even if we accelerate significant parts of work tasks, the speedups of those tasks will still be limited by the remainder that is not automated.