


“No exponential is forever. But forever can be delayed.” - Gordon Moore
The world lost visionary innovator and Intel co-founder Gordon Moore this week at age 94. Nearly 60 years ago in 1965, Gordon Moore made his famous “Moore’s Law”, prediction that transistor counts on the IC (Integrated Circuit) would double every 18 months. Now Moore’s Law has out-lasted its author, as Intel, TSMC and Samsung race to build chips at Angstrom-level transistor sizes and with many billions of transistors on a single chip. It’s been noted that the scaling of transistors has just been a larger part of the trend towards smaller logic switches and a longer exponential curve.

Moore’s Law prediction can be viewed as a subset of the general technology development rule that technology advances on an exponential curve. AI development has ridden a similar set of exponential curves since the dawn of efforts in AI in the 1950s.
AI models today have been scaled in three ways: Larger model training compute effort; more AI model parameters; and large input training data. Sevilla et al (in 2022) 1 documented the scaling of compute used to train AI systems from the earliest AI efforts right up to 2022. They identified three distinct periods with different rates of AI training compute scaling:
The first period - pre-Deep Learning Era - from the 1950s to 2012. The era scaled AI training compute as the Moore’s Law scaling of compute advanced. AI training compute doubled about every every 20 months.
The second period - Deep Learning Era - from 2012 to about 2016. In the Deep Learning Era, the use of GPUs to parallelize AI training and larger data sets available for useful training led to larger use of compute. The scaling of training compute accelerated to doubling every 6 months.
The third period - Large Scale Era - kicked off in late 2015 with AlphaGo. Firms started developing large-scale ML models with 100-fold larger requirements in training compute over what was previously done, and doubled every 10 months. During this period, the ‘regular scale’ models are continuing to grow at a double rate of every 6 months.

This log-based chart below shows more detail on the compute effort in the Deep Learning Era and Large-Scale Eras from 2010 to today. AI training compute effort has increased 10 orders of magnitude, that is ten-billion-fold, from 2010 and 2011 to today.

As with the compute scaling, so too with parameters used in the AI models. AI models have scaled up the number of parameters at an exponential pace. This chart below from Villalobos et al (2021)2 shows the number of parameters per released model over time. The increase was 0.1 OOMs/year (orders-of-magnitude per year) up until 2018. There was a step-change for language models in 2018, making Large Language Models a separate category, shown on the right-side chart in red. This was when the development of transformers (from "Attention is all you need"3 paper) enabled parallelizing and thus scaling up training to much larger language models.

A step-change for language models occurred in 2018 with the “Attention is All You Need” that led to transformer-based language models that could be trained at much greater scale; that enabled the creation of multi-billion parameter Large Language Models. As a result, today’s largest LLMs can do powerful things unthinkable on billion-times less powerful models a mere 12 years ago.
Deep Mind researchers in 2022 released a paper and an AI model called Chinchilla4 which up-ended some assumptions about appropriate scaling of parameters, compute effort and data size for training AI models. Their AI model used 70 billion parameters, much fewer than GPT-3, but trained on 4 times more data. They showed that Chinchilla uniformly and significantly outperformed other larger models including Gopher (280B), GPT-3 (175B), Jurassic-1 (178B), and Megatron-Turing NLG (530B).
This result showed that prior LLMs were under-trained, likely had too many parameters, and could benefit from increases in input training data size. In the short term, this may perturb LLM size trends (early models were too big vs training effort), but over the long-term, they showed a path forward for scaling Large Language Models, with scaling of input data, parameters, and compute effort in tandem. This chart below shows how parameters, tokens and compute effort relate to make a compute-optimal model.
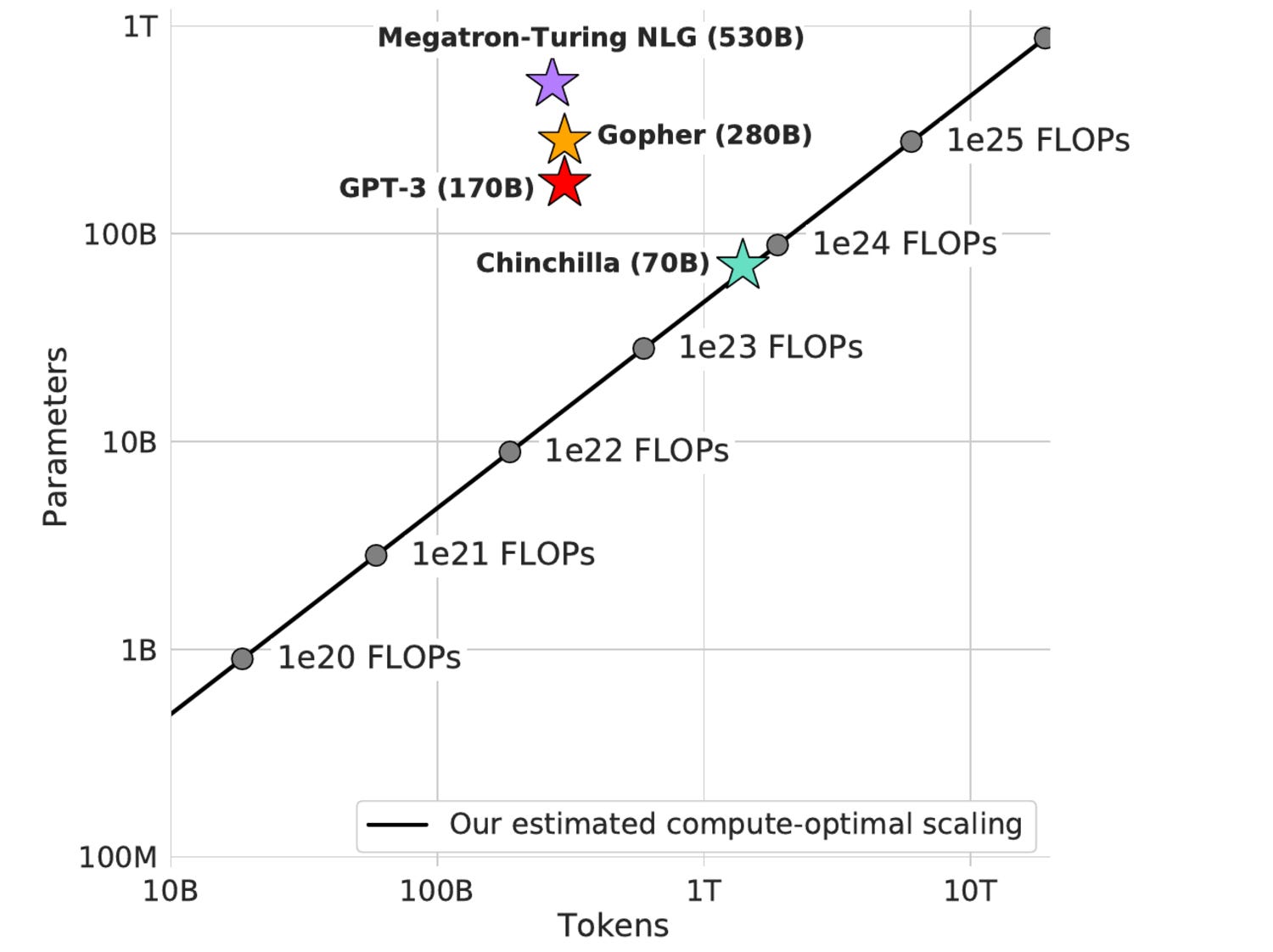
Future LLM Scaling
The Chinchilla authors give possible appropriate sizes for scaling future larger LLMs, in their Table 3:

This scales shows that for each doubling of parameters, there should be a 3 times increase in compute, and 2.5 times increase in tokens. Key points to consider:
Technology improvement doesn’t stop. AI model scaling will continue for the foreseeable future.
AI is an informational technology, so AI will multiply its impact and accelerate technology process and adaptation, including its own.
Future AI model scaling will occur at the same pace or even faster than before.
What does that tell us about future AI development?
AI models are getting better at an exponential rate.
The scaling of parameters, input training data, and compute effort for AI model training will continue at a doubling rate in the range of 6-18 months, i.e., where all three are scaled up in tandem. We can expect new generations of improved Foundation Models at that same pace, improving at that same rate.
AI model scaling will not end soon. More parameters, more training data, and more compute for AI model training will continue for at least several more generations.
AI will achieve super-human intelligence in the near-term future, certainly within our lifetimes and possibly by the end of this decade.
Caveat: There is a reluctance by some to advance AI out of AI safety concerns, so there may be some brakes on new AI models that diminish progress so that the pace is slowed. However, it’s unlikely this can slow all progress, and even the current models are disruptive enough to our economy and how we work to change the world.
Future Shock and the Pre-Singularity
The most important word describing AI’s rate of improvement: Quickly.
Humans think linearly, not exponentially. Our expectations of the future can be warped by that. An exponential starts at a snail’s pace, so things changing slowly or not at all, and then, boom, the pace of change increases and change happens quicker than we expect. Yet the change was following the same exponential curve the whole time.
The biggest shock from AI will be the accelerating speed of change. As AI is a fundamental information technology, it will accelerate science (think AlphaFold2), software (Github Copilot), product dev (text-to-3D-model-render-to-3D-printer in an hour), art/creation (Midjourney, Runway), etc. AI changes everything.
AI's acceleration of our already increased pace of technology change will continue to shock us. Kurzweil has noted that the doubling time for technology keeps coming down, and that implies we will have more technology progress in the next 20 years than in the past 10,000 years. With AI becoming very useful and powerful very quickly, we have gone beyond "future shock" pace of technology change to a ramp towards what's been called the Singularity - the 'pre-singularity’.
Postscript
A Linked-in question of whether "AI are just tools" or "AI will take over beyond our control” was posed. I responded that both are extremes and reality is more nuanced, and further elaborated:
AI are "only tools" if by only tools you mean akin to having a space shuttle rocket in your garage and calling it "only a way to go from place to place" or calling a supercomputer a sophisticated calculator. GPT-4 was trained most of the text on the internet and then some, so it's like having an internet assistant that is the internet.
AI could have some 'agency' and there are risks, but i don't see how just unplug the thing isn't the solution to the "lose control of" concern. A lot of the brow-beating over AI safety is really people worried that such a powerful tool could get into the 'wrong hands' or be used for the 'wrong purposes'. A valid concern, but that's about human nature wrt ANY powerful technology. I believe people are 90% good and 90% of AI will be used for good, and that limiting AI will be for the most part futile (it will happen anyway) and detrimental (in denying the positives of AI).
Jaime Sevilla, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, and Pablo Villalobos. 2022. Compute Trends Across Three Eras of Machine Learning. arXiv preprint arXiv:2202.03854 (2022).
Pablo Villalobos, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, Anson Ho, and Marius Hobbhahn. 2021. Machine Learning Model Sizes and the Parameter Gap. arXiv preprint arXiv:2106.06609 (2021).
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS'17). Curran Associates Inc., Red Hook, NY, USA, 6000–6010.
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals and Laurent Sifre. 2022. Training Compute-Optimal Large Language Models. arXiv preprint arXiv:2203.15556 (2022).