


AI Research Roundup 24.06.07
Mamba 2 State Space Model, FineWeb and FineWeb-Edu Datasets, Perplexity-Based Data Pruning


Introduction
Our AI research highlights for this week focus on improving LLMs through better architecture and training data:
Mamba-2 State Space Model and Structured State Space Duality (SSD)
FineWeb and FineWeb-Edu Datasets
Perplexity-Based Data Pruning Improves Training Efficiency
We predicted last year that “There is a lot of room to improve LLM efficiency. AI models can be made far more capable with the same or even smaller parameter count.” Innovations, in architectures, training datasets, and training process are making great strides in improving the efficiency and quality of LLMs and other AI models.
For example, the Phi model developers, as shared in “Textbooks are All You Need” took care to develop and use only high-quality data in LLM training. That led to the very efficient Phi, Phi-2 and Phi-3 models. Other improved LLMs applied these lessons as well.
These latest research results show more improvements in architectures, data, and training etc. are possible, yielding more efficient and better LLMs.
Mamba-2 State Space Model and Structured State Space Duality (SSD)
Transformers have been the dominant architecture for language models (LLMs), but state space models (SSMs) have been developed as an efficient alternative.
The latest proposed SSM is Mamba-2, a successor to the innovative Mamba model that outperforms Mamba and Transformer++ in perplexity and wall-clock time.
The researchers behind both Mamba and Mamba 2, Albert Gu and Tri Dao, looked at Mamba’s strengths, weaknesses and its underlying connections with attention, and from that, improved on Mamba to develop Mamba 2. They shared their results in the paper “Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality.”
The paper presents a framework connecting SSMs to attention through the concept of State Space Duality (SSD):
We show that these families of models are actually quite closely related, and develop a rich framework of theoretical connections between SSMs and variants of attention, connected through various decompositions of a well-studied class of structured semiseparable matrices.
They work through the mathematics to show that sub-quadratic matrix operations are possible with structures matrices, “a powerful abstraction for efficient representations and algorithms.”

They show that SSMs are equivalent to another class of structured matrices. While SSMs typically have a linear-time recurrence, expanding the matrix formulation characterizing its linear sequence-to-sequence transformation yields a quadratic form.
While attention is defined through quadratic-time pairwise interactions, they find that “viewing it as a four-way tensor contraction and reducing in a different order, one can derive a linear form.” Thus, both SSMs and attention have dual forms, based on being various forms of structured masked attention.
Our main result is showing that a particular case of structured state space models coincides with a particular case of structured attention, and that the linear-time SSM algorithm and quadratic-time kernel attention algorithm are dual forms of each other.

The theoretical results on how these architectures relate to each-other could stand alone as an important contribution, but the authors went further, and used these insights to develop Mamba 2.
In particular, they took efficiency enhancements used in attention, and improved Mamba to make Mamba 2.
Mamba-2 simplifies the core Mamba block by removing sequential linear projections. They migrated the core layer to a parallel refinement of Mamba's selective SSM to make it is more parallelizable:
Note that adopting parallel projections for the 𝐴, 𝐵,𝐶, 𝑋 inputs to the SSM slightly reduces parameters and more importantly is more amenable to tensor parallelism for larger models, by using standard Megatron sharding patterns.
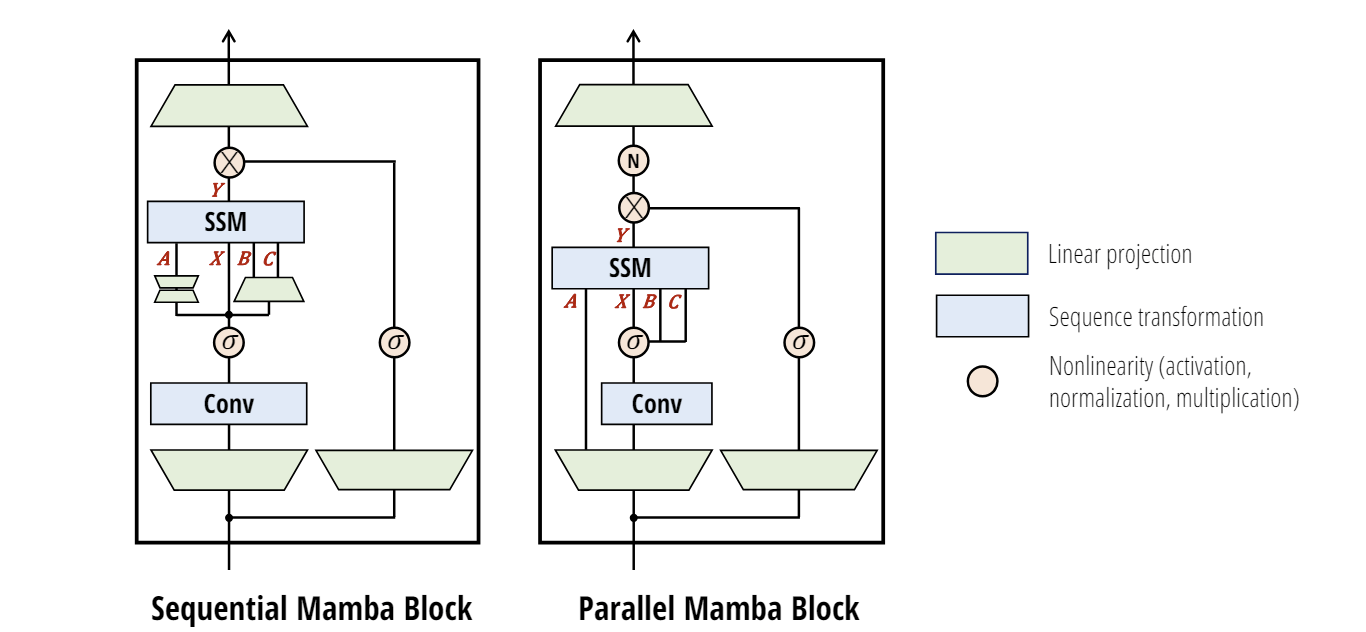
Mamba 2’s reformulation can exploit specialized GPU matrix multiplication, that speed it up 2-8× over Mamba. As a result of optimizations, Mamba-2 has 50% faster training than Mamba.
Lastly, they show that SSD and attention layers are complementary. Specifically they compared different configurations of a 2.7B (64 layers) model, trained to 300B tokens on the Pile, including SSM-Attention hybrid configurations:
Transformer++: 32 attention layers and 32 gated MLP, interleaving.
Mamba-2: 64 SSD layers.
Mamba-2-MLP: 32 SSD and 32 gated MLP layers, interleaving.
Mamba-2-Attention: 58 SSD layers and 6 attention layers.
Mamba-2-MLP-Attention: 28 SSD layers, 4 attention layers, 32 gated MLP layers.

The results show that a mixture of SSD and attention layers, such as Mamba-2-attention with 58 SSD layers and 6 attention layers, outperforms the pure Mamba-2 or Transformer++ architecture, albeit incrementally.
FineWeb and FineWeb-Edu Datasets
HuggingFace researchers have shared a technical report called “FineWeb: decanting the web for the finest text data at scale” on FineWeb. They also in the report introduce FineWeb-Edu, a high-quality subset of the 15 trillion token FineWeb dataset, created by filtering FineWeb using a Llama 3 70B model to judge educational quality:
FineWeb-Edu is available in two sizes/filtering-level: 1.3 trillion (very high educational content) and 5.4 trillion (high educational content) tokens (all tokens are measured with GPT2 tokenizer. You can download it here.
We mentioned FineWeb in the article “Data is All You Need” when it was first released last month. We noted then that “data quality matters.” The question is how to determine that. What makes data high quality?
The raw material for FineWeb is the CommonCrawl (CC) data from the web, but it’s a vast amount of data, much of it of low quality. (The latest CC crawl (April 2024) contains 2.7 billion web pages, totaling 386 terabytes of uncompressed HTML text content.) It needs to be filtered, de-duplicated, and refined down to quality text information helpful to train an LLM.

The FineWeb report explains the details of the data pipeline used to make FineWeb, as well as the ablation studies used to evaluate filtering approaches that work and don’t work. They explain the various processing steps and design choices, and futher show how it compares with (and is superior to) other open datasets.
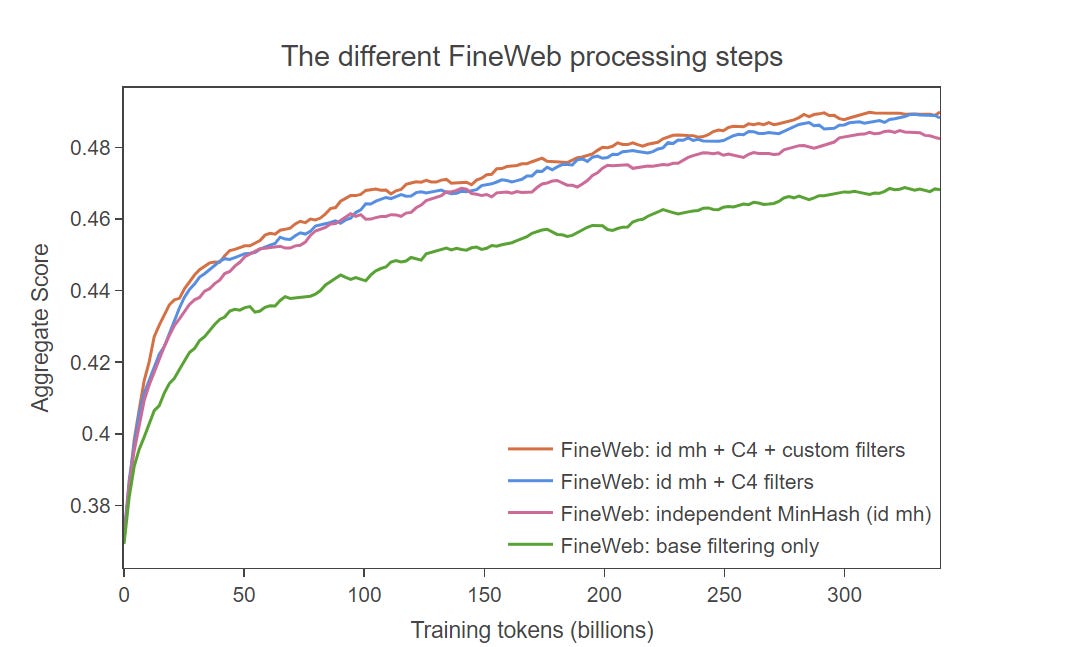
FineWeb-Edu is a further refinement of FineWeb, to reduce the dataset down to the most educational and helpful subset of content:
FineWeb-Edu is based on a new approach that has recently emerged for filtering LLM training datasets: using synthetic data to develop classifiers for identifying educational content.
They used Llama 3 70B as a classifier to annotate FineWeb web pages for their educational content, scoring them from 1 to 5 on educational content. Filtering only on high-scoring content (scoring 3 or above) yielded FineWeb-Edu.
This process makes FineWeb-Edu a remarkably more efficient LLM training dataset that enables faster LLM learning. FineWeb-Edu shows remarkable improvements over FineWeb and other open web datasets on LLM training (such as Dolma), as shown by its higher benchmarks such as MMLU, ARC, and OpenBookQA when trained on the same number of tokens.

FineWeb is a large, high-quality dataset for LLM training that is available openly, and now FineWeb-Edu is even more high-quality. Since high-quality training data is the path to highly efficient LLMs, we hope this will lead to better open AI models in the near future.
Perplexity-Based Data Pruning Improves Training Efficiency
As noted in our discussion on FineWeb, training efficiency depends on the training data quality. The paper “Perplexed by Perplexity: Perplexity-Based Data Pruning With Small Reference Models” uses small reference models for perplexity-based data pruning.
Specifically, this paper studies pruning training data based on a 125M parameter model's perplexities. The small model made it efficient to evaluate different data pruning selections and choose the most promising:
We sweep across pruning selection criteria and selection rates and find that the best settings are to select high-perplexity samples at a 50% rate for the Pile and to select medium-perplexity samples at a 50% rate for Dolma.
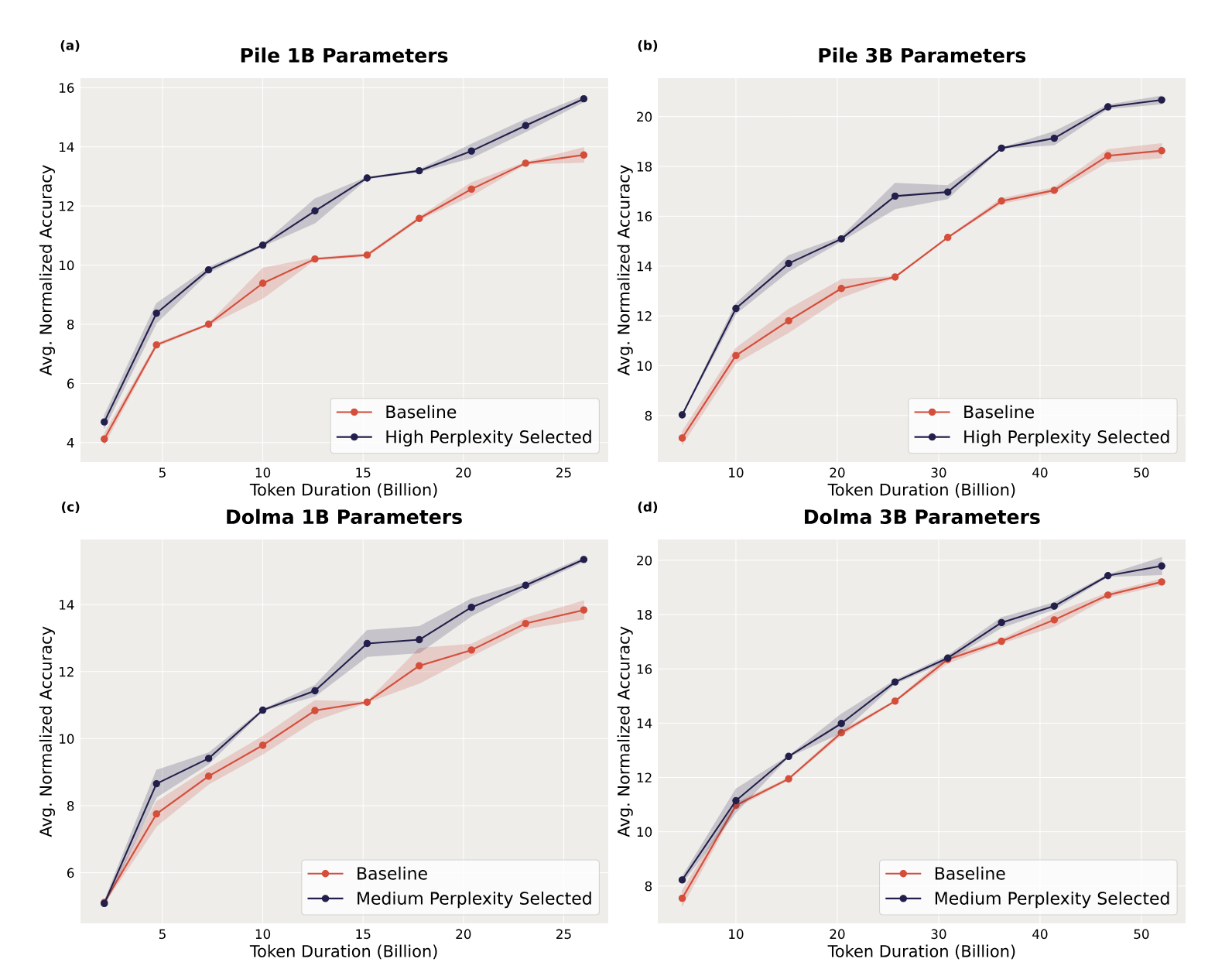
They show that small reference models can be used to prune the data of models with up to 30× more parameters, i.e., 3B parameter models. Their pruning method improved downstream task performance of a 3 billion parameter model by up to 2.04, and reduced pretraining steps by up to 1.45x.
They showed that perplexity-based data pruning also yields downstream performance gains in the over-trained and data-constrained regimes. This is an additional tool for reaping efficiency improvements during training.