


AI Research Roundup 24.09.27
Molmo and PixMo VLM and dataset,Qwen2-VL, ScoRe to self-correct with RL, ProX to refine pre-training data at scale, Jump-starting LLM pretraining with HyperCloning.

Introduction
This week, our Research Roundup covers recently released open Vision Language Models (VLMs) Molmo and Qwen2-VL, RL-based self-correction to improve LLM reasoning, and methods to accelerate LLM pre-training:
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
ScoRe: Training Language Models to Self-Correct via Reinforcement Learning
Programming Every Example: Lifting Pre-training Data Quality like Experts at Scale
Scaling Smart: Accelerating Large Language Model Pre-training with Small Model Initialization
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Three great new open vision language models (vision LLMs or VLMs) were released in the last two weeks: Llama 3.2 11B and 70B from Meta, which we covered in the prior article this week, Meta’s Vision and OpenAI’s Voice; Qwen2-VL from Alibaba Qwen team, which we’ll discuss below; and Molmo from AI2.
Molmo (Multimodal Open Language Model) is a family of 1B, 7B and 72B parameter VLMs, and distinguishes itself as a high-performing yet small VLM, matching the performance of larger proprietary models on vision tasks. AI2’s Molmo also distinguishes itself as a truly and fully open-source AI model trained from scratch, with open weights, open training dataset, and most code shared. The model developers shared architectural and training details in Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models.
The model openness starts with the training dataset. They created PixMo, a novel dataset of image captions collected from human annotators using speech-based descriptions. This method yielded more detailed and efficient data collection than traditional typing methods and avoided relying on data from proprietary VLMs.
Molmo's architecture follows a standard design of combining a pre-trained vision encoder and an LLM. The vision encoder uses OpenAI’s ViT-L/14 336px CLIP model, while the LLM backbones used are: OLMoE-1B-7B for the efficient 1B model; open-weight Qwen2 7B and OLMo-7B-1024 (fully open) for 7B models, and Qwen2 72B, the best-performing Molmo model.
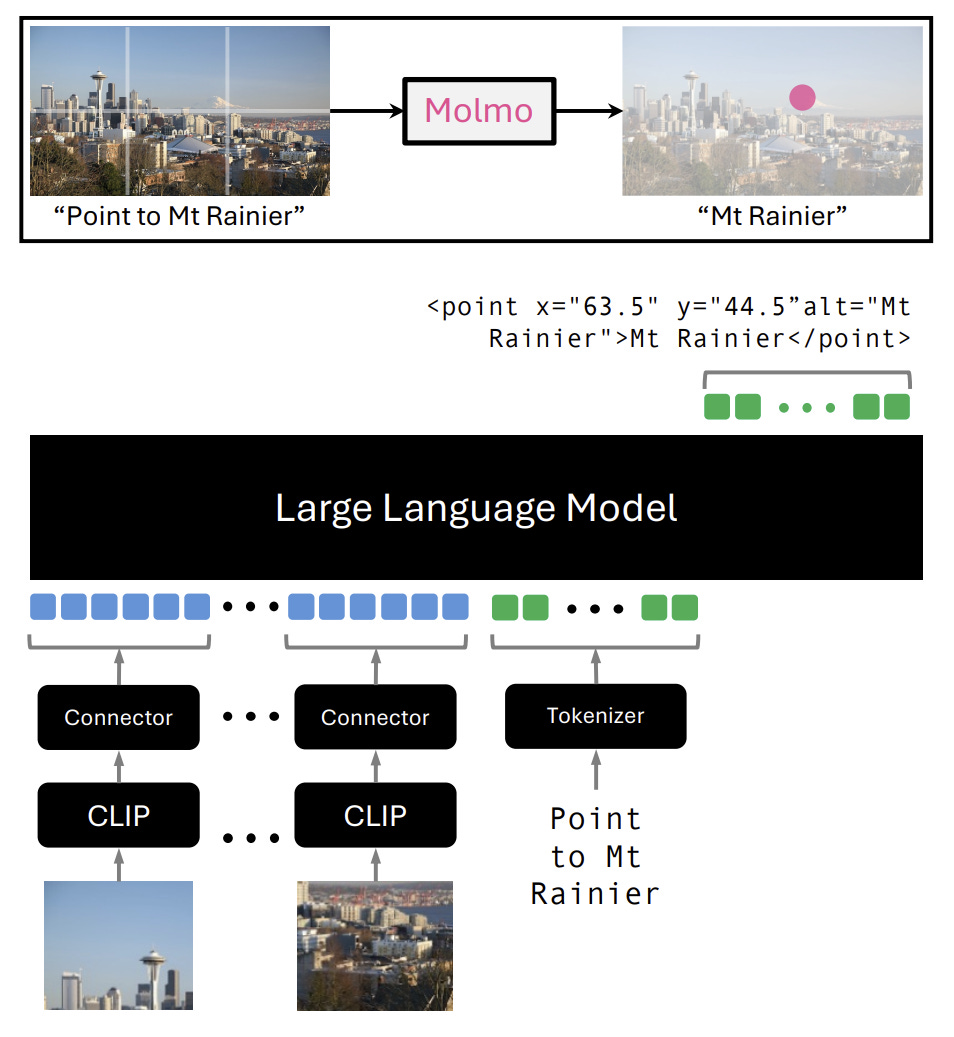
They trained the VLM in two stages: First, multimodal pre-training for caption generation; second, supervised fine-tuning on diverse data mixtures, including academic datasets and newly collected datasets like PixMo-AskModelAnything, PixMo-Points, and PixMo-Docs. The authors evaluated Molmo VLMs on 11 academic benchmarks and a human evaluation, showing solid performance, especially on the 72B model:
The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation.
AI2 built Molmo to openly share how VLMs can be built, so they are releasing model weights, captioning and fine-tuning data, and source code; additional information and demos are available at the Molmo home page.
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-VL was released in late August by Alibaba’s Qwen team, as we shared in our AI Week in Review for August 31, and it set a new standard, achieving SOTA results for many visual understanding tasks and benchmarks. Qwen2-VL 72B outperforms both Claude3.5 Sonnet and GPT-4o across many visual QA, video understanding and document understanding tasks.

The technical report Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution explains the Qwen2-VL training, architecture, and performance and explains the different techniques that delivered Qwen2-VL’s high performance. One feature is that Qwen2-VL replaces the conventional predetermined-resolution approach in visual processing:
Qwen2-VL introduces the Naive Dynamic Resolution mechanism, which enables the model to dynamically process images of varying resolutions into different numbers of visual tokens. This approach allows the model to generate more efficient and accurate visual representations, closely aligning with human perceptual processes.

The model also integrates Multimodal Rotary Position Embedding (M-RoPE), facilitating the effective fusion of positional information across text, images, and videos. As a result, Qwen2-VL is capable of understanding videos over 20 minutes in length.
Qwen2-VL is built from a 675M parameter ViT and pre-trained LLM backbone. They adopt a three-stage training methodology to finalize the Qwen2-VL VLM: First, train the Vision Transformer (ViT) component; second, unfreeze all parameters to train on a wider range of data for comprehensive learning; third, lock down ViT parameters and fine-tune just the LLM using instructional datasets. This training processes a cumulative total of 1.4 trillion text tokens and image tokens.
The result is a remarkably good VLM that that achieves SOTA on vision tasks. The Qwen team has released Qwen2-VL as open weights models on HuggingFace and shared code on GitHub, so you download the quite capable Qwen2-VL 7B and run it locally.
SCoRe: Training LLMs to Self-Correct via Reinforcement Learning
A key trait of good reasoning is the ability to self-correct from mistakes, but self-correcting capability is lacking in current LLMs. Google Deep Mind presents Training Language Models to Self-Correct via Reinforcement Learning to share an approach to instill self-correction in LLMs, called SCoRe.
SCoRe, from Self-Correction via Reinforcement Learning, is a multi-turn online reinforcement learning (RL) method that enhances the self-correction ability of LLMs using self-generated data. It addresses the limitations of traditional supervised fine-tuning (SFT), which often fails due to distribution mismatches or ineffective correction strategies. SCoRe overcomes these challenges by training on the model’s own correction traces and using regularization to develop a robust self-correction policy.

Applied to Gemini models, SCoRe significantly boosts self-correction performance, with improvements of 15.6% on MATH and 9.1% on HumanEval. This work indicates that reinforcement learning plays an essential role in self-learned self-correction, just as RL has been key to other advances in LLM reasoning.
Programming Every Example: Lifting Pre-training Data Quality like Experts at Scale
As we discussed in the article “Data Is All You Need” in May, both data quality and data quantity matters in pre-training LLMs for best results. With much internet text in noisy and low-quality for training, it makes refining data to improve its quality at scale an important and challenging task.
The paper Programming Every Example: Lifting Pre-training Data Quality like Experts at Scale introduces ProX, a framework that uses language models to refine pre-training data at scale through program generation:
We introduce Programming Every Example (ProX), a novel framework that treats data refinement as a programming task, enabling models to refine corpora by generating and executing fine-grained operations, such as string normalization, for each individual example at scale.

By treating data refinement as a programming task, they can use small language models (as small as 0.3B parameters) to flexibly refine data, yielding higher quality data. They applied ProX to curate pre-training datasets, including C4, RedPajama-V2, OpenWebMath, and FineWeb. Experiments on these curated datasets showed models pre-trained on ProX-curated data outperform either original data or data filtered by other selection methods by 2% or more.
While 2% sounds marginal, by enhancing data quality, the ProX method cuts the training needed to achieve the same performance level by up to 30 times in some cases, significantly saves training FLOPs. Analysis on domain-specific continued pre-training also showed that ProX outperforms human-crafted rule-based methods, “improving average accuracy by 7.6% over Mistral-7B, with 14.6% for Llama-2-7B and 20.3% for CodeLlama-7B.”
The authors have open-sourced the ProX refined 100B corpora and shared training and implementation details on GitHub.

Scaling Smart: Accelerating Large Language Model Pre-training with Small Model Initialization
Researchers from Apple have shared Scaling Smart: Accelerating Large Language Model Pre-training with Small Model Initialization, a simple but useful idea to save pre-training effort for LLMs, called HyperCloning:
HyperCloning [is] a method that can expand the parameters of a pre-trained language model to those of a larger model with increased hidden dimensions. Our method ensures that the larger model retains the functionality of the smaller model. As a result, the larger model already inherits the predictive power and accuracy of the smaller model before the training starts.
This could be viewed as the inverse of pruning techniques that use a larger pre-trained LLM to initialize a smaller LLM, such as was done recently on Llama 3.2 1B and 3B models. This takes a smaller LLM, expands and maps the weights onto the larger new LLM footprint while replicating its behavior.
This jump-starts the pre-training process, getting the LLM to faster convergence, in some cases achieving accuracy benchmarks 2x faster and saving significant training time in the process.

With many LLMs now third or fourth generation models, it makes sense to jump-start next generation LLM training from prior trained LLMs as a base, instead of from scratch, since it reduces training costs. So, we can expect more use of pruning, cloning, merging, and weight-mapping to initialize training of new LLMs.