
New AI Updates and UI / UX for AI
New AI models and features - OpenUI, Microsoft 365 prompt auto-complete, Mistral's Codestral, Hugging Chat with Command R, Cartesia AI’s Sonic - and their UI/UX impact.


Introduction
This is a follow-up on the article “AI UI /UX, User Experience & Screen AI.” The past few weeks have seen many interesting demos and announcements. This update shares new features, releases and announcements we’ve observed and their impact on interfaces and UX for AI.
New AI applications, models and features we mention include: OpenUI, Google Prompting Guide for Gemini, Microsoft 365 auto-complete for prompts, Mistral Codestral, Hugging Chat’s Command R with tool use, Cartesia AI’s Sonic.
First, let’s distinguish three topics:
Developing good interfaces (UIs) and user experiences (UX) for AI applications, which was the main topic of the prior article and this article.
Using AI to comprehend user interfaces so that AI agents and can automate tasks that require UI interactions. An example of this is ScreenAI, also discussed in our prior article. This is an important capability for effective LAMs, Large Action Models, used in AI agent frameworks.
Using AI software generation tools to build user interfaces (UIs). An example of this is OpenUI, an AI application built by weights and biases that goes from prompt to basic web interfaces.
OpenUI itself presents the kind of AI application interface, similar to AI image gen interface, we mentioned in our prior article. It’s a prompt-based app with a prompt bar at bottom, suggested prompts, and prompt history on left, like a navigation bar, with a canvas to show off the generated result.
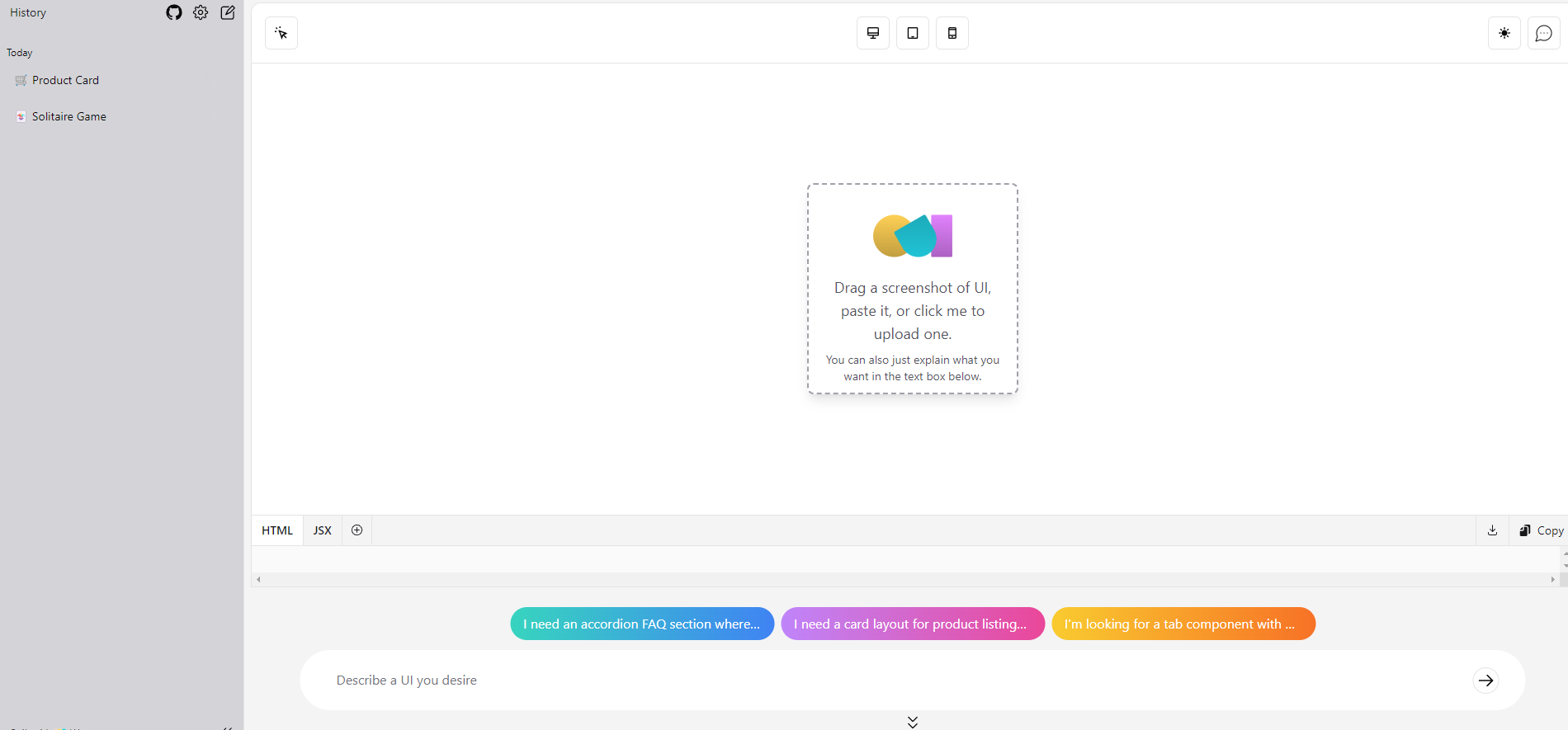
While our focus is on the first topic of interfaces for AI, there are advances and overlaps in all three. As AI gets used more in software development and AI agent frameworks get more complex, the three get more intertwined.
Extending AI UI Techniques
We mentioned a number of general desirable features for good UI/UX in AI applications: Feedback, Controllability, Explainability, Adaptability, Transparency.
While desirable in any software application, AI applications have the peculiar features of broad power, natural language interaction, and stochastic (or random) output. Ask ChatGPT literally any question and you’ll get an answer. Whether the answer is helpful or not depends on what or how the question is asked, and if the LLM was trained to handle it well.
AI applications and agents built on AI models can serve as an ‘assistant’ or ‘copilot’, but fall short of driving fully automated processes. Enhancing AI’s utility requires maintaining user control on inputs and refining outputs, fostering a synergistic human-AI workflow.
Prompt Engineering, Editing and Completion
On the input side, since the prompt is the AI model input, maintaining user control of LLMs is done by managing prompts. This begins with better prompting and prompt engineering, and encompasses automated aids like auto-complete, edit, and re-write. Support for prompting continues to evolve and improve:
Prompt engineering: There are guides for effective prompting, such as Anthropic’s intro to prompting, numerous online resources and course, and a new Google prompting Guide for Gemini, just released. The latter’s basic guidance: Prompts should express a Persona, Task, Context, and Format to guide the LLM well; this works for LLMs beyond Gemini.

Re-prompting: Re-prompting by the LLM, aka ‘the magic prompt,’ will have an LLM take an original prompt and rewrite it for better digestion by the full AI model.
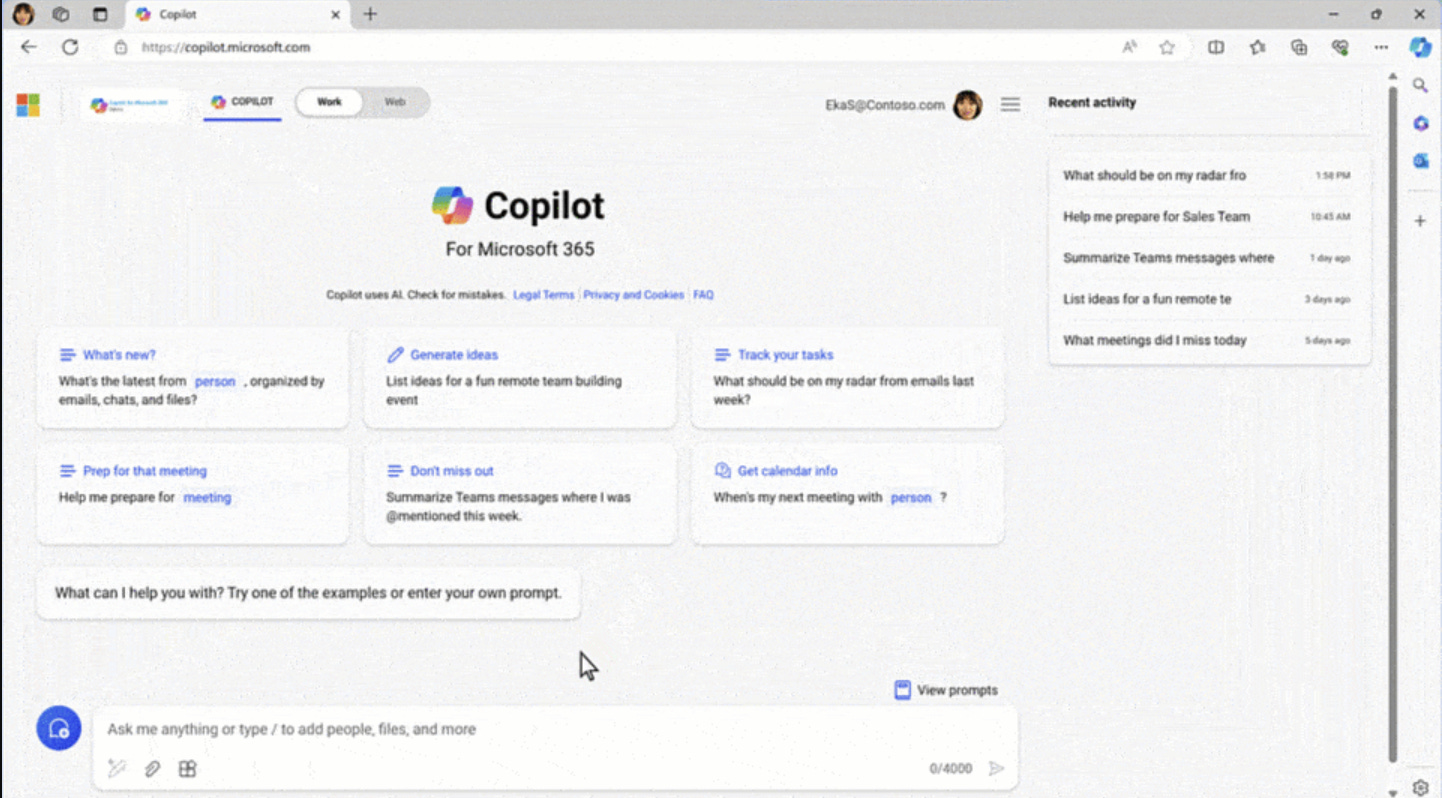
Auto-complete: Microsoft is addressing the “blank page prompt” issue with prompt auto-complete in Copilot for Microsoft 365, recently announced:
If you’ve got the start of a prompt, Copilot will offer to auto-complete it to get to a better result, suggesting something more detailed to help ensure you get what you’re looking for. That not only speeds things up, it offers you new ideas for how to leverage Copilot’s power.
Inpainting and Codestral’s Fill-in-the-Middle
Once you have an input generating an output, there is then the option of adjusting and tailoring the output. One way to tailor outputs is via inpainting, pioneered in AI image generation last year with Adobe photoshop generative fill.
The concept of controlled generative AI via inpainting is relevant to a number of modalities and creative endeavors: images, music, video, writing and coding. Sometimes an author wants a phrase or paragraph reworked, a video tweaked, or a soundtrack slightly adjusted.
Another example can be found in programming, with the newly released Codestral from Mistral, a 22B coding model with a 32K context window that achieves 81% human eval on Python:
Codestral is trained on more than 80 programming languages and outperforms the performance of previous code models, including the largest ones. It is available on our API platform, through instruct and fill-in-the-middle endpoints, and can be easily integrated into VScode plugins.

The “fill-in-the-middle” endpoint predicts middle tokens between a prefix and a suffix, which makes it very useful for software development add-ons like in VS Code. You can give it a skeleton of code to fill in functions, or fix a few lines of code with a bug with a delete-replace.
Codestral is available on their platform, but also on HuggingFace and as a plug-in on VSCode and Jetbrains:
VSCode/JetBrains integration. Continue.dev and Tabnine are empowering developers to use Codestral within the VSCode and JetBrains environments and now enable them to generate and chat with the code using Codestral.
Hugging Chat And Tool Power
Another element of AI model utility is connecting them to tools.
HuggingFace Chat, an interface to use open source AI models, has just been upgraded. Hugging Chat added Command R model access to Open Source Tools: Image generation and editor, calculator, parse document parser, web search.

Access to tools and multiple modalities are now table stakes for a AI chat interface. This gives users an open source option for
Multi-modality Changes Everything
The amazing GPT-4o demo set a new standard for AI chat interaction: Full audio interaction that was low latency, understood multiple different human voices as distinct, and could detect and express human emotions in a dynamic way, showing emotion sensitivity, emotive styles and dynamics.
“The prompt is the interface” now means “natural language, spoken or written, is the interface.” Audio is more natural than text for most human interactions, and so GPT-4o has come as close to a pure seamless interface as you can get. It raises the bar on older audio chat models like Alexa and Siri. Apple is widely expected to update and improve Siri accordingly, using GPT-4o directly.
Side note: Hugging Chat app is available on iOS, and Copilot app is available on iOS and Android.
If you want to go beyond the GPT-4o interface, getting the whole AI ecosystem capable of multi-modal interaction is important. LangChain supports multi-modal capabilities, and is incrementally improving it over time. For example, LangChain’s Google GenAI package just added multi-modal function calling with structured output, that lets you pass images, video and audio, and get back structured output.
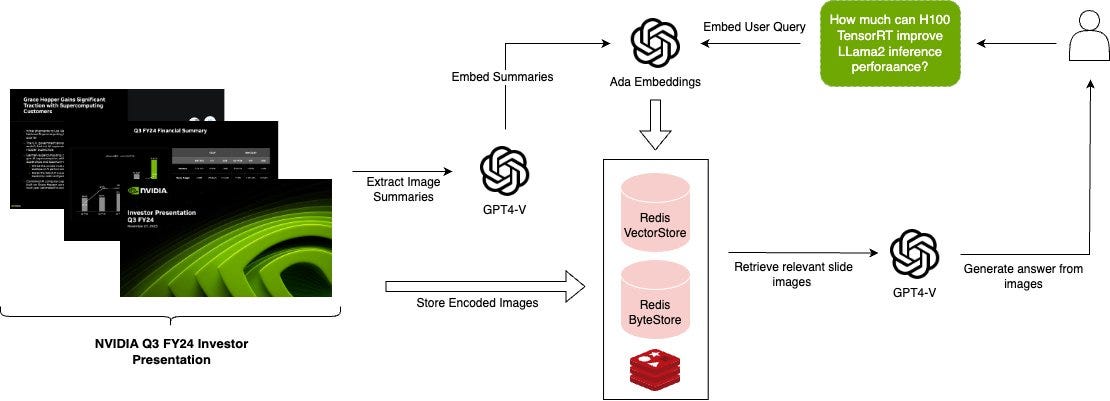
The RAG (retrieval augmented generation) systems built on LangChain traditionally are exclusively text, but in our multi-modal world, RAG needs to be extended to support additional data types, such as images and video. This blog post from LangChain and Redis explores the new multimodal RAG template.
Fast Audio with Cartesia’s Sonic
The bar set by GPT-4o is now pretty high: The audio interface needs to be expressive, responsive, and low-latency. GPT-4o did it with an integrated native multi-modal model, enabling fast response. turnaround.
If your base model is an LLM however, then a voice-based chatbot requires a three step process:
Speech-to-text (speech recognition) front-end, like Whisper.
LLM inference on input text.
Text-to-speech (speech synthesis) to convert response back to audio.
The speech synthesis step can be a bottleneck, but a new startup called Cartesia AI is announcing Sonic, a low-latency voice model for life-like speech. Their secret sauce is to use State-Space Models (SSMs), a more efficient alternative to transformers; we discussed SSMs in “Beyond Transformers with Mamba.”
SSMs make the Sonic model is faster and more efficient. As a result, it sets a new standard in low-latency:
Sonic creates high quality life-like speech for any voice with a model latency of 135ms—the fastest for a model of this class.
This is below the ‘magic’ 150ms threshold that we detect in human conversation. Combined the Sonic model with fast speech synthesis and LLM inference should get us to responsive low-latency audio interfaces in AI.
You can try their audio demos here. They have a number of preset voices, similar to Eleven Labs, Suno, and other AI audio generation tools.
Conclusion
There is a constant stream of announcements of new AI products, features and models that evolve and improve AI application interfaces and user experience.
Recent releases support: Prompt editing (Copilot prompt auto-complete), fill-in-the-middle code completion (Codestral), tool use from models (Hugging Chat with Command-R), multi-modality (LangChain and Redis), low-latency audio interaction (Cartesia’s Sonic), and much more.
Expect more AI multi-modal support that allows mixing of text, image, video and audio. Expect AI apps to improve with more editable inputs (prompts) and more controllable generative outputs. AI audio interfaces will become smoother, lower latency and more natural.
We haven’t seen all that could be possible with full multi-modal (video, audio, image, text, rich documents) inputs and outputs. There is a place yet for some creative surprises in AI interfaces. So expect the unexpected, on the upside. AI keeps getting better.