


Alignment Problem
As a follow-up to our previous article on building LLMs on the pre-training of LLMs, we describe the next stage in training LLMs, fine-tuning. Before we get into how to fine-tune LLMs, let’s discuss discuss the why.
As LLMs grew in size and power, in particular after OpenAI released GPT-3 in May 2020, it became clear that while LLMs could perform a variety of NLP tasks, there was a challenge in getting it to follow user’s intent. Getting a model to follow user intent is called the alignment problem1, as we want models to be aligned with user intent.
Whether that intent was a question to be answered or a poem to be written, the answer or best response couldn’t be trained solely by predicting the next token. Answers would be mis-aligned because the training objective was misaligned. Further, the answer might be undesirable for other reasons. Ideally, we would want a model to produce an answer that is helpful, honest and harmless.2
Researchers quickly learned that getting good results on the GPT-3 model required giving it the right prompt. The lesson shared from the release of GPT-3 was that “Language Models are Few-Shot Learners”3. For a large LLM like GPT-3, giving it in-context prompt information on how it should respond improves the response.
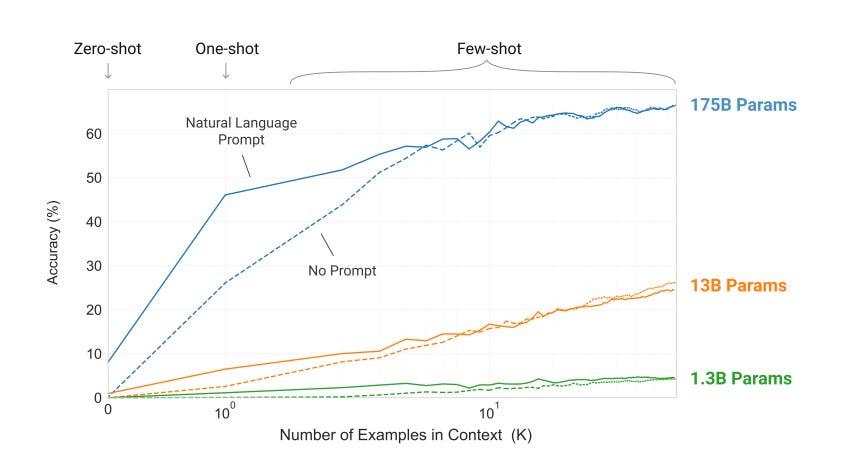
Specifically, you can provide good examples of request-response pairs of a particular type of query, and that tees the model up for giving the intended response. An example would be giving it translation examples in the context as a cue to request a translation of a phrase.

Instruct-GPT
While careful prompting can get you in-context learning and better responses, it’s clear that if you want to get true alignment to user intent, you need to train the model on a reward function directly tied to the whole response. That’s where fine-tuning comes in.
OpenAI researchers, in Training language models to follow instructions with human feedback4, looked for ways to fine-tune models in order to be better at alignment and instruction-following. The challenge is training on human preferences while keeping the process efficient and effective.
They developed Instruct-GPT by taking GPT-3 and fine-tuning it using Reinforcement Learning with Human Feedback (RLHF). This approach takes three steps:
Supervised fine-tuning: Collect a dataset of human-written demonstrations of the desired output, and then fine-tune the pre-trained LLM on on those specific human demonstrations using supervised learning.
Train a reward model: Collect a dataset of human-labeled comparisons between outputs from the LLM on a larger set of prompts, and then train a reward model (RM) on this dataset to predict which model output humans would prefer.
Optimize using reinforcement learning (RL): Finally, use the reward model and fine-tune our supervised learning baseline to maximize this reward using the PPO Reinforcement learning algorithm.
This process was illustrated in the Instruct-GPT paper as shown in Figure 3.
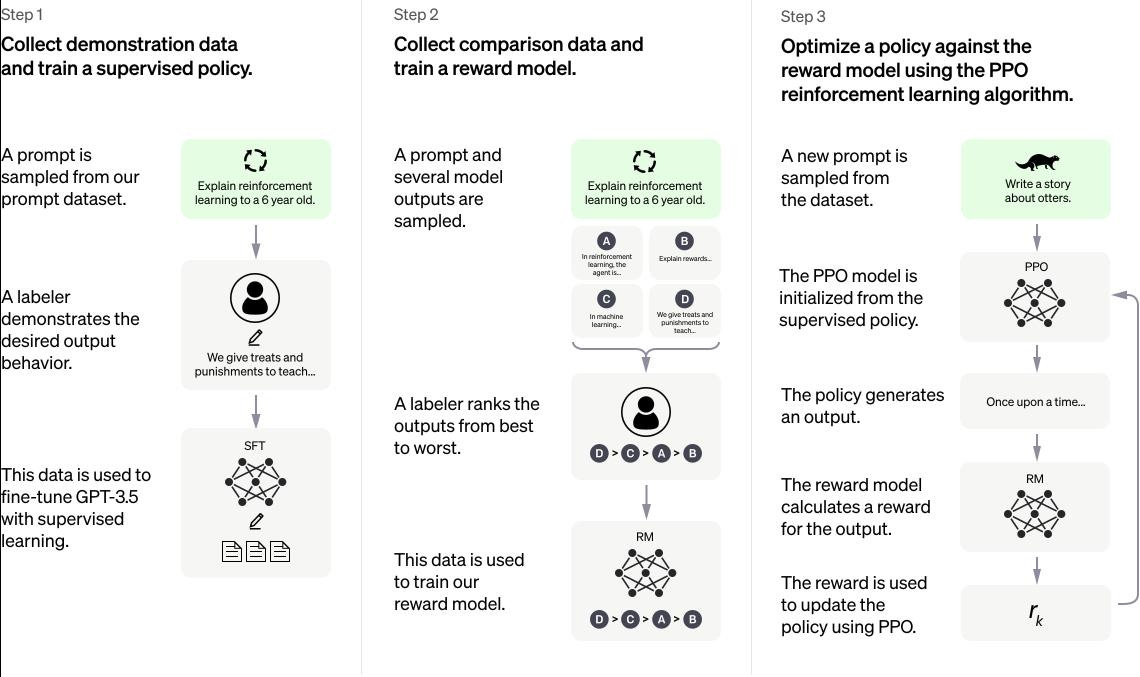
This process aligns GPT-3 to the stated preferences of the labelers on model responses, and the resulting model, instructGPT, produced output responses that were much preferred to the original GPT-3. The model showed this ability outside the specific dataset fine-tuning distribution, so it was able to generalize following instructions. It also showed improved truthfulness.
With further fine-tuning iterations and improvements, OpenAI was able to produce chatGPT. OpenAI’s took an LLM and through fine-tuning produced a general AI model that follows instructions and is useful across a broad range of tasks. The chatGPT model crossed a threshold of utility that helped it take the world by storm, and the rest is AI history.
The OpenAI development of GPT-4 used all the lessons of these prior developments, and added a few more layers of automation to extend RLHF and other fine-tuning techniques.5 Specifically they noted that even after RLHF, their model could exhibit undesired behaviors, such as generating undesirable content or conversely become overly cautious on safe, innocuous requests.
To have more fine-grained steering of GPT-4 output, they used the model itself as a tool, creating rule-based reward models (RBRMs). These are classifiers that provide a reward signal for RLHF fine-tuning to correct behavior, such as refusing to generate harmful content while not refusing innocuous requests. This yielded improvements in GPT-4 in both AI safety and alignment.
Conditional Pre-Training
In addition to supervised fine-tuning and RLHF, there is another approach to align language models with human expectations. This method is called Conditional Pretraining and can work in a more transparent and end-user controllable manner.
In this method, a large number of pre-training examples are tagged with labels that describe the content using human-understandable classifiers. This labeling can be performed in a mostly unsupervised fashion, utilizing existing machine learning text classification models. The result is more accurate and descriptive training data for both pre-training and fine-tuning process.

PEFT and LoRA - Low Rank Adaptation
Fine-tuning on all model parameters would scale with the size of an LLM, and with the emergence of LLMs with hundreds of billions of parameters, this can become a costly process. In order to efficiently fine-tune models, we need Parameter-Efficient Fine-Tuning (PEFT), fine-tuning on a subset of parameters in the model.
To address the challenge of fine-tuning LLMs more efficiently, the idea of LoRA, Low-Rank Adaptation of Large Language Models6, was proposed. LoRA freezes the pre-trained weights in the LLM, and adds additional ranked parameters at each layer. The Figure below shows the how this is partitioned.
Using GPT-3 175 billion parameters, LoRA cuts the number of parameters to be fine-tuned by 10,000 times versus full fine-tuning. This is a huge time and cost savings for fine-tuning, yet the results are surprisingly good, coming close to the results from full fine-tuning at a fraction of the cost.

Different LoRA modules can be trained to tune the same larger model for different tasks. Further, LoRA fine-tuning can be layered. This opens up the possibility of a single base AI model with large varieties of LoRA-fine-tuned models for different specific sub-tasks, like a single trunk with many branches.
This indeed has happened for image generation AI in the Stable Diffusion model ecosystem. A large variety of image generation AI models have blossomed through adaptive LoRA on top of the Stable Diffusion base image generation model.
Smaller LLM fine-tuning from larger LLMs
On the heels of Meta’s release of LLaMA in February, came the remarkable research result from Stanford, called Alpaca:
We introduce Alpaca 7B, a model fine-tuned from the LLaMA 7B model on 52K instruction-following demonstrations. On our preliminary evaluation of single-turn instruction following, Alpaca behaves qualitatively similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$).
As we noted in our article on this in March, this research showed that supervised fine-tuning from a larger model’s output is an effective short-cut to quickly improve performance on a smaller model (in this case LLaMA 7B). You could recreate high-quality LLM results ‘on the cheap’.
This led to a ‘gold rush’ of research follow-on papers and more open source models using similar techniques. One example of this is “Instruction Tuning With GPT-4,” which used GPT-4 to generate instruction-following data for LLM fine-tuning. The use of GPT-4 instead of human annotators automates the process and makes it much more efficient.
Or Is it a ‘false promise’?
A recent fly in the ointment of this approach came recently with the paper The False Promise of Imitating Proprietary LLMs, which critically analyzed results on fine-tuning small LLMs from larger LLM outputs. They found high human evaluation scores on small model outputs, but also found that:
… imitation models close little to none of the gap from the base LM to ChatGPT on tasks that are not heavily supported in the imitation data. We show that these performance discrepancies may slip past human raters because imitation models are adept at mimicking ChatGPT’s style but not its factuality.
It certainly makes sense that smaller models lack the parameters to reflect full world knowledge of larger models, but more research will be needed to check how performant these smaller models can become with this fine-tuning technique. Combining it with vector databases for ground-truthing may be one way to overcome its limitations.
Conclusion
The importance of fine-tuning - both SFT and RLHF - should not be under-estimated. Fine-tuning for instruction-following is the final missing piece - after word vectors, deep learning, transformers, pre-training unsupervised text corpus, and scaling - that made chatGPT what it is. It took fine-tuning to get LLMs to be instruction-following, turning GPT-3 into the ChatGPT that was useful and capable enough to go viral and take on the world.
References
Leike, J., Krueger, D., Everitt, T., Martic, M., Maini, V., and Legg, S. (2018). Scalable agent alignment via reward modeling: a research direction. arXiv preprint arXiv:1811.07871.
Askell, A., Bai, Y., Chen, A., Drain, D., Ganguli, D., Henighan, T., Jones, A., Joseph, N., Mann, B., DasSarma, N., et al. (2021). A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems (pp. 1877-1901) arXiv preprint arXiv:2005.14165.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J. and Lowe, R. (2022). Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155.
OpenAI. (2023). GPT-4 Technical Report. arXiv preprint arXiv:2303.08774.
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685.