
GPT-4, Experts, Blenders and AI Platforms
Scaling dense models is NOT all you need, you need a platform approach


GPT-4 is a Mixture-of-Experts Model
A remarkable revelation was made by George Hotz on a recent Latent Space podcast about the GPT-4 model. Hotz, aka Geohot, claimed (around minute 49):
GPT-4 is 220 billion parameters in each head and it’s an 8 way mixture model. They did a trick where they did 16 inferences.
That makes GPT-4 a 1.76T 8-way mixture-of-experts model. Hotz does not work for OpenAI so its possible this speculation isn’t right, but surprisingly, it got confirmation from other knowledgeable sources. Alberto Romero on Algorithmic Bridge goes into more details on this revelation. He points out that:
This is still a rumor, but has two reliable sources (Hotz and Chintala) outside OpenAI and a source at Microsoft implying its validity. Nobody at OpenAI has confirmed it.
If true, it is something of an OpenAI marketing coup. OpenAI kept architecture details secret, leaving many people to speculate and believe GPT-4 was a larger dense model, and thus more impressive than it might actually be. As Hotz put it, “A mixture of experts is what you do when you run out of ideas.”
No matter the details of the architecture of GPT-4 or how its built, its capabilities and results are the same and just as impressive.
Why would OpenAI go a mixture-of-experts approach? They would only do it if it’s a more compute-efficient approach to getting to GPT-4’s performance. It points to the mixture-of-experts approach as a more efficient way to train and serve LLMs than just scaling dense models.
Mixture of Experts AI Model Architecture
The idea of mixture-of-experts is not novel nor did it originate from OpenAI. In the past few years, before the release of GPT-4, there have been multiple efforts at scaling up LLMs as both ‘dense’ models and ‘sparse’ models.
For example, Huawei researchers released Pangu-Σ earlier this year, a 1T sparse LLM based on mixture-of-experts.
One paper in 2022, authored by researchers at Google, presented GLaM, a mixture-of-experts model that incurred substantially less training cost compared to GPT-3:
The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT-3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero-shot and one-shot performance across 29 NLP tasks.
The mixture-of-experts (MoE) architecture works by interleaving a gating layer with the multi-head attention layer. Each gating layer in MoE consists of a collection of independent feed-forward networks as the ‘experts,’ and the gating ‘selects’ from one portion of the network, in effect selecting one ‘expert’ to pass through.
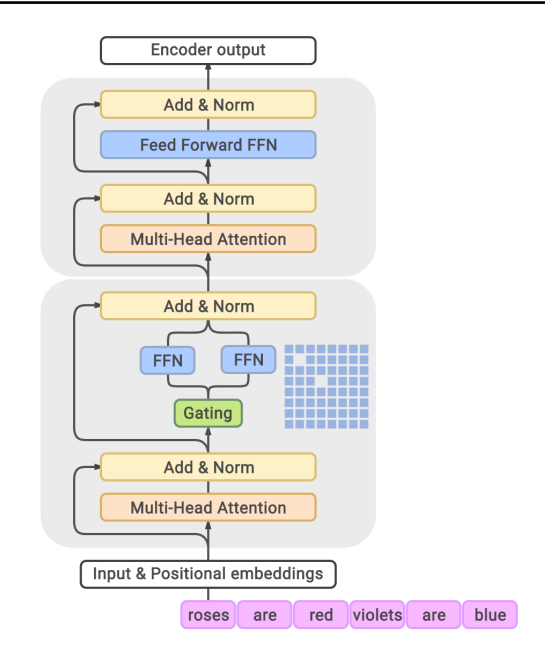
The largest GLaM has 1.2 trillion parameters in its model, with 64 experts per MoE layer. GLaM is sparsely activated, meaning that only a fraction of the parameters are activated in any given inference. Each token only activates 96.6B (8% of 1.2T) parameters at a time. Despite a larger total parameter count, the inference compute was half that of GPT-3, and training compute was a fraction of that used for GPT-3.
This architecture yielded higher performance than GPT-3 at a lower cost.
In total, GLaM (64B/64E) outperforms GPT-3 in 6 out of 7 categories on average, indicating the performance gain is consistent. … GLaM MoE models perform consistently better than GLaM dense models for similar effective FLOPs per token. - GLaM Paper
OpenAI, with inference costs of almost a million dollars a day, is highly interested in any approach that could get more bang for the compute budget in their AI models. While the details on GPT-4 are speculative, it’s a natural conclusion that they tried this approach, found that it was beneficial, and used it to build GPT-4.
LLM-Blender
A recent paper called LLM-BLENDER presents an ensembling framework that combines the strengths of multiple open-source large language models (LLMs). It addresses the observation that the optimal LLMs for different examples can vary significantly.

It consists of two modules: PAIRRANKER, which compares and ranks candidate outputs, and GENFUSER, which merges the top-ranked candidate outputs to generate an improved output.

The PAIRRANKER and GENFUSE modules are trained in a post-hoc manner on candidate outputs.
This ensemble approach has as its goal to “develop an ensembling method that harnesses their complementary potentials, leading to improved robustness, generalization, and accuracy.” It largely succeeds at it, but has limitations, namely the inefficiency of calling many candidate models.
They show final results that are superior to any of the component LLM.
The LLM Zoo Expands
What does this tell us about ideal architectures for LLMs? We have previously declared that we are in the era of large Foundation AI models. We have also explained that the LLM landscape is becoming quite diverse, with a mix of:
Top-tier ‘flag-ship’ general-purpose Foundation AI models
Special-purpose LLMs serving specific domains (such as finance, law, medicine)
Smaller, open-source ‘edge’ models
We have learned from the experience of Alpaca, Vicuna and other ‘teacher-student’ models, that you can fine-tune models with examples from chatGPT and GPT-4, to create a higher-quality smaller model. The Orca model taught us that you can improve reasoning if you curated the fine-tuning training data with more ‘step-by-step’ chain-of-thought prompts and responses in GPT-4.
The recent phi-1 model result (“Textbooks are all you need”) suggests that high quality training data enables very high quality smaller models. Better data curation becomes another lever for optimizing models.
The LLM-BLENDER and mixture-of-experts are yet more 'tricks’ up the sleeve of model developers to get more out of less.
Platform Architectures for AI
Based on GPT-4’s prowess and capabilities, it was widely assumed that large foundation AI models would be the dominant AI model. “One AI model to rule them all.” It has emergent capabilities you could not achieve otherwise, including self-reflection and improved transfer learning.
Since March, the progress on smaller open-source models has been so impressive that it’s clear the major tech companies have no real moat. It’s unclear which AI models will be the most dominant - a few of the largest Foundation AI models or a diversity of smaller models?
One way to pose the question: Are you better off with 10 specialized AI models for 10 different use-cases, or one general AI model to do it all?
Since most AI models will eventually end up as features inside a piece of software, any AI model serving that role needs to be trained on ONLY that role, no more no less. Multiple specialized models is more efficient, but on the other hand, we might just want to pick one best AI chatbot as our generalist AI assistant.
Most industries with diverse customers and use-cases are segmented into various sub-markets, because each customer wants unique features which may require different products. In the automotive industry, for example, this breaks down into sub-markets for trucks, SUVs, sports cars, luxury sedans, family minivans, etc.
To maximize efficiency while pleasing customers, manufactures take a platform approach, providing a common product platform to share common features, while allowing for customization and specialization on top. Carmakers might have the chassis, engine and other systems common across different models, while allowing feature and style customization.
The platform architecture pattern is applied to AI models with fine-tuning: A common AI model is pre-trained, then users perform fine-tuning on that common AI model to specialize it for specific applications.
A mixture-of-experts architecture turns things on its head, with specialized experts as literal subsets of the overall more general models. Combining smaller models is another way to make a larger and better one.
Perhaps a future model approach might combine the LLM-BLENDER approach with mixture-of-experts. For example, take an existing pre-trained smaller model, merge it into a larger MoE architecture, then fine-tune the merged MoE model some more for specific tasks.
Scaling is not all you need. We also need more innovation in AI model architectures and datasets to improve them and make them more efficient. Part of those necessary innovations are creative platform approaches to be more efficient in building and serving AI models. Fortunately, that creative work is being done, and we are rapidly advancing and improving AI models.
AI is a fast-evolving technology and industry. As it evolves and improves, we will enjoy ever more diversity of AI models, both highly specialized ones as well as powerful and general AI models. No single approach will win; we users will win.