
Accelerating AI - Notes on Recent AI Progress
Fast AI progress - context windows expand, multi-modality extends, video gen improves, worlds get simulated, science accelerates, inference speeds up


Making Sense of AI Progress
This past week was the biggest week in AI perhaps since GPT-4 was launched a week ago. Stunning enough that our AI Week in Review for the past week left several news items on the cutting-room floor, while also leaving little time to digest and make sense of what these breakthroughs mean.
In this article, we will look into what the recent progress in AI means for the pace of AI progress, the path to AGI, and technology progress generally.
Context Is a A Solved Problem
Not just the two big releases, Gemini 1.5 and the Sora text-to-video, but also other groundbreaking AI research shows that those new AI breakthroughs aren’t a one-off. As I stated in my weekly:
These three above AI research results - V-JEPA, LWM, and Agent Foundation Model - all show us potential paths towards AGI: Massive context, natively multi-modal, world understanding, and “next action” predictions to navigate in the world. I believe AGI will have all those elements.
In particular, LWM - Large World Model - is an open AI model that expands the context window for an LLM to one million tokens. The Gemini 1.5 Pro is the first AI model in production to get to 1 million token context, but not the last.
Massive context windows challenge RAG (Retrieval Augmented Generation) and transformer alternatives (like Mamba) that have been sold as ways to get around limited context windows, but they don’t mean these additional methods aren’t still useful.
We can expect RAG to compliment larger context windows for more efficiency, and possibly a broader data set. Reducing a context window through context-processing up-front leads to more efficient and lower-cost handling of the input, and faster inference. Likewise, if alternative architectures win, it will be due to efficiency advantages.
World Models and Action Models
Another lesson gleaned from recent research results is the push towards world models and actions models. Multi-modal foundation AI models, such as Gemini 1.5 and GPT-4 Vision, that can take video, images, audio and text as input, and return all of the above as output.
We have spoken about Large Action Models (LAMs) in “The Rabbit and LAM,” and “An Interactive Agent Foundation Model” goes one step further in multi-modality to bring action modelling with other modalities together:
Our training paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction.
Using special tokens to speak the ‘language’ of action unifies action with other modalities. This is a path to AGI: Unified AI models that bring all these modalities together.
OpenAI is investing in robotics companies and looking at AI agents, while Google is researching AI for robotics and published the PaLM-E AI model last year. We can expect some sort of unification of action and multi-modality in the next generation of frontier AI models.
V-JEPA and Sora
The release of V-JEPA and Sora at the same time begs a question of similarity and differences in approaches to handling and understanding video.
While different models and addressing different tasks on video, the pre-training method - if you squint hard enough - is similar:
Sora’s Diffusion transformer de-noises a video by (converting to latent space then) predicting a correct image to replace noise pixels.

Figure. Sora translates image into a latent space. 
Figure. Sora uses a diffusion transformer model that denoises images and video. V-JEPA transformer predicts a video by (converting to latent space then) predicting a correct image to replace hidden pixels.



In both cases a form of self-supervised ‘missing pixel prediction’ is used, similar to how ‘next token prediction’ works in LLMs. Moreover, V-JEPA claims to be able to be applied to a variety of downstream tasks that use or generate video.
AI image generation models have rapidly gotten better with many innovations in re-using and merging prior AI model and training concepts. We can expect similar innovation in AI video generation of merging and re-using concepts.
Sora AI for Virtual World Simulation
Sora represents not just a breakthrough in text-to-video. The implications of disrupting the entire film, gaming and entertainment industries is big enough, but there’s more.
Perhaps OpenAI gave away the game with their research title: “Video generation models as world simulators.” The “more” is real-world simulation.
Here’s why: To get to good video generation that ‘makes sense’ requires real-world knowledge. Dr Jim Fan explains why Sora shows how physical rule understanding is an emergent property of video generation:
Sora's soft physics simulation is an *emergent property* as you scale up text2video training massively.
Very similarly, Sora must learn some *implicit* forms of text-to-3D, 3D transformations, ray-traced rendering, and physical rules in order to model the video pixels as accurately as possible. It has to learn concepts of a game engine to satisfy the objective.
What are the implications? There are many. Yes, AI can displace Unreal Engine-style computer-generated animation and generate virtual scenes on the fly. This changes movie productions, enables custom video games.
However, beyond that, such AI can be used to create virtual worlds. Such AI world-building opens up applications in design, CAD, and engineering. It can help train robots as well as autonomous vehicles, whose algorithms can be trained in the virtual world much more cheaply than the real world.
Also, if AI can get an emergent real-world physics understanding, then AI can replace physics-based simulation for a number of tasks, as it can get close to ground-truth accuracy with orders of magnitude less computation. The implications are huge.
How AI Accelerates Science
If Sora-like video generation picks up on real physics, it fits a pattern of prior AI model breakthroughs in science.
We have seen this pattern where AI models have been used to advance science through modeling that simulates far faster but is accurate enough to allow massive search and generative. It works like this:
Generate a lot of high-quality ground-truth (or physics simulation) data to describe some physical reality - molecular dynamics, weather, protein folding, chemical reactions, etc.
Use that data to train an AI model to replicate those ground-truth predictions in the model, in effect creating a ‘model of a model’.
Use AI inference to make predictions. These predictions are typically orders of magnitude faster than the original physics-based simulation. If the AI model has low enough error, its predictions will be almost as good as detailed simulation, but much faster to generate.
One example was the ground-breaking GNoME research by Google Deep Mind, that discovered almost 400,000 stable crystals, ten times the number of prior known crystals. The method was a graph neural network that ‘understood’ atomic-level interactions, trained on real physics interactions. From that, it could characterize novel interactions, quickly and accurately.
Similarly, “AI-assisted robot lab develops new catalysts to synthesize methanol from CO₂.” ETH researchers used AI to quickly explore potential chemicals with desired properties:
The researchers working on the Swiss Cat+ technology platform at ETH Zurich, led by Paco Laveille, have now developed a fully digitalized and automated method that enables them to find new and better metal catalysts much faster than before. Their process consists of a combination of artificial intelligence (AI) for calculating promising catalyst compositions and an automated synthesis and test laboratory.
With this infrastructure, it took the team less than six weeks to successfully develop about 150 catalysts compositions for producing methanol from CO2.
Another example from last December is “Novel AI-based approach for more accurate RNA 3D structure prediction.”
The pattern is set: Any area of science that utilizes detailed simulation to find ground-truth will be disrupted and accelerated by AI modeling that can do similar simulation work much faster. Scientific advances will accelerate.
AI takes on weather prediction
Another example of AI displacing traditional simulation is the weather. In November, DeepMind announced that GraphCast, a model trained on 40 years of weather data, was more accurate than the “gold standard in weather modeling,” the European Centre for Medium-Range Weather Forecasts.
Recently, a startup called WindBorne Systems announced AI_based weather predictions that surpassed DeepMind in key benchmarks. Yet AI’s real benefit is speed, replacing compute-intensive physics models with AI models that are “relatively fast and cheap to run after that initial process” of training the AI model.
Artificial intelligence is starting to help federal weather forecasting, with the Federal Government standing up an organization called AI2ES.org (NSF AI Institute for Research on Trustworthy AI in Weather, Climate, and Coastal Oceanography is a mouthful). The big benefits of AI over the hugely detailed weather and climate models is speed:
Right now, those numerical weather prediction models are extremely expensive to do an ensemble. Once you’ve trained an AI model, you can do an ensemble very, very cheaply. So, you could, in just a few seconds get a thousand ensembles.
That speed advantage turns into other advantages: Earlier warning of extreme weather events, ability to do more detailed, customized, and tailored simulations and explorations.
Groq accelerating inference
Groq is an AI chip startup founded by Google alumni. The have created the Language Processing Unit (LPU™) inference engine, aka a “Software-Defined Scale-out Tensor Streaming Multi-Processor,” designed specifically for efficient transformer-based AI model inference.
Groq has touted the world-pace-setting speeds of inference on their LPU, for example achieving “300 tokens per second per user on Llama 2 70B running on an LPU™ system.” X users report a blazing 500 tokens per second on very good AI models like Mixtral 8x7B, also here.
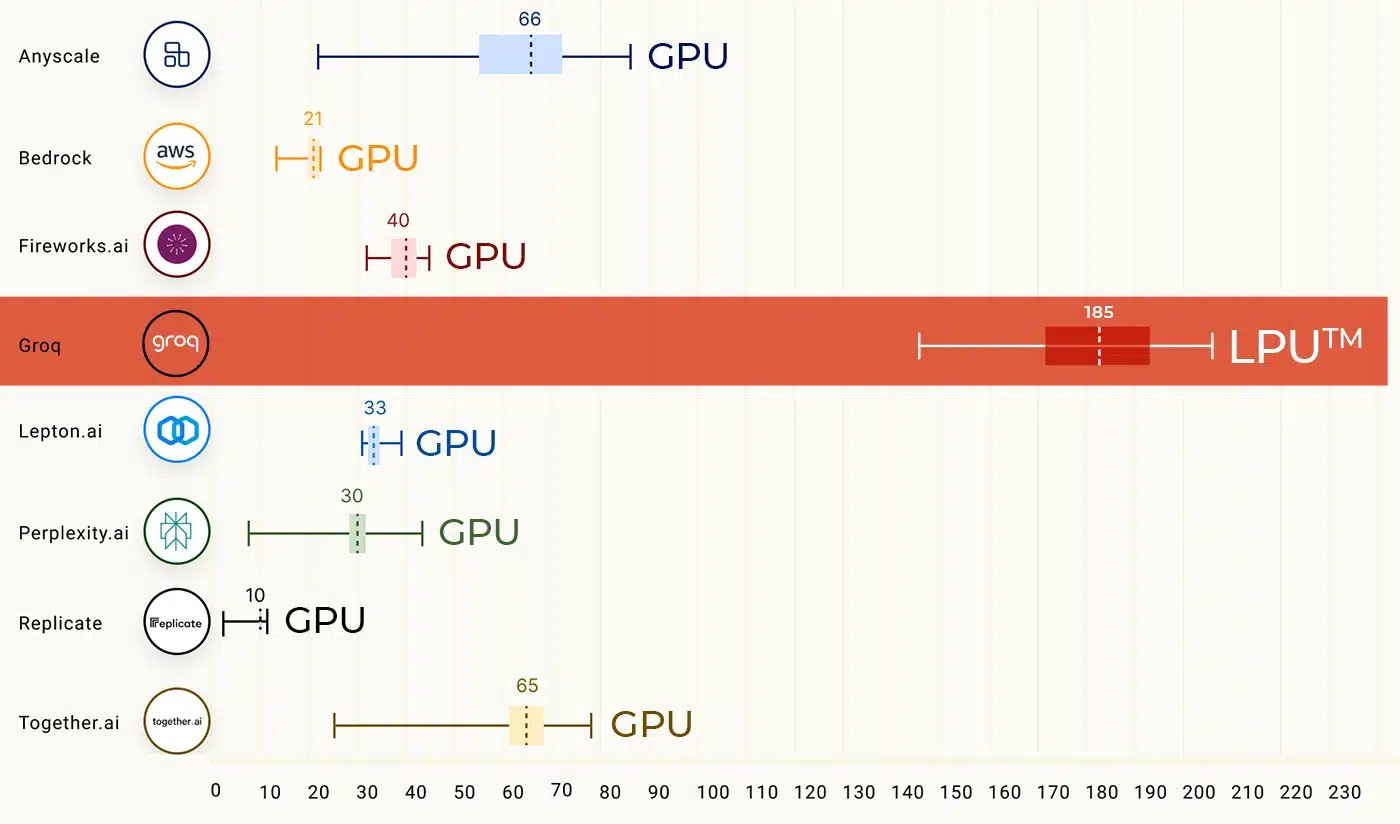
By being software-defined but specialized for tensor operations, Groq may have built a better mousetrap.
But others aren’t standing still. Last fall, Nvidia delivered 2x inference speedup on H100 from optimizations, and are delivering 4x speedup with H200 on pre-training. Leading tech companies like Microsoft are working on specialized custom AI chips, while Softbank launches a $100 billion AI chip fund to compete against Nvidia in the AI chip market set to double to $119 billion by 2027.
As the current AI chip leader, Nvidia commands an enviable position, with the high gross margins and market cap of a winner. But competition never sleeps, so in this high-stakes race, the AI chips and systems will be constantly be getting better in order to stay on top.
AGI Is Closer
This acceleration - in AI hardware, in AI inference, in AI model accuracy, in AI-accelerated science - is all to say everything in AI is getting better, and the prediction game isn’t if AI technology improves massively, but how soon.
In one of my earliest articles in this Substack in the Spring of 2023, I gave some fundamental points about AI’s present and future.
I stand by my statements:
2023 was the year of AI, an inflection point in AI adoption.
Current SOTA AI is good enough to change the world.
AI is not standing still and “we don’t know the real limits of AI.”
I also said “We will have super-human AI by 2029” and we would have AGI by 2029. I thought that was a bold prediction. Given the rate of progress in AI, improving at an exponential pace, this may turn out to be conservative.
What last week’s news in AI reminded us is that, as George Gilder once put it (and I quoted in that prior article): The future is closer than you think.
Longer context window doesn't mean increased reasoning capabilities (even ignoring loss in the middle phenomenon). Context window and reasoning window are separate aspects. RAG with less context is possibly still required to better align the responses.