AI Year 3, pt 4: Frontier AI Model Progress
Frontier AI model progress in 2024 and beyond - efficiency, competition, open source, and scaling.


Predictions and Progress in Frontier AI Models
This AI Year 3 Article Series covers the current state of AI and asks the question:
Where do things stand in AI, a little more than 2 years after ChatGPT kicked off the AI revolution?
Our prior articles in this series focused on reasoning and multimodality. Part 1, The Meaning of o3 discussed the o3 model release and AI reasoning models, and Part 2, The Fourth Turning put AI reasoning models into the context of AI progress overall. Part 3, AI progress for 2024 - Multimodality, looked at AI progress in generative AI for audio, images, and video, as well as multimodal LLMs.
This article looks at the state of progress in frontier AI models, i.e., the most advanced LLMs and multimodal LLMs.
We predicted continued rapid advances in frontier AI model efficiency and quality at the start of 2024, and our specific predictions were for the most part met: More efficient AI models, open-source AI models improving and closing some gaps, and fast-following AI model development from more AI labs. Today, LLMs can get to GPT-4o level capability with remarkably small parameter count.
Yet the biggest surprise is the stalling of pre-training scaling far beyond the GPT-4 level.
Open-Source AI Models Break GPT-4 Barrier
Our January 2024 regarding open-source AI was as follows:
Prediction: Open-source GPT-4 equivalents will be released in 2024.
The result: True.
We said that this was less of a prediction than a matter of roadmaps, given Meta’s promises. Meta delivered Llama 3, then Llama 3.1, with a massive 405B dense model that beat GPT-4o, but the more practical 70B and 7B models kept getting better, with capable 9B and 90B Llama 3.2 multimodal LLMs and with a Llama 3.3 70B model that outperforms GPT-4o.
Meta plans Llama 4 releases in 2025 that will use 10 times the compute as Llama 3 training releases and will focus on reasoning and voice interaction. Meta will stay close to the leading-edge using their vast computing resources.
Mistral, which came out of the gate in 2023 with the excellent Mistral 7B AI model, has since released improved AI models such as Mistral Large and produced two Codestral iterations, latest one Codestral 25.01. However, Mistral moved away from open-source AI models, requiring a license for commercial use of AI models and promoting their Le Chat interface.
Chinese AI labs have produced several competitive frontier AI models, many of them open-weights or open-source, notably the open-weights Qwen models from Alibaba and the DeepSeek models.
The Qwen 2.5 open-weight LLM family was released in September. Qwen-2.5 consists of models ranging from 1.5B to 72B and includes specialized models for math coding, which, when released, were SOTA for their size. Qwen-2.5-72B and fine-tuned variations of it top the open source LLM leaderboard.
We also predicted the rise of mixture-of-experts (MoE) models, saying: Open-source goes MoE.
Mistral’s 8 x 7B Mixture of Experts AI model pioneered this approach for open-weights models. More recently, DeepSeek utilized the improved training and inference efficiency with MoE models to deliver an open-weights MoE DeepSeek V3 that performs better than GPT-4o, yet requires only 37B activated per token at inference.
Open Datasets
Prediction: Open-source data expands.
There have been continued releases of data for LLM training, improving on both quantity and quality available. Since the Red Pajama V2 30 Trillion token dataset release in 2023, there has been a focus on improving the quality of input datasets. For example, HuggingFace released the FineWeb dataset, an open-source refined and curated 15 trillion token dataset. We have also reported on open-source multi-modal datasets such as MINT-1T and MedTrinity, a multi-modal dataset for medical AI.
The availability of large-scale open datasets has meant that academic AI model efforts, such as recently released Bamba, built on an open-source stack:
We introduce Bamba-9B, an inference-efficient Hybrid Mamba2 model trained by IBM, Princeton, CMU, and UIUC on completely open data. At inference time, the model demonstrates 2.5x throughput improvement and 2x latency speedup compared to standard transformers in vLLM. … We also release tuning, training, and extended pretraining recipes with a stateful data loader, and invite the community to further improve this model.
Small and Efficient LLMs Rise
We will see more surprisingly great smaller models in 2024 that train longer on more high-quality data but have fewer parameters. … Quality beats quantity, but we will see AI models that scale both to get GPT-4 level capability in surprisingly small packages.
Prediction: Small models become a Big Deal as AI models get more efficient.
Outcome: True.
This prediction was based on our observations in 2023, where smaller models like Mistral 7B, Phi-2 2B, and Yi 34B outperformed prior larger models, showing that training longer on higher-quality training data could lead better quality and more efficient LLMs with smaller parameter count.
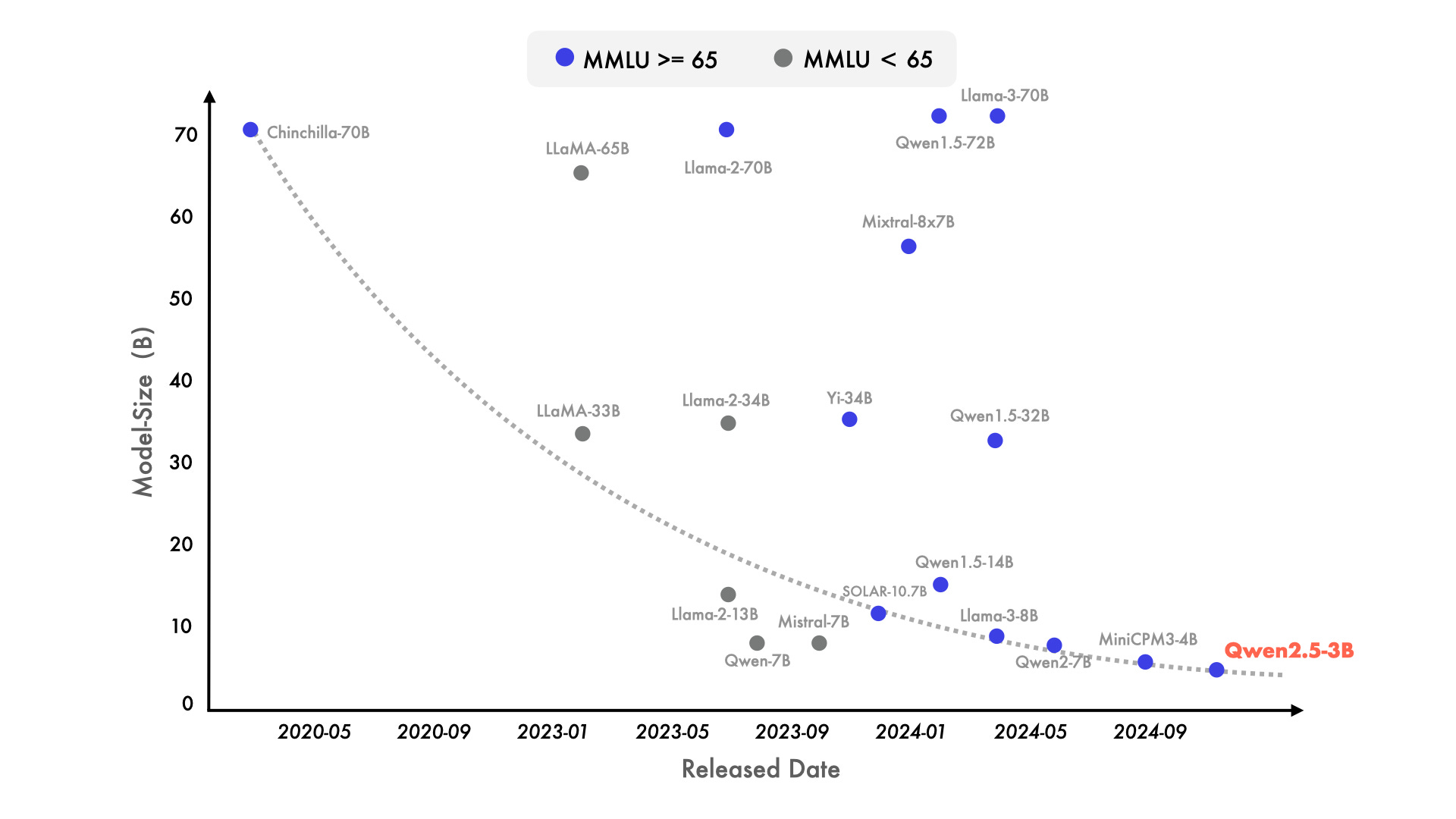
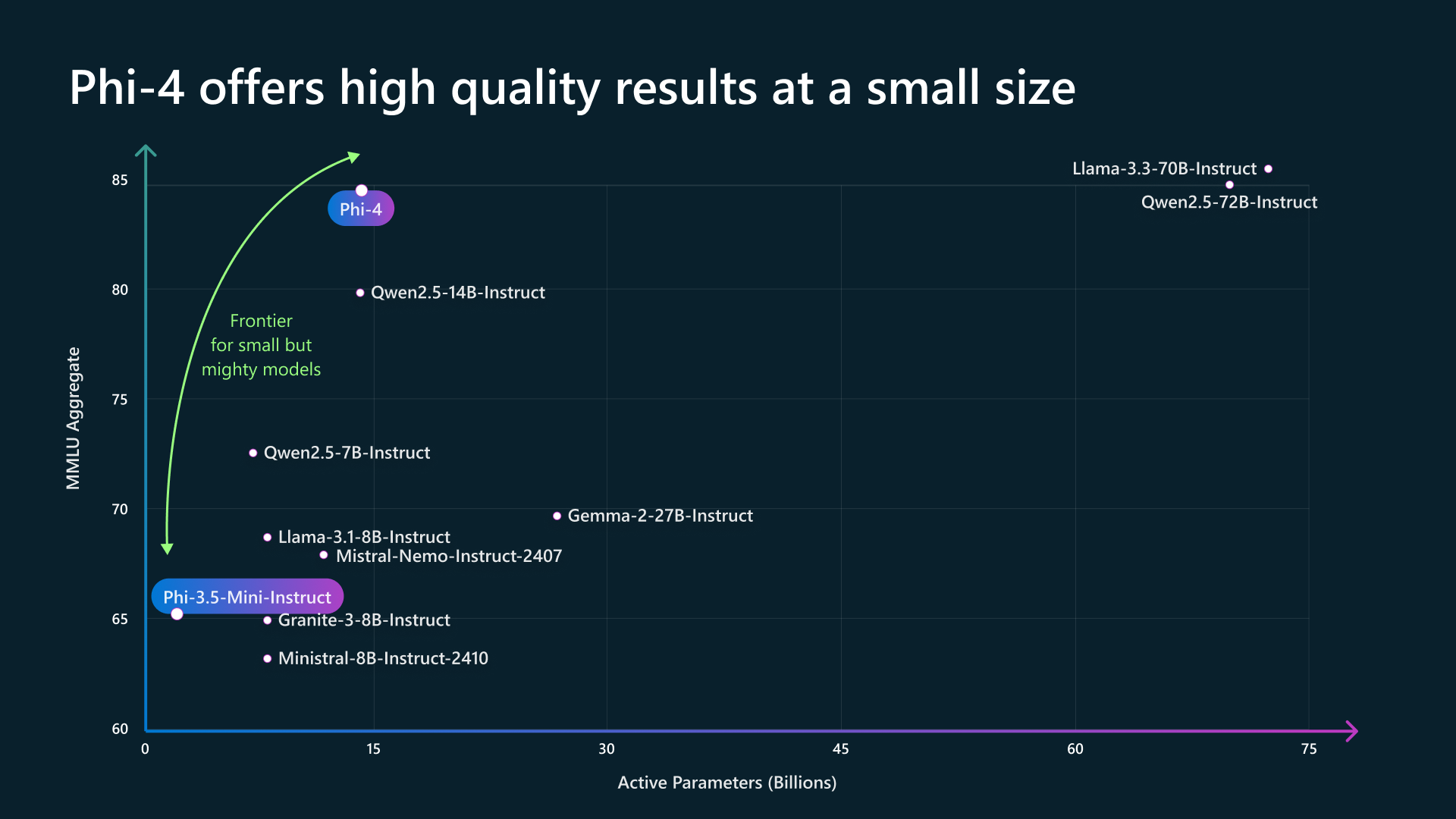
In 2024, this trend continued, and the question became: How far can this trend go? Microsoft delivered more Phi models that pushed the envelope on quality and efficiency, culminating with the Phi-4 release that showed that a 14B LLM could achieve results comparable to AI models with 5 times the number of parameters.
We predicted:
More highly capable quantized AI models will be ready for edge devices. …
Quantization has indeed been helpful for running local AI models locally, as FP-4-quantized AI models cut the LLM memory footprint in half with only minor degradation in model performance. For example, the FP-4-quantized Phi-4 14B model fits in 9.1 GB of GPU memory, while the Qwen2.5-coder 32B model takes 19GB. This has helped fulfill this prediction:
Frontier AI Model Competition and Claude 3.5 Sonnet
The combined effect will be a flood of new very capable models approaching GPT-4 levels, with several leaders exceeding where GPT-4 is today. GPT-4 level multi-modal AI will be a cheap commodity available from multiple AI model providers by the end of 2024.
We now have many competitive GPT-4 level AI models, both the open-source contenders and those from competing proprietary AI labs. Anthropic’s Claude, X.AI’s Grok, and Google’s Gemini are the three leading proprietary AI competitors to OpenAI.
In January 2024, we predicted this:
Anthropic’s Claude 2 managed to get as close to GPT-4 as any competitor … None has matched GPT-4 yet, but Anthropic and others will this year, as “fast followers”.
Claude 3.5 Sonnet, released in June, wasn’t just a follower, but became the leader as the best AI model for writing support and coding assistance. In October, Anthropic released an update to Claude 3.5 Sonnet that gave it enhanced reasoning, state-of-the-art coding skills, computer use, and a 200K context window.
Grok from X.AI has been a later entrant, forming in 2023, but their August 2024 Grok 2 release was a GPT-4o-level competitive AI model with multimodal capabilities.
The Elon Musk-led X.AI team has great ambitions and a massive supercluster for AI model training, and they are using it to train Grok 3 at 10 times the level of Grok 2. The Grok 3 release is imminent.
Google Rises with Gemini 2.0
Google. Google bought Deep Mind in 2014 and funded much of the AI research that made the generative AI revolution possible. Yet in 2023, Google seemed a hapless also-ran to OpenAI in the wake of GPT-4’s release. Google’s initial Gemini releases were good but still OpenAI managed to out-shine them.
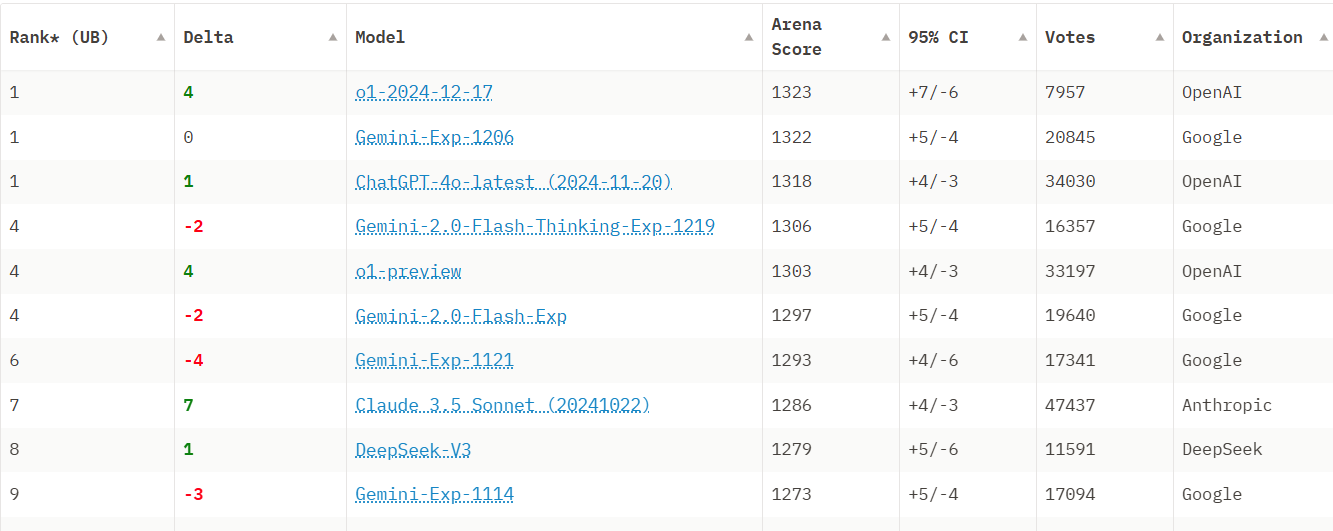
Finally, Google’s Gemini 2.0 release and their other powerful model releases last month (Veo2, Imagen 3, etc.) broke the spell of being over-shadowed by OpenAI. Gemini 2.0 models took top positions on the LLM Arena leaderboard, with Gemini-Exp-1206 aka Gemini 2.0 Advanced holding the leading position (still holding as of Jan 20th, 2025). Google now offers a best-in-class AI model across a range of tasks.
Our take on Google’s Gemini 2.0 release was “Google Strikes Back.” Exponential View wrote further details on Google’s AI comeback story “A Phoenix in Silicon Valley.”
Google releasing SOTA AI models doesn’t mean OpenAI has fallen behind or fallen short. If anything, with OpenAI releasing the o1 reasoning model and promising to release o3 in coming weeks, while Google has their own reasoning model with Gemini 2.0 Flash Thinking, the competition has just moved up to the next level.
The Case of the Missing Whale LLMs
We predicted an OpenAI release that never came:
OpenAI GPT-4.5: OpenAI will continue to outpace others, and to do so, it will have to release an improvement to GPT-4 this year.
The biggest “miss” for AI in 2024 is the non-release of any larger frontier AI model that went significantly beyond GPT-4o in its pretraining. Didn’t Kevin Scott, CTO of Microsoft, share a graphic earlier this year showing how much more training was going on to make GPT-next?
Yes, he did, but reports came out late in 2024 that OpenAI’s Orion training runs were missing their target:
Some OpenAI employees who tested Orion report it achieved GPT-4-level performance after completing only 20% of its training, but the quality increase was smaller than the leap from GPT-3 to GPT-4, suggesting that traditional scaling improvements may be slowing as high-quality data becomes limited.
This isn’t a one-off issue with OpenAI. In mid-year, Anthropic said Claude 3.5 Opus was coming soon, but they later dropped it. Google released Gemini 1.0 Ultra but there’s no Gemini 2.0 Ultra. Why?
The bottleneck seems to be with obtaining data with sufficient quality to scale AI model performance. The Phi-4 model from Microsoft shows that data quality matters, so even substantial poor-quality data won’t improve AI model results over an AI model trained on a smaller higher-quality dataset. As Ilya Sutskever put it, we may be reaching “Peak Data.”
Multiple AI labs have promised new AI models soon, trained at much larger scales than GPT-4 was in 2022. The imminent release of Grok 3, Llama 4 and OpenAI’s Orion should reveal much, and give us an updated understanding of LLM pre-training scaling, its progress and its limits.
Conclusion – The Current Leaderboard
Frontier AI model progress in 2024 in this area brought surprises as well as expected rapid progress:
Open-source AI models – many advances in open AI models, with some at GPT-4 level.
Improved efficiency - SOTA frontier AI models now come in a more efficient package.
Greater competition - several “fast-following” AI labs delivered SOTA frontier AI models.
Slowing of LLM pre-training scaling of performance beyond GPT-4o levels.
The proof of progress is in the Arena LLM leaderboard, where Google dominates with 5 of the top 10 AI models (including Gemini 2.0 Advanced and Flash Thinking), OpenAI’s o1 takes the top spot, and DeepSeek V3, Claude 3.5 Sonnet, and GPT-4o round out the top ten. (Note: This ranking uses style control filter.)
All of these AI models were released in the fourth quarter of 2024, showing that AI progress continues to be rapid and the frontier AI model race to be highly competitive. The competition and the innovation from multiple AI labs is not letting up, so expect more rapid progress in AI in 2025.