
AI Year 3, pt 3: AI Progress for 2024 - Multimodality
2024 predictions and AI progress on image, video and music generation AI models, and multi-modal AI models.


Predictions and Progress: A 2024 Retrospective
2024 is the year when AI really makes our lives easier and better in profound ways. … and in 2024, AI will be here to stay, being a part of our daily lives. – AI Changes Everything, Jan 2024
This AI Year 3 Article Series covers the current state of AI and asks the question:
Where do things stand in AI, a little more than 2 years after ChatGPT kicked off the AI revolution?
Since the “ChatGPT moment” in late November 2022, there has been rapid and massive AI progress, and it didn’t slow down in 2024. Multiple major AI release announcements in the end-of-year release rush capped off a busy 2024 with a bang. It was the AI equivalent of climbing to the peak of a mountain, so we are due to take a breath and enjoy the view.
Our prior articles in this series focused on reasoning. Part 1, the Meaning of o3, discussed the o3 model release, and Part 2, The Fourth Turning, confirmed that frontier AI models are now AI reasoning models, and put AI reasoning models into the context of AI progress overall. This article, Part 3 of the series, looks at our 2024 predictions made 12 months ago and compares it where AI progress stands right now.
In 2024, we encountered both surprises in AI development as well as expected rapid progress in AI: More efficient AI models, open source closing some gaps, the aforementioned AI reasoning models. What stands out as the biggest story is that 2024 was the year of multimodality, and the biggest leaps in progress were made in generative audio-visual AI – AI image generation, AI video generation, AI audio generation, and multimodal LLMs.
Image Generation gets Close to Perfect
Photo-realistic AI image generation is getting so perfect, it passes the visual Turing test; you cannot tell AI versus real photos. AI images are displacing stock photos for advertising and marketing copy. – AI Changes Everything, Jan 2024
Prediction: AI image generation gets to perfection. Outcome: True.
AI image generation models were already excellent at the start of 2024, but they made great strides this past year. AI image generation models now adhere to prompts better, have higher resolution, are faster, and controls and interfaces have vastly improved.
The top AI image generation model for 2024 is Flux.1 by Black Forest Labs, the AI developers behind Stable Diffusion. They released Flux.1 in July, which quickly gained attention for its advanced architecture and SOTA image generation. Then they followed up in November with Flux.1 Tools, extending the model to do infilling, outpainting, remixing, style-following, and structure-preserving image modifications (like retexturing). They also released an Ultra mode and raw mode that can generate hyper-realistic high-resolutions images. It’s also been the basis for image generation on xAI’s Grok.
Google's Imagen 3, available on their ImageFX tool, has emerged as a strong contender with its high-quality, high-resolution photo-realistic outputs. Midjourney still leads in artistic and creative image generation.
Many other excellent choices abound: Open and customizable Stable Diffusion 3.5, open-source DeepFloydIF for photorealistic outputs and exceptional text rendering, Dall-E 3 on Bing, Adobe Firefly on Adobe's Creative Cloud suite, Ideogram, and Leonardo.AI. All these offerings have improved their AI models and their interfaces and add-on tools to edit, remix and upscale images.

My current go-to AI image generation tools are Google’s Imagen 3 for photorealism, Ideogram for text rendering, and Grok, which uses Aurora, based on Flux.1.
AI Video Generation Gets Real
By the end of 2024, AI video generation will make leaps and bounds improvement in video quality, speed, length, attention to detail, and adherence to prompts. – AI Changes Everything, Jan 2024
Prediction: Generative AI for music and video gets real. Outcome: True.
Video generation achieved massive progress in 2024. The Sora announcement in February set the bar and expectations high. Two surprises in 2024 since that announcement have been the number and variety of interesting and competitive AI video generation models and tools that came out, but also how long it took OpenAI to finally make Sora available.
When Sora was released in December, it proved worth the wait; they released not only an excellent AI video generation model but also an AI video generation tool for creators. We now have multiple AI video generation models that are ‘Sora-level’ or close, which we covered in our December 2024 article on Sora’s release:
Google’s Veo 2 is SOTA for its realism, prompt adherence and 4K resolution.
Kling 1.5 generates 1080p videos and adds tools like Motion Brush to control animations.
Dream Machine from Luma Labs has cinematic quality and is now on iOS.
Runway, the original maker of AI video generation, now has Runway Gen-3 video generation, enhanced with advanced camera controls.
There are open-source alternatives now, such as Genmo Mochi-1 as well as Tencent’s Hunyuan Video.

AI video generation made huge leaps in 2024, and the progress will accelerate this year as multiple competitors race to be the best in the category. Expect longer video generation, higher resolution, better fidelity and prompt adherence, more realism, and greater controllability. AI video generation tools will also add more useful features, such as character consistency, sound effects (as demonstrated by Meta), and better tools for AI video editing.
AI image generation has been leading AI video generation by 12-18 months and is getting close to perfection. In the next 12-18 months, AI video generation will follow that trend, improving to near perfect video generations and radically transforming video production.
Music Generation Goes Vertical
AI music generation is also on the cusp of going vertical. … With tighter controls and sound editing, ability to generate based on specific detailed prompts, and use of other modalities, the remixing and creativity options for music is endless. – AI Changes Everything, Jan 2024
The best-in-class music generation application is Suno, which came out of stealth in December 2023. Their rise has been a 2024 story. The recent Suno AI 4.0 release is leaps and bounds beyond what was available a year ago, offering complex song structures, better vocal quality and 4-minute music generation. This category has exploded in utility and popularity.
There are several alternatives in this space: The leading music generation app Udio released Udio v1.5 in July 2024, offering improved audio quality. Google’s MusicLM is an experimental AI music generation system based on Google research on this topic; Tad.ai launched their Riffusion text-to-music AI model in October 2024.
In the music generation space as with image and video generation, there are several high-quality AI models offered options to choose from now, and both quality and choices will continue to rapidly improve in 2025. One can imagine more enhancements, from precise multi-track music composition controls, longer generations, and various remixing possibilities. It will be limited only by the creativity of the AI model development teams.
Frontier AI Models Become Natively Multimodal
Prediction: More competition on multi-modal frontier AI models. Outcome: True
We saw the multi-modal future coming. Frontier AI models are no longer just text-only LLMs with a chatbot interface, they are multi-modal AI models trained to reason on images and video that can interact via voice. We know have multiple multi-modal AI models from all leading AI labs.
Google will live down their infamous faked up Gemini demo by making audio-video AI interaction mode a real capability of their AI models in 2024. – AI Changes Everything, Jan 2024
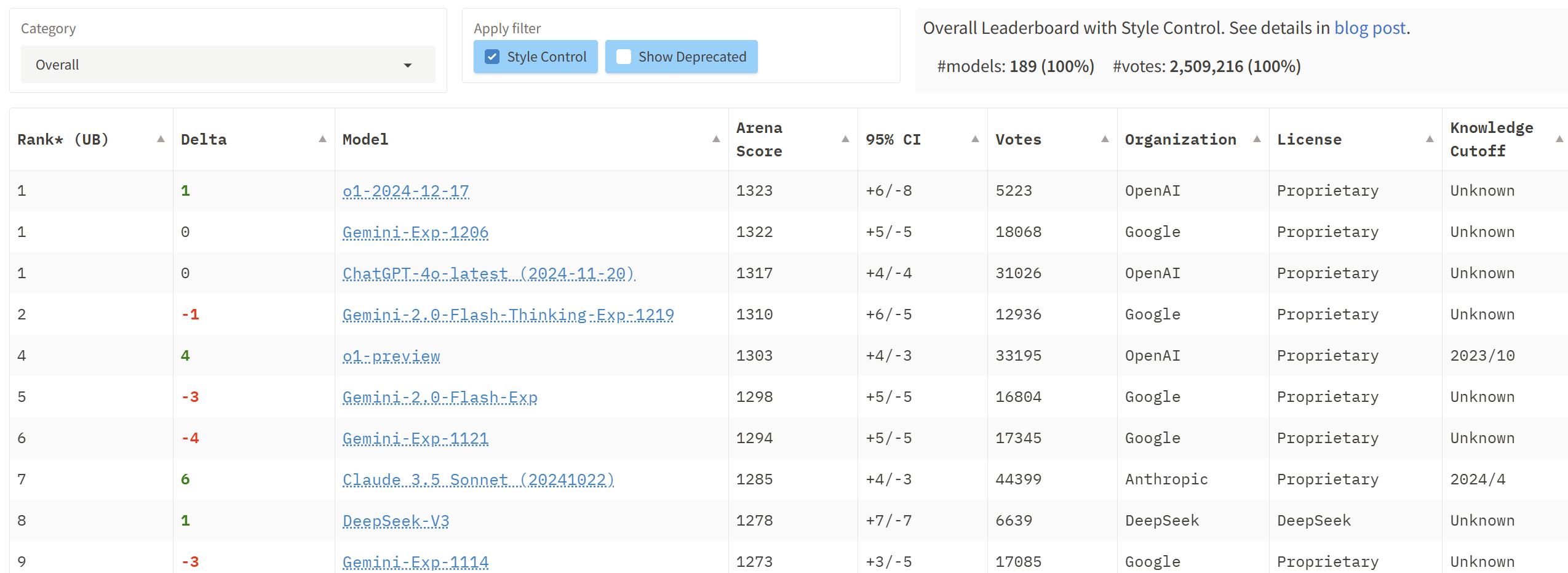
In December 2023, Google released Gemini 1.0, the first native multi-modal AI model. We were looking for Google to lead the way on multi-modal frontier AI models and beat GPT-4 with a Gemini Ultra. While their Gemini Ultra didn’t quite live up to their claims, Google delivered a GPT-4 beater in the form of Gemini 1.5 Pro. Then they made incremental improvements and capped it off with releasing SOTA Gemini 2.0 models in December.
Gemini 2.0 Flash Thinking (1219 release) and Gemini 2.0 Advanced (1206 release) models are both multimodal and ranked the best AI models overall, topping the Chatbot Arena leaderboards.

Prediction: OpenAI will release GPT 4.5 in the first half of 2024, and it will be a fully native multi-modal frontier AI model. – PARTLY TRUE.
In May 2024, OpenAI released GPT-4o, the omni-modal version of GPT-4. They demonstrated advanced voice mode with a “Her”-like voice, which generated hype and even a lawsuit from Scarlett Johannson. Although it took a while to release and they pulled back on some capabilities, the GTP-4o voice-enabled chat app has been a game-changer, enabling users to speak naturally and fluently with an AI model.
The two leading Frontier AI models GPT-4 turbo and Gemini Ultra are now multi-modal, and you can expect all future frontier AI models to be natively multi-modal with text, vision, and audio.
While not every leading AI model release has been multi-modal, there are still text-only LLMs, multimodality for a frontier AI model has gone from a bleeding-edge feature to table stakes.
Notable multi-modal LLM releases include:
The Llama 3.2 multimodal LLM family, with 11B and 90B parameter models that enhanced Llama 3.1 8B and 70B based LLMs with vision capabilities.
Qwen2-VL was released in August and touted SOTA understanding of images and ability to understand long-form video of over 20 minutes. More recently, Qwen QVQ 72B combines vision with reasoning.
Grok 2 from xAI, released in August, excels in vision-based tasks, scoring highly on MMMU and DocVQA.
Conclusion
In all areas relating to vision, image, video, voice and music, AI models have advanced from promise to reality and from toy to useful tool. The useful applications in these categories exploded as quality of AI model results advanced. With better vision understanding combined with reasoning, multimodal LLMs are expanding the use cases for AI models.
In 2025, multi-modal AI model features will improve, expand their abilities, and evolve into AI world models. AI world models understand both sight and sound modalities in the world and can interact with it fully. With sufficient reasoning, these models will become the basis for embodied AI models and applications, used for example in robotics, applications such as presented in Project Astra.
The top three improvement trends for AI models in 2024 have been reasoning, multimodality, and efficiency. We have covered advances in AI reasoning in prior articles and multimodality in this one. We will cover AI improvements in efficiency in our next article in this series.
One part of our prediction that did not come true was OpenAI releasing an expected update to GPT-4 base model, a GPT 4.5 if not a GPT-5. OpenAI made GPT-4 more useful with multi-modality and enhanced AI reasoning using test-time compute, but the expected big leap in base AI model pre-training failed to arrive in 2024. Why? This is also a topic for our next installment.
nice article. Which companies do you think will still need to train on large datasets of image, video and audio in 2025?